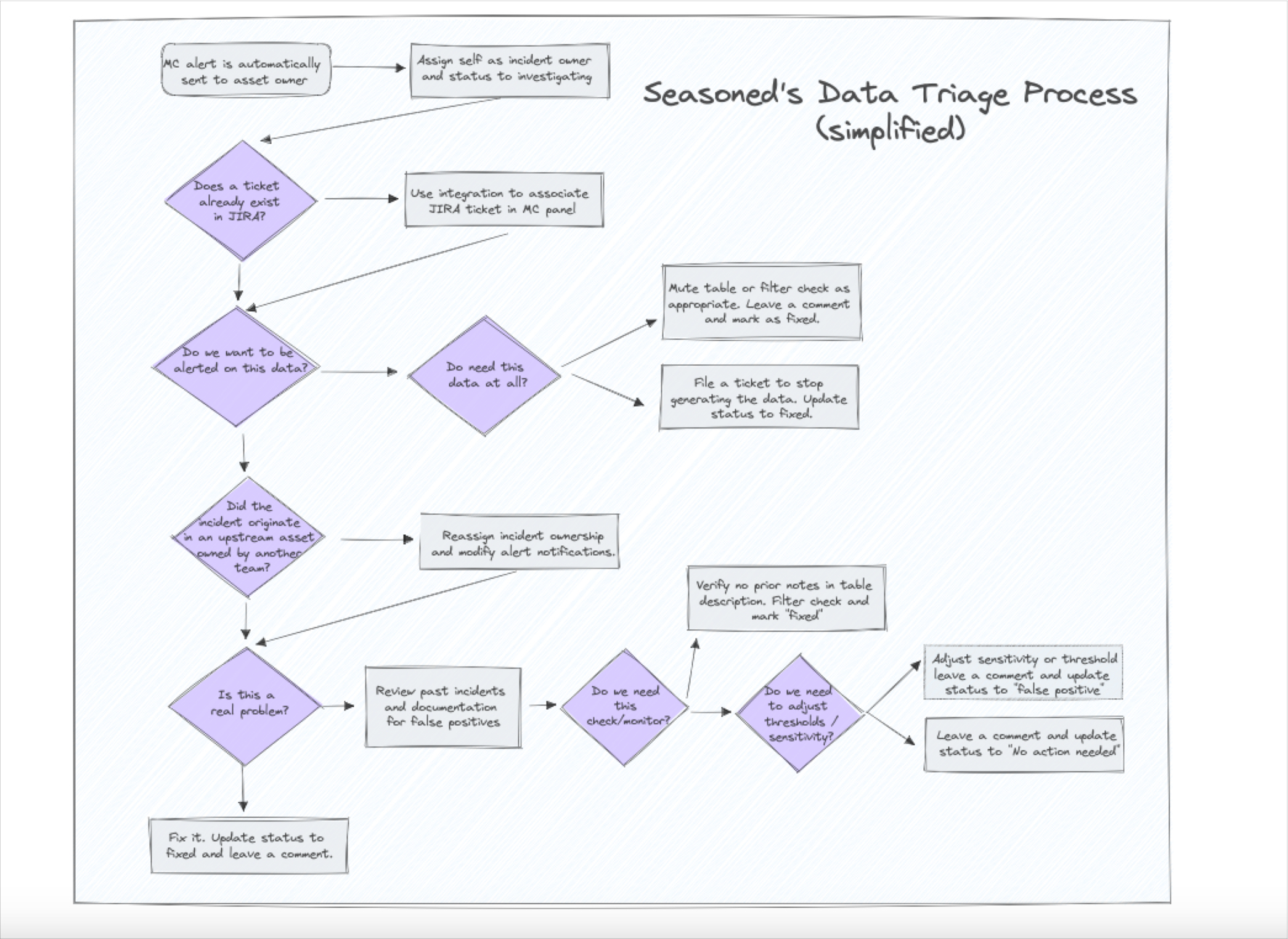
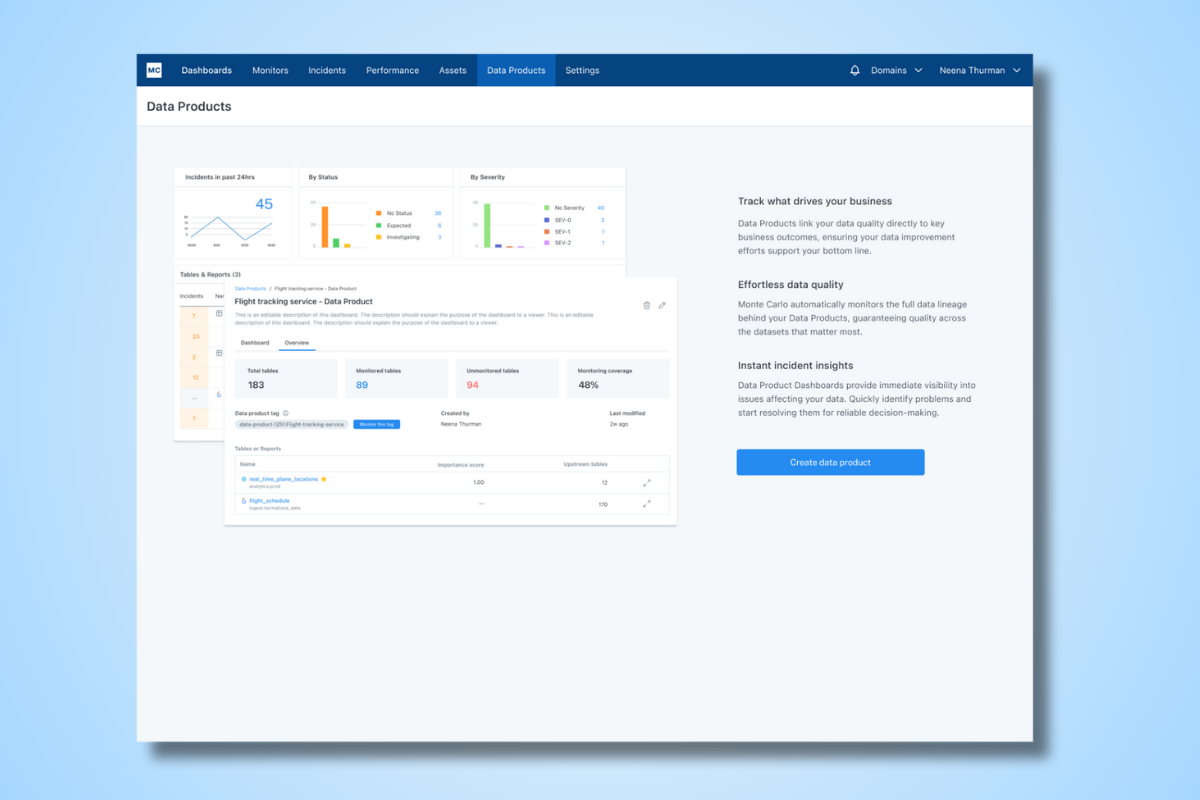
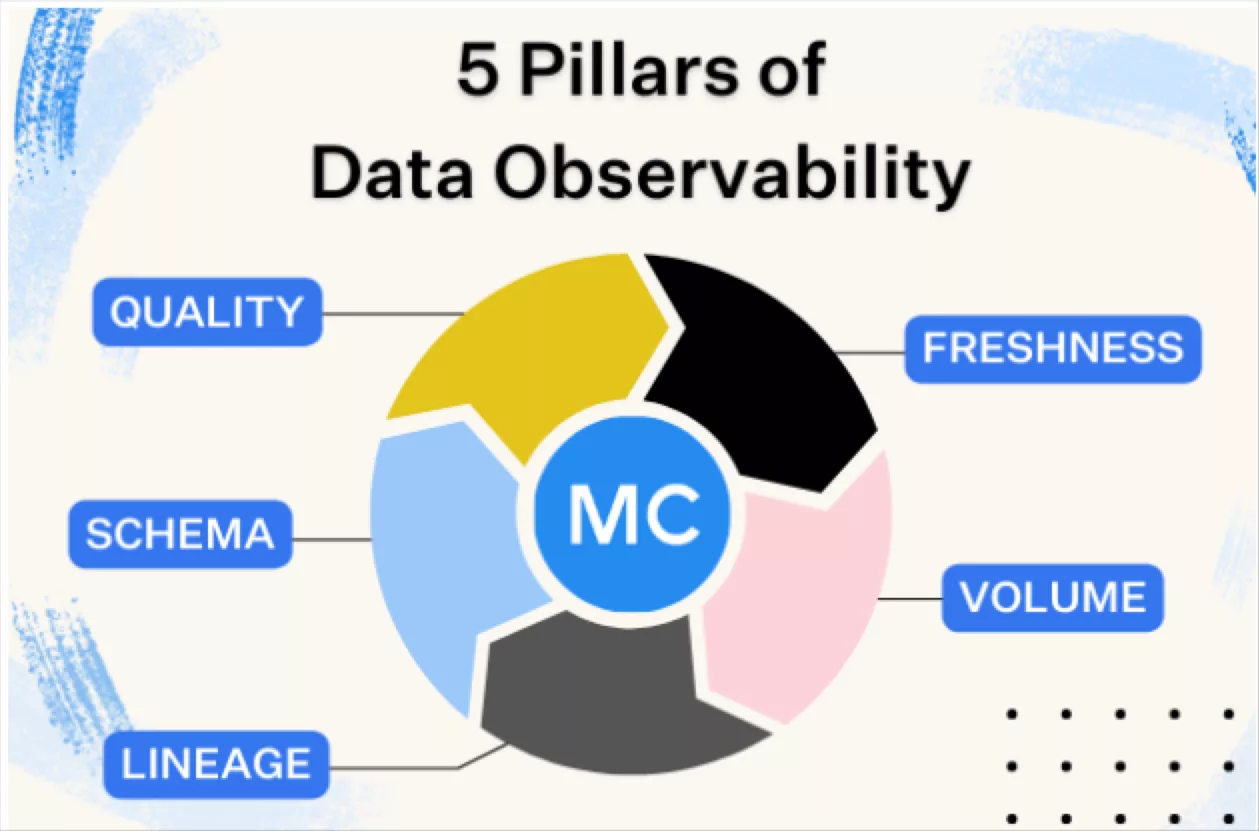
Product demo.
Product demo.  What is a data mesh--and how not to mesh it up
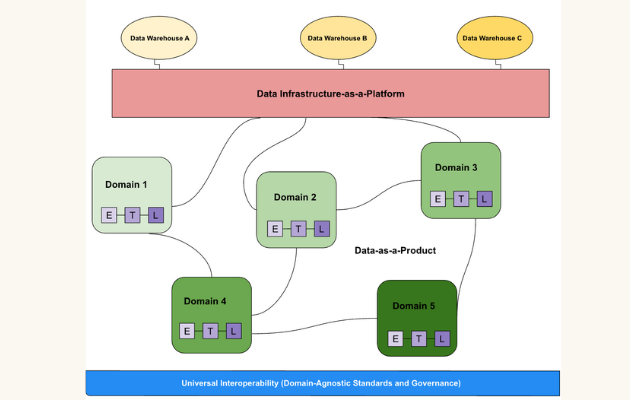
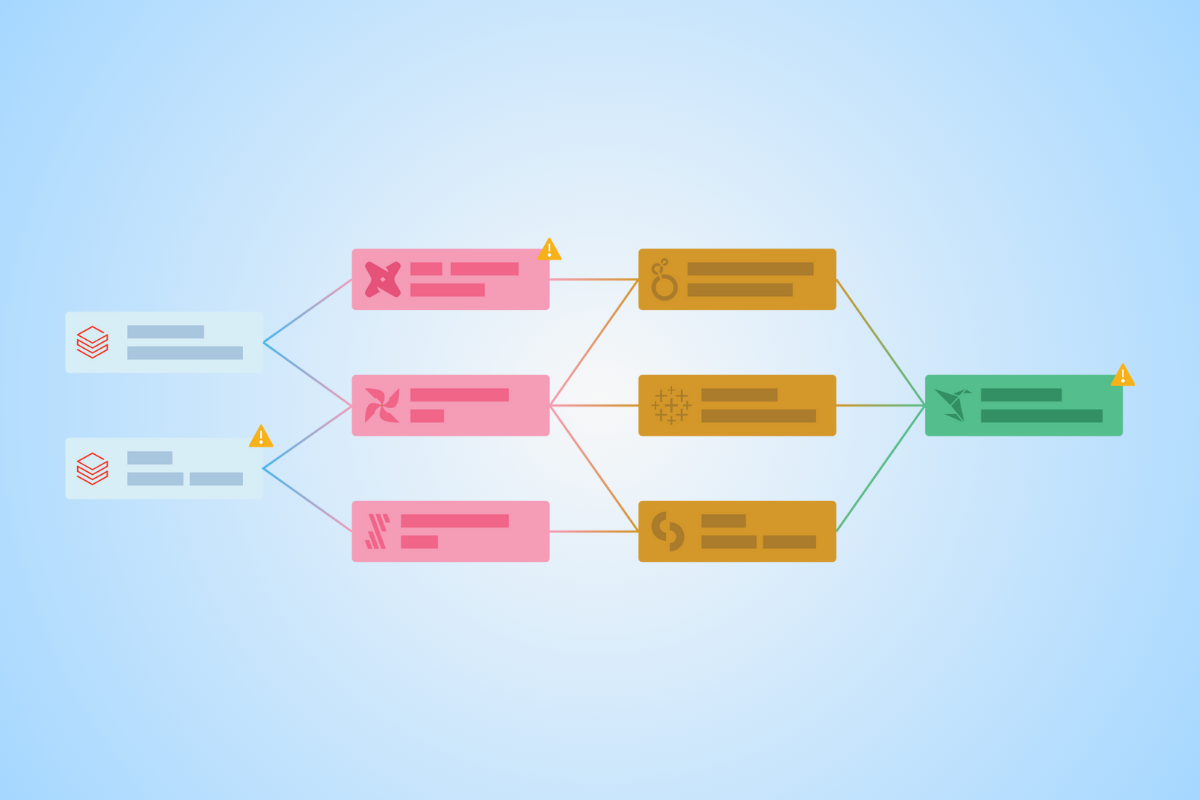
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
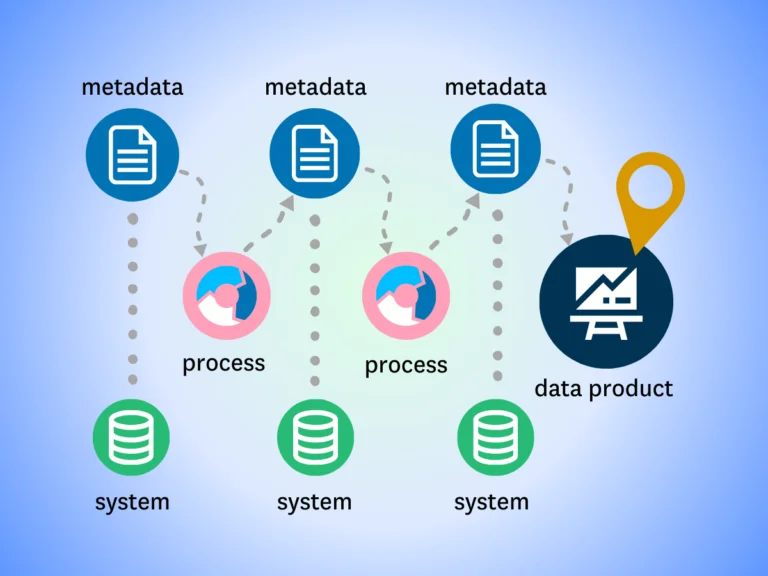
The ULTIMATE Guide To Data Lineage How to Treat Your Data As a Product
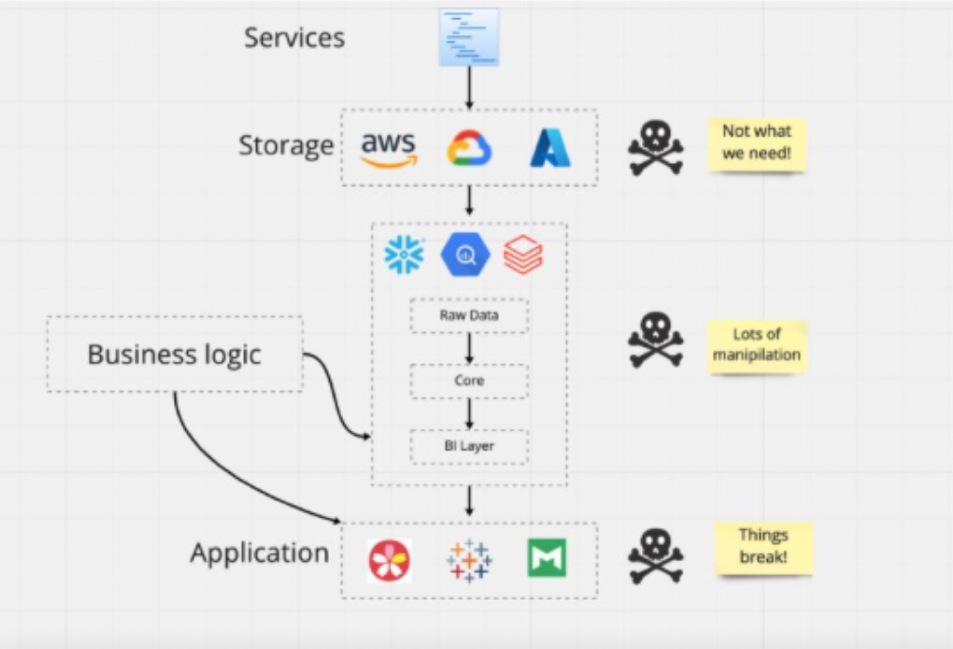
Your company wants to “treat data like a product.” Great! What does that mean?
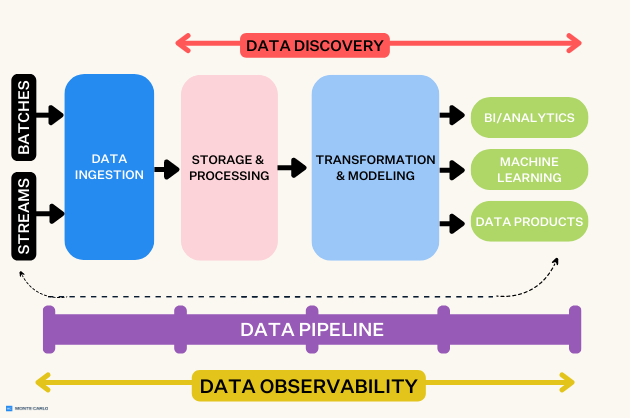
The latest trends and news in data observability.
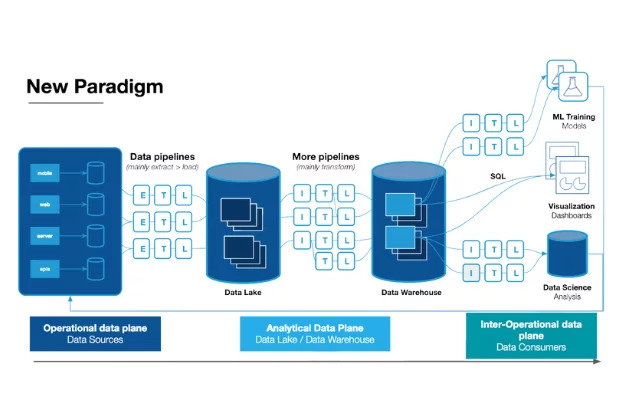
Your company wants to “treat data like a product.” Great! What does that mean?