Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How to Design a Modern, Robust Data Ingestion Architecture


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
A data ingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most.
This involves connecting to multiple data sources, using extract, transform, load (ETL) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.
Let’s see what it takes to design an ingestion architecture that ensures reliable, real-time data processing and supports effective decision-making in big data environments.
Table of Contents
Components of a Typical Data Ingestion Architecture
The data ingestion process looks something like this:
- Data Sources Identification: Identify and catalog various data sources, whether structured (databases), semi-structured (JSON, XML files), or unstructured (videos, images). Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process.
- Data Extraction: Begin extraction using methods such as API calls or SQL queries. Batch processing gathers large datasets at scheduled intervals, ideal for operations like end-of-day reports. Conversely, stream processing continuously collects data in real-time, enabling immediate analytics.
- Data Transformation: Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
- Data Loading: Load transformed data into the target system, such as a data warehouse or data lake. In batch processing, this occurs at scheduled intervals, whereas real-time processing involves continuous loading, maintaining up-to-date data availability.
- Data Validation: Perform quality checks to ensure the data meets quality and accuracy standards, guaranteeing its reliability for subsequent analysis.
- Data Storage: Store validated data in a structured format, facilitating easy access for analysis.
- Data Analysis and Visualization: Query stored data to extract insights and generate reports. Visualize data through charts and graphs and compile reports for stakeholders.
By following these steps, businesses efficiently transform chaotic information influxes into well-organized data pipelines, ensuring effective data utilization.

Popular Data Ingestion Tools
Choosing the right ingestion technology is key to a successful architecture.
Common Tools
- Data Sources Identification with Apache NiFi: Automates data flow, handling structured and unstructured data. Used for identifying and cataloging data sources.
- Data Storage with Apache HBase: Provides scalable, high-performance storage for structured and semi-structured data.
- Data Analysis and Visualization with Apache Superset: Data exploration and visualization platform for creating interactive dashboards.
Batch Processing Tools
For batch processing, tools like Apache Hadoop and Spark are widely used. Hadoop handles large-scale data storage and processing, while Spark offers fast in-memory computing capabilities for further processing.
- Data Extraction with Apache Hadoop and Apache Sqoop: Hadoop’s distributed file system (HDFS) stores large data volumes; Sqoop transfers data between Hadoop and relational databases.
- Data Transformation with Apache Spark: In-memory data processing for rapid cleaning and transformation.
- Data Loading with Apache Hadoop and Apache Sqoop: Hadoop stores processed data; Sqoop loads it back into relational databases if needed.
Real-Time Processing Tools
For real-time data ingestion architectures, Apache Kafka and Flink are common choices. Kafka manages high-throughput, low-latency data streaming, while Flink excels in processing these data streams with complex event-driven computations.
- Data Extraction with Apache Kafka, Apache Flume: Kafka manages high-throughput data streams; Flume collects and transports log data.
- Data Transformation with Apache Flink: Stream processing framework for continuous data transformations and real-time analytics.
- Data Loading: Real-time systems like Flink integrate directly with data storage for continuous availability.
These tools, along with a data observability platform such as Monte Carlo for ensuring data quality, form the backbone of modern big data ingestion architectures. Major cloud vendors also offer their own scalable solutions, ensuring efficient and reliable data flow across various applications and platforms.
Case Study: Big Data Ingestion Example
Scenario Overview
A leading e-commerce company in the retail industry faced the challenge of efficiently processing and analyzing vast amounts of data from customer transactions, website interactions, social media, and supply chain operations. This was crucial for enhancing data-driven decision-making and maintaining competitiveness.
Ingestion Pipeline Design
The company designed a robust data ingestion pipeline consisting of the following key components:
- Data Sources Identification: Apache NiFi was used to connect to various data sources, automating data flows between different systems.
- Data Extraction: Apache Hadoop’s HDFS stored large volumes of raw data, while Apache Sqoop efficiently transferred data between Hadoop and relational databases.
- Data Transformation: Apache Spark enabled fast, in-memory processing to clean, normalize, and enrich the extracted data.
- Data Loading: Apache Hadoop and Apache Sqoop imported the transformed data into Hadoop’s HDFS for further processing.
- Data Storage: Apache HBase provided scalable and high-performance storage for large amounts of structured and semi-structured data.
- Data Analysis and Visualization: Apache Superset was used to create interactive dashboards and reports, offering real-time insights into customer behavior, sales trends, and supply chain efficiency.
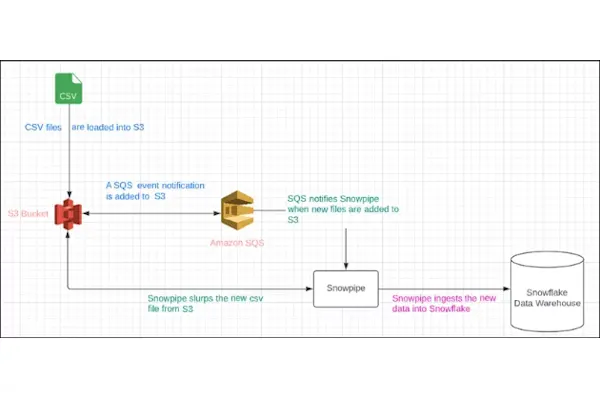
The full data ingestion architecture diagram can be seen here:

Results and Benefits
This batch processing big data ingestion architecture significantly improved the company’s analytics capabilities. The company gained comprehensive visibility into customer behavior, enabling personalized marketing strategies. Supply chain operations became more efficient, reducing stockouts and improving delivery times. Overall, the architecture empowered the company to make more informed, data-driven decisions, enhancing their competitive edge in the market.
Case Study: Real-Time Ingestion Example
Scenario Overview
A financial services company aimed to enhance its fraud detection system by implementing a real-time data ingestion architecture. The goal was to process vast amounts of data from customer transactions, account activities, and external feeds to identify fraudulent activities promptly.
Ingestion Pipeline Design
The company designed a robust real-time data ingestion pipeline with these key components:
- Data Sources Identification: Apache NiFi connected to various data sources, automating data flows between systems.
- Data Extraction: Apache Kafka and Apache Flume handled real-time streaming data. Kafka’s high throughput and low latency capabilities ingested data from transactional systems and external feeds, while Flume collected and aggregated log data.
- Data Transformation: Apache Flink performed real-time analytics and anomaly detection, applying complex algorithms to detect fraud patterns dynamically.
- Data Loading: Not applicable, as the real-time processing systems integrate directly into the data storage.
- Data Storage: Apache HBase provided scalable, high-performance storage for real-time data, ensuring immediate availability for analysis.
- Data Analysis and Visualization: Apache Superset created interactive dashboards and reports, offering real-time insights into transactional data and fraud detection metrics.
The full data ingestion architecture diagram can be seen here:

Results and Benefits
The real-time data ingestion architecture significantly improved the company’s fraud detection system. Suspicious activities were identified within seconds, reducing response time and potential losses. The company also achieved improved data accuracy and consistency, leading to better decision-making. This implementation bolstered security measures and strengthened customer trust by providing a more secure transactional environment.
Common Challenges (and Solutions) in Data Ingestion
Handling Large Volumes and High Velocity of Data
Challenge: The sheer volume and high velocity of data can overwhelm systems, leading to delays and potential data loss.
Solution: Utilize scalable tools like Apache Kafka to manage data flow efficiently.
Protecting Sensitive Data During Ingestion
Challenge: Ensuring data security and privacy during ingestion is challenging due to risks of breaches, unauthorized access, and the need to comply with privacy regulations.
Solution: Use strong encryption and access controls, and anonymize private data to protect personally identifiable information and ensure regulatory compliance.
Managing Data Variety, Complexity, and Quality
Challenge: Diverse data formats and sources add complexity, and maintaining data quality is critical, as inconsistencies and errors can propagate through the system, affecting analytics and decision-making.
Solution: Implement robust data quality checks to ensure accuracy and consistency, and continuous monitoring using platforms like Monte Carlo to detect and resolve anomalies as soon as they occur.
Scalability and Quality Checks are Key to Data Ingestion Success
Without proper data ingestion architecture, I often see solutions that are hard to maintain, extend, or scale. As complexity grows, side effects and bugs slow down decision-making from the ingested data if the foundation is bad.
By leveraging scalable tools and implementing robust data quality checks, businesses can ensure seamless and reliable data flow. Adopting comprehensive data quality solutions like Monte Carlo’s data observability platform can significantly enhance your data strategy, ensuring data integrity from ingestion to analysis. Embrace these advanced architectures to gain a competitive edge and transform your data operations.
Our promise: we will show you the product.
Frequently Asked Questions
What is data ingestion architecture?
Data ingestion architecture is the technical blueprint that ensures data is continuously and reliably imported into the system from multiple data sources. It involves processes like data extraction, transformation, and loading (ETL), and uses orchestration tools to manage the data flow, making data readily available for analysis and decision-making.
What is real-time data ingestion architecture?
Real-time data ingestion architecture involves continuously collecting, transforming, and loading data as it is generated. This enables immediate analytics and ensures that data is up-to-date. Tools like Apache Kafka and Apache Flink are commonly used for managing high-throughput, low-latency data streaming and processing in real-time ingestion architectures.
What is the function of the ingestion layer in the big data architecture?
The ingestion layer in the big data architecture is responsible for identifying and cataloging various data sources, extracting data using methods like API calls or SQL queries, transforming the data to ensure consistency and usability, loading the data into target systems like data warehouses or lakes, validating the data for quality and accuracy, and storing it in a structured format for easy access and analysis.
Read more posts.