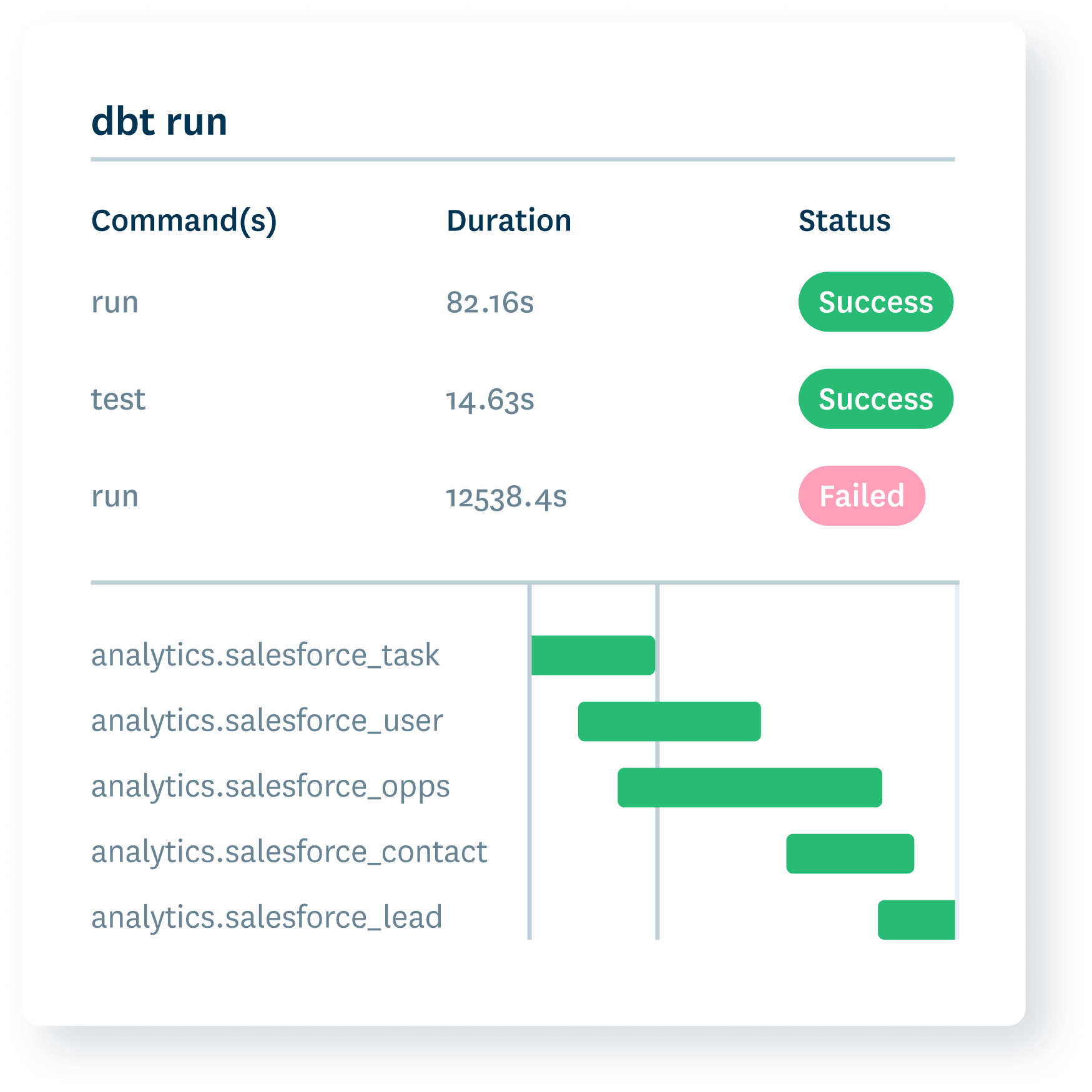
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Why do I need it?

80% Less Data Downtime

30% Time Saved
70% More Data Quality Coverage
Smarter data reliability
Data rarely breaks the way we expect. Don’t define what data should be. Gain full visibility into your data, systems, and code to see what is.
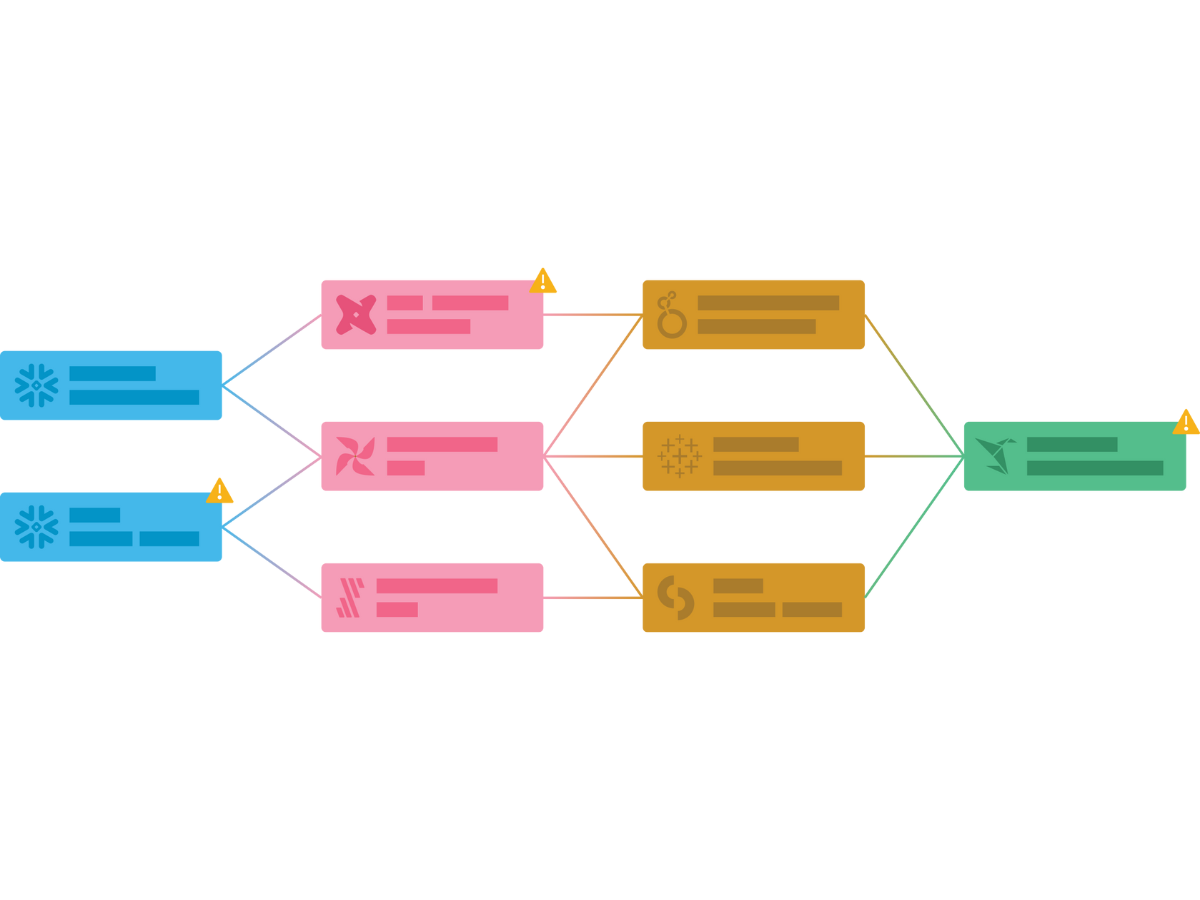
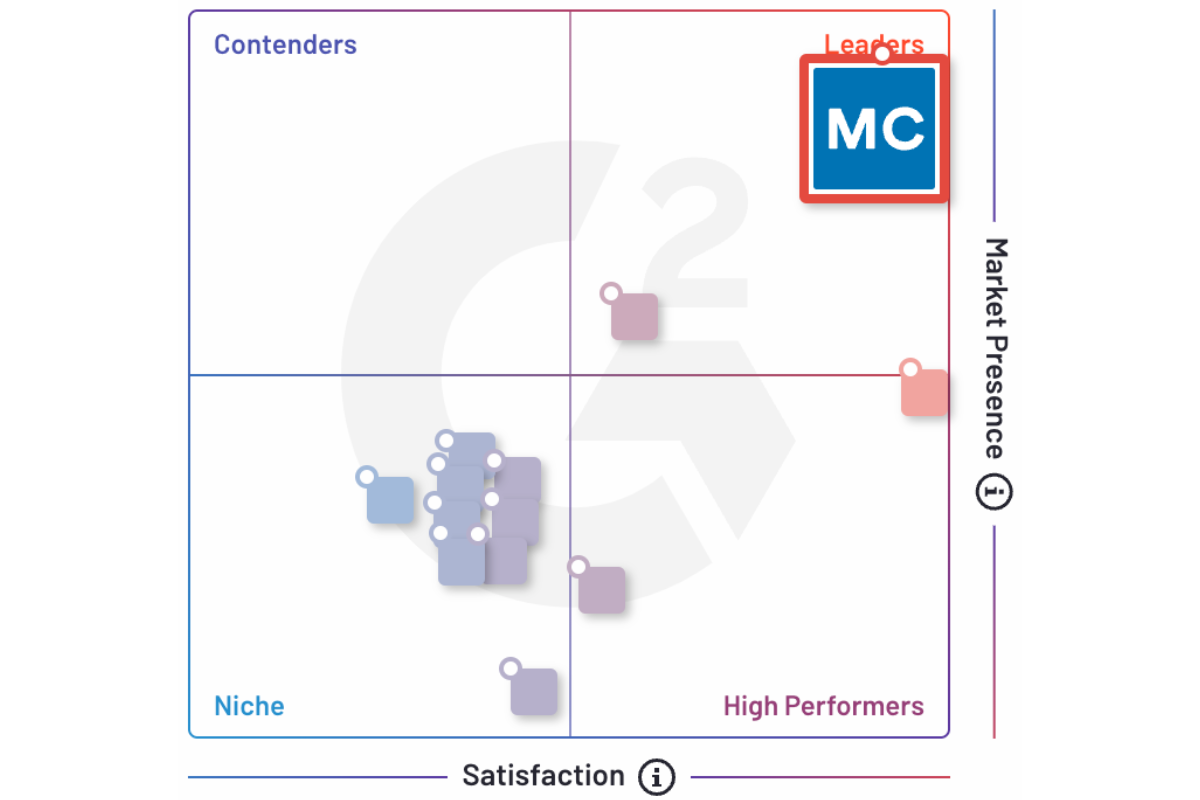
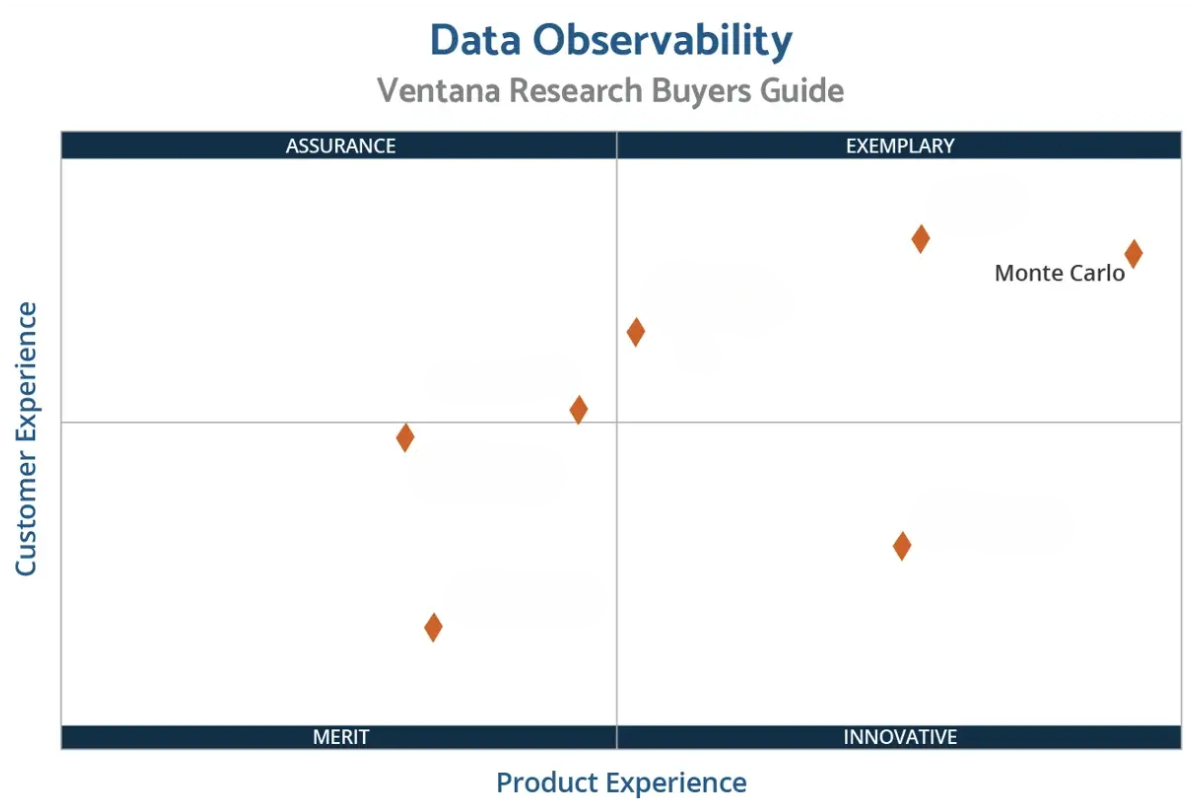
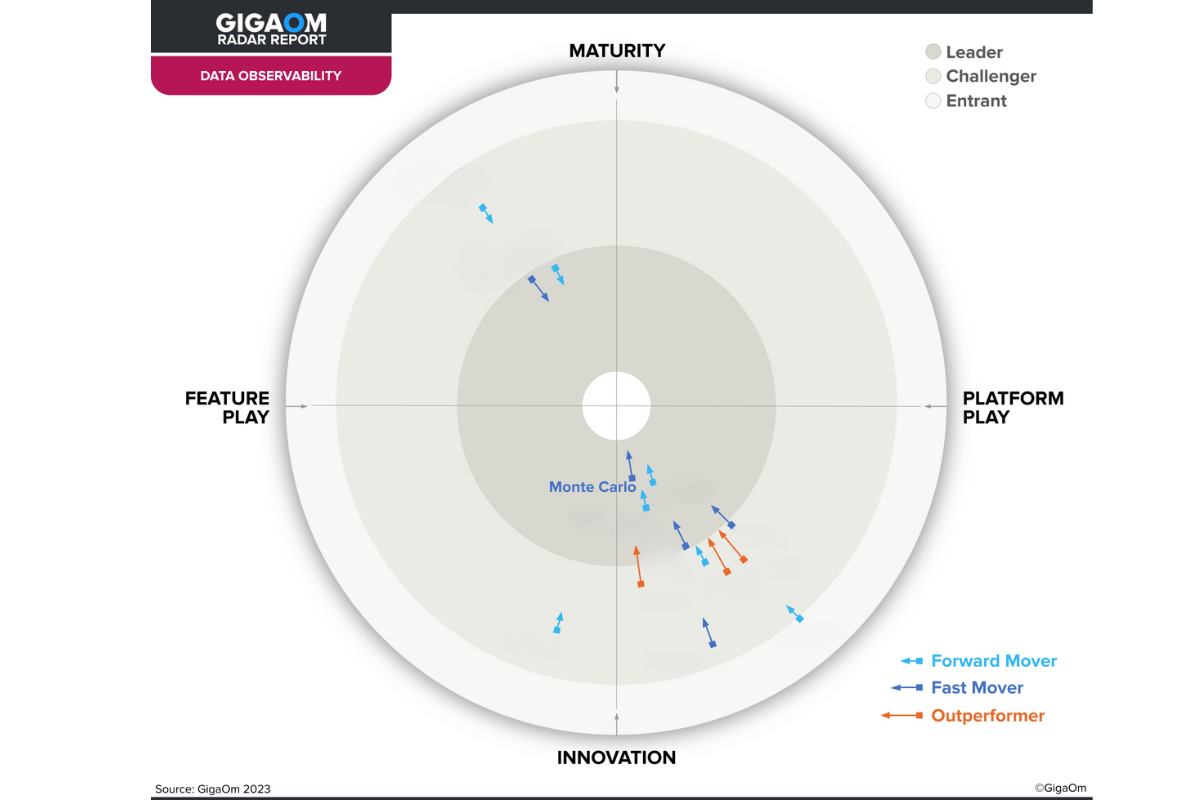
The Undisputed Leader
-
“Monte Carlo is a tool that is easy to implement, use, and drive value through for users across our organization. In our case, we started seeing value during the first week …and have continued to generate more value since!”
-
“Monte Carlo performed best in Customer Experience with an A- grade, notably in TCO/ROI, receiving an A due to its articulation of strategic values and tools to help customers calculate costs. In Usability, intelligence and user experience are strengths.”
-
“The platform’s diverse compilation of source connections, low-code user interface, ML monitoring capabilities, strong data pipeline support, and data catalog make this an extremely well-rounded offering out the gate.”
Find it
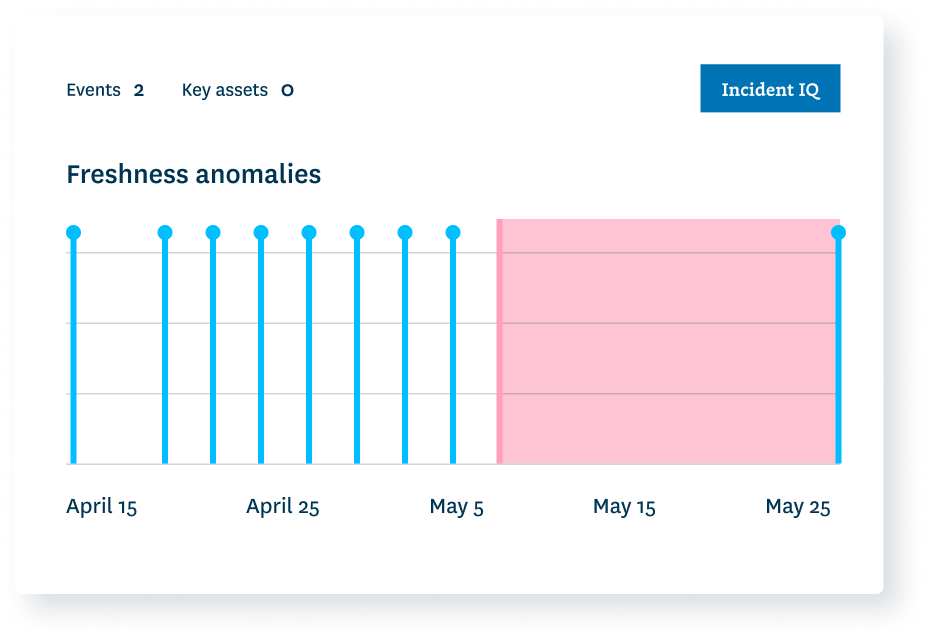
Automated machine learning monitors. No code, no guesswork, no oversights.
- Scale anomaly detection across your pipelines automatically.
- Deploy deep quality monitors with +50 metrics.
- Build custom rules for unique business logic.
- Ensure consistency across tables and databases.
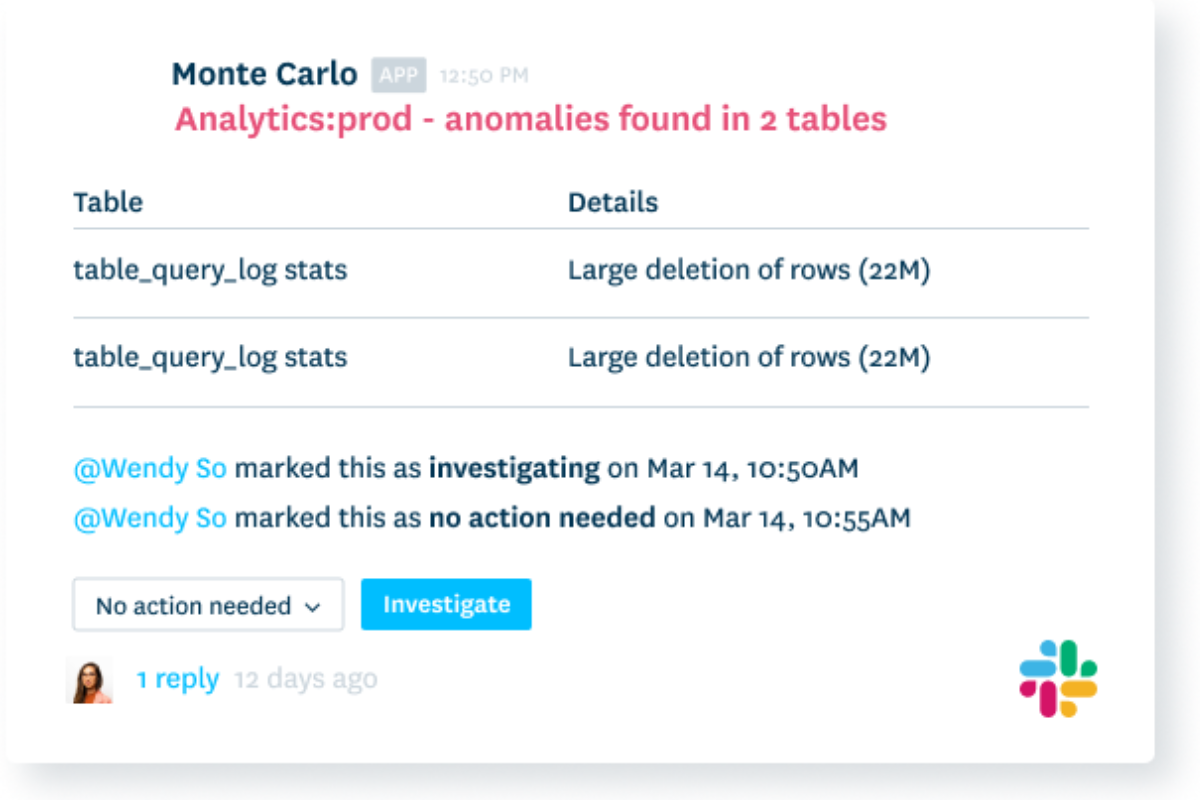
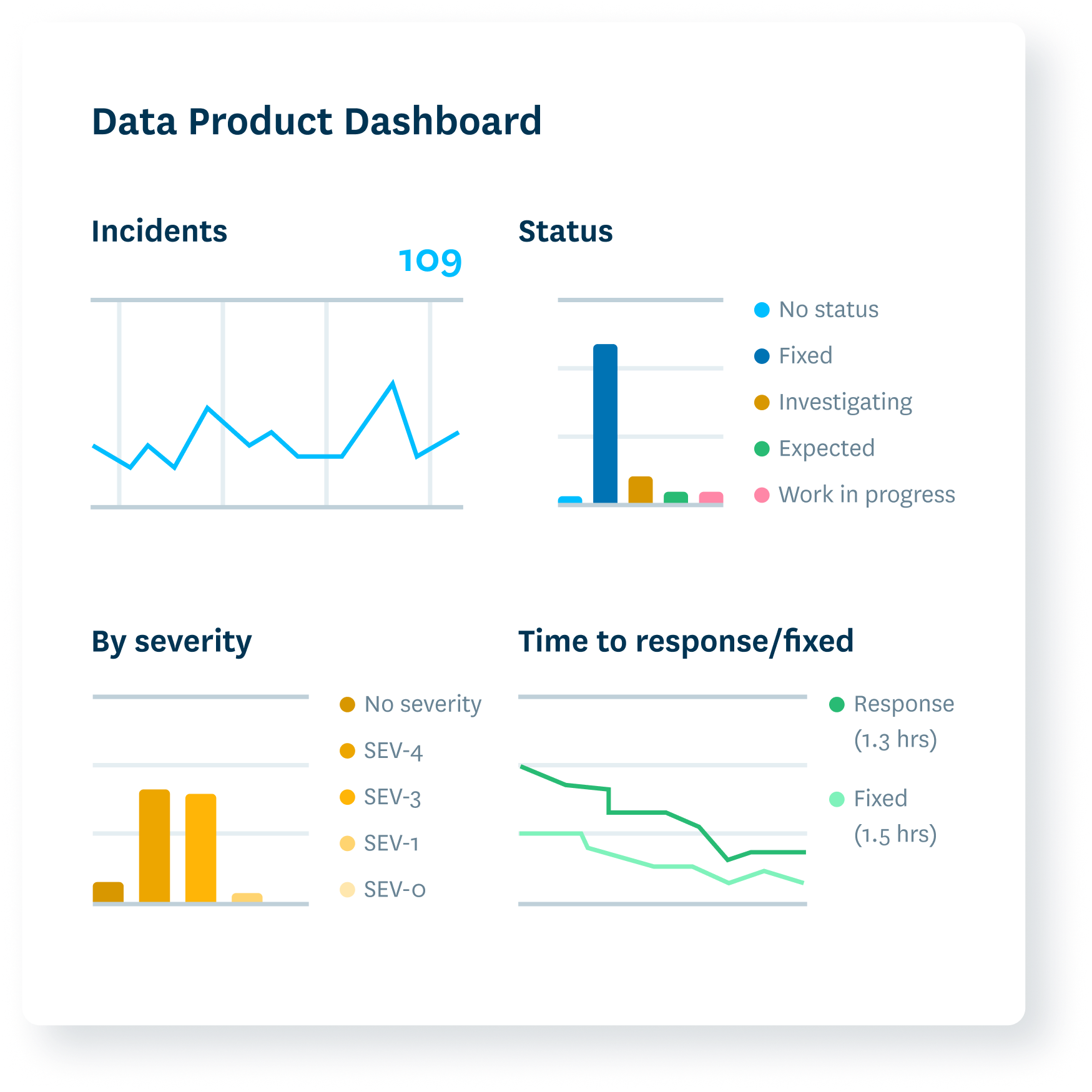
Mitigate it
Transform your incident response from reactive scramble to proactive service.
- Enhance focus with automated impact analysis.
- Get actionable alerts to the right team.
- Track incident tickets, severity, and status.
- Display data product SLAs and health status.
Fix it
+1,000 incidents are resolved in Monte Carlo every day.
- Understand where incidents originated with cross-system data lineage.
- Zero in on bad source data with automated segmentation analysis.
- Discover system failures with metadata monitoring and incident correlation.
- Surface bad queries and faulty logic with code change insights.
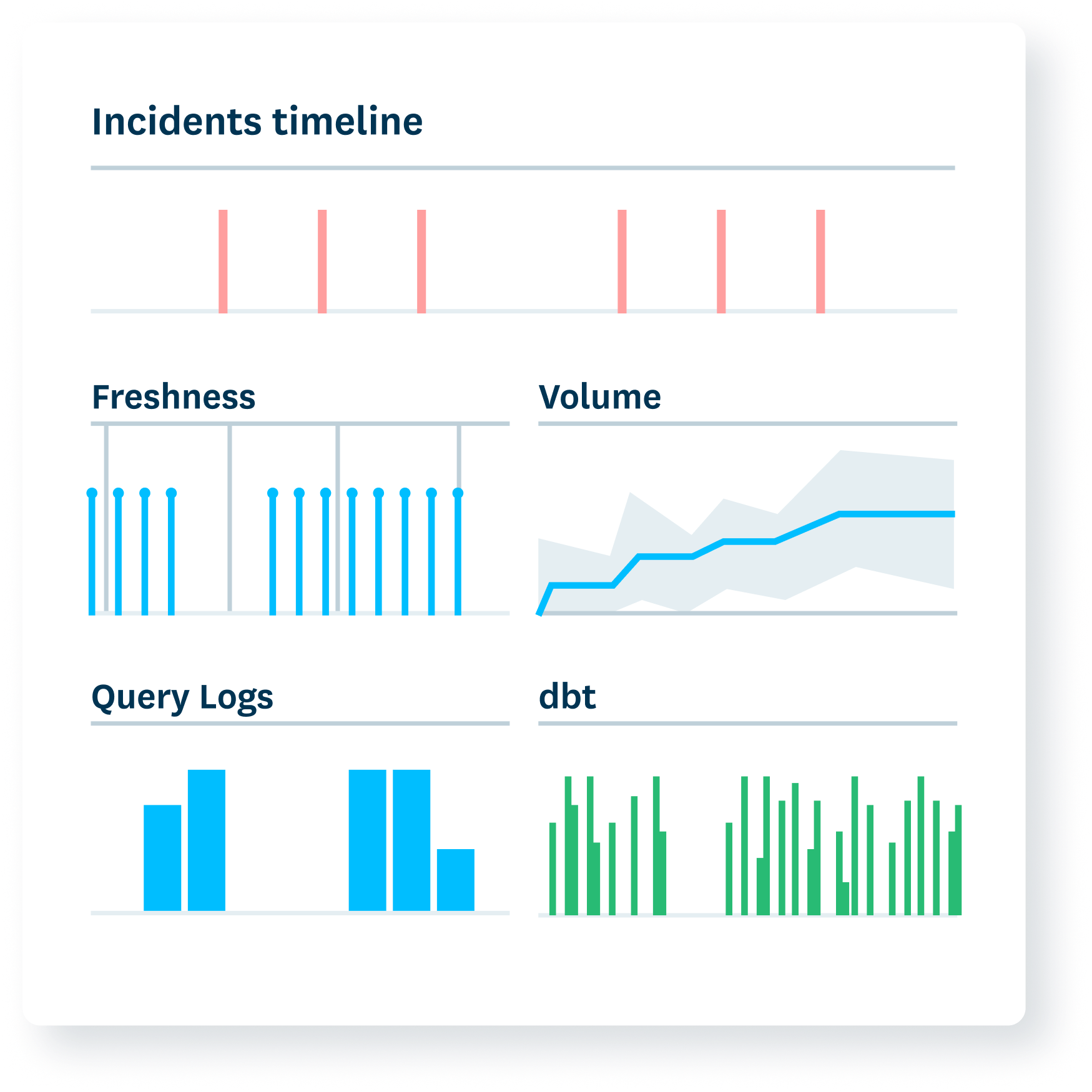
Prove it
Build trust by displaying reliability levels and response times.
- Show how data reliability levels have changed.
- Communicate the current health of key assets.
- Measure your team’s operational response.
- Drill into insights at the data product and table levels.
Optimize it
Reduce cost and runtimes. Identify pipelines that have become inefficient over time.
- Get alerted to queries running longer than normal.
- Uphold performance SLAs. Filter queries related to specific DAGs, users, dbt models, warehouses, datasets and more.
- Spot and remove pipeline bottlenecks.