Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How to Build a 5-Layer Modern Data Stack (with Example Tools)

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Building a modern data stack doesn’t have to be complicated. Here’s what data leaders say are the 5 must-have layers of your data platform to drive data adoption – and ROI – across your business.
Like bean dip and ogres, layers are the building blocks of the modern data stack.
Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the data pipeline.
Unlike ogres, however, the cloud data platform isn’t a fairy tale. New tooling and integrations are created almost daily in an effort to augment and elevate it.
So, with infinitely expanding integrations and the opportunity to add new layers for every feature and function of your data motion, the question arises—where do you start? Or to put it a different way, how do you deliver a data platform that drives real value for stakeholders without building a platform that’s either too complex to manage or too expensive to justify?
For small data teams building their first cloud-native platforms and teams making the jump from on-prem for the first time, it’s essential to bias those layers that will have the most immediate impact on business outcomes.
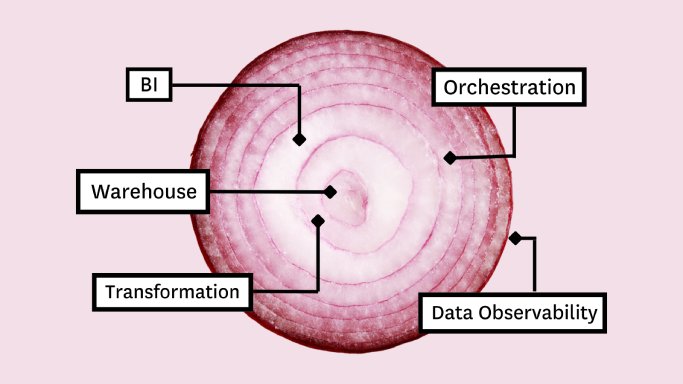
In this article, we’ll present you with the Five Layer Modern Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Those tools include:
Table of Contents
And we won’t mention ogres or bean dip again.
Let’s dive into it. (The content, not the bean dip. Okay, that’s really the last time.)
Cloud storage and compute
Whether you’re stacking data tools or pancakes, you always build from the bottom up. Like any good stack, an appropriate foundation is critical to ensuring the structural and functional integrity of your data platform.
Before you can model the data for your stakeholders, you need a place to collect and store it. The first layer of your stack will generally fall into one of three categories: a data warehouse solution like Snowflake that handles predominantly structured data; a data lake that focuses on larger volumes of unstructured data; and a hybrid solution like Databricks’ Lakehouse that combines elements of both.
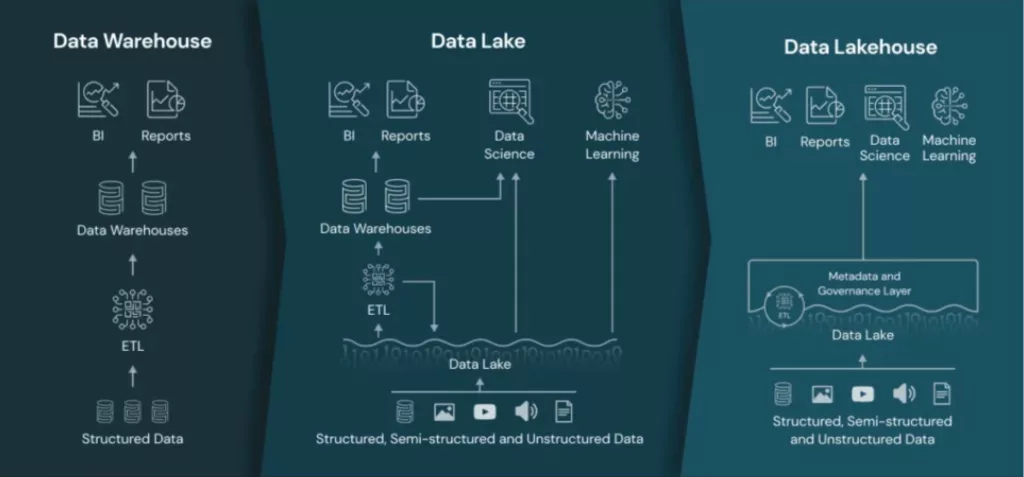
However, this won’t simply be where you store your data—it’s also the power to activate it. In the modern data stack, your storage solution is the primary source of compute power for the other layers of your platform. (Read more on when it makes sense to couple or decouple your storage and compute via my colleague Shane).
Now, I could get into the merits of the warehouse, the lake, the lakehouse, and everything in between, but that’s not really what’s important here. What is important is that you select a solution that meets both the current and future needs of your platform at a resource cost that’s amenable to your finance team. It will also dictate what tools and solutions you’ll be able to connect in the future to fine-tune your modern data stack for new use cases.
What specific storage and compute solution you need will depend entirely on your business needs and use-case, but our recommendation is to choose something common—Snowflake, Databricks, BigQuery, etc—that’s well supported, well-integrated, and easy to scale.
Open-source is always a tempting solution, but unless you’ve reached a level of scale that actually necessitates it, it can present some major challenges for scaling at the storage and compute level. Take our word for it, choosing a managed storage and compute solution at the outset will save you a lot of headache—and likely a painful migration—down the line.

For more thoughts on choosing a solution, check out our blog on building or buying your storage and compute layer.
Data transformation
Okay, so your data needs to live in the cloud. Makes sense. What else does your data platform need? Let’s look at layer two of the Five Layer Modern Data Stack—transformation.
When data is first ingested, it comes in all sorts of fun shapes and sizes. Different formats. Different structures. Different values. In simple terms, data transformation refers to the process of converting all that data from a variety of disparate formats into something consistent and useful for modeling.
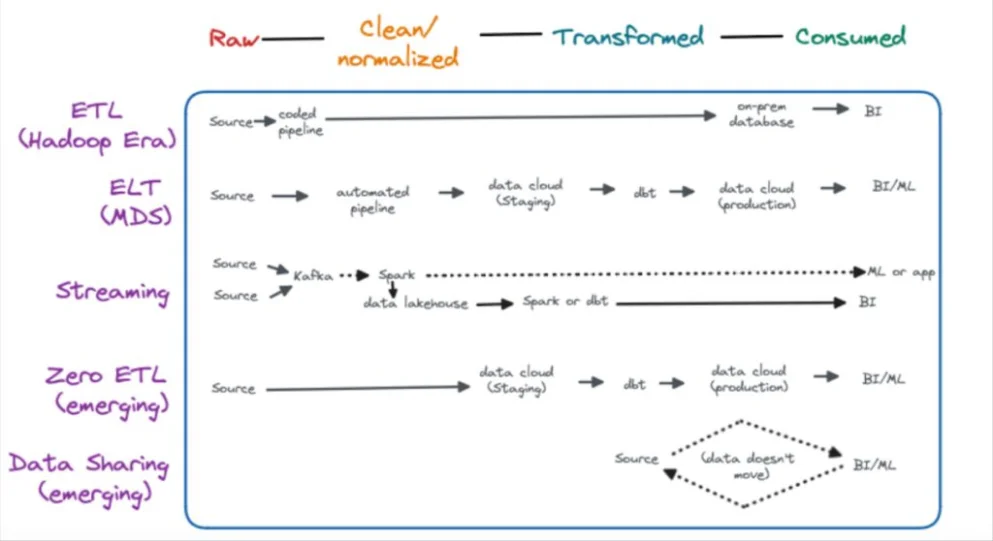
Traditionally, transformation was a manual process, requiring data engineers to hard-code each pipeline by hand within a CLI.
Recently, however, cloud transformation tools have begun to democratize the data modeling process. In an effort to make data pipelines more accessible for practitioners, automated data pipeline tools like dbt Labs, Preql, and Dataform allow users to create effective models without writing any code at all.
Tools like dbt rely on what’s known as “modular SQL” to build pipelines from common, pre-written, and optimized plug-and-play blocks of SQL code.
As you begin your cloud data journey, you’ll quickly discover new ways to model the data and provide value to data consumers. You’ll field new dashboard requests from finance and marketing. You’ll find new sources that need to be introduced to existing models. The opportunities will come fast and furious.
Like many layers of the modern data stack, coding your own transforms can work on a small scale. Unfortunately, as you begin to grow, manually coding transforms will quickly become a bottleneck to your data platform’s success. Investing in out-of-the-box operationalized tooling is often necessary to remaining competitive and continuing to provide new value across domains.
But, it’s not just writing your transforms that gets cumbersome. Even if you could code enough transforms to cover your scaling use-cases, what happens if those transforms break? Fixing one broken model is probably no big deal, but fixing 100 is a pipe dream (pun obviously intended).
Improved time-to-value for scaling organizations
Transformation tools like dbt make creating and managing complex models faster and more reliable for expanding engineering and practitioner teams. Unlike manual SQL coding which is generally limited to data engineers, dbt’s modular SQL makes it possible for anyone familiar with SQL to create their own data pipelines. This means faster time to value for busy teams, reduced engineering drain, and, in some cases, a reduced demand on expertise to drive your platform forward.
Flexibility to experiment with transformation sequencing
An automated cloud transformation layer also allows for data transforms to take place at different stages of the pipeline, offering the flexibility to experiment with ETL, ELT, and everything in between as your platform evolves.
Enables self-service capabilities
Finally, an operationalized transform tool will pave the road for a fully self-service architecture in the future—should you choose to travel it.
Business Intelligence (BI)
If transformation is layer two, then business intelligence has to be layer three.
Business intelligence in the context of data platform tooling refers to the analytical capabilities we present to end-users to fulfill a given use-case. While our data may feed some external products, business intelligence functions are the primary data product for most teams.
While business intelligence tools like Looker, Tableau, and a variety of open-source tools can vary wildly in complexity, ease of use, and feature-sets, what these tools always share is an ability to help data consumers uncover insights through visualization.
This one’s gonna be pretty self-explanatory because while everything else in your stack is a means to an end, business intelligence is often the end itself.
Business intelligence is generally the consumable product at the heart of a modern data stack, and it’s an essential value driver for any cloud data platform. As your company’s appetite to create and consume data grows, the need to access that data quickly and easily will grow right along with it.
Business intelligence tooling is what makes it possible for your stakeholders to derive value from your data platform. Without a way to activate and consume the data, there would be no need for a cloud data platform at all—no matter how many layers it had.
Data observability
The average data engineering team spends roughly two days per week firefighting bad data. In fact, according to a recent survey by Gartner, bad data costs organizations an average of $12.9 million per year. To mitigate all that financial risk and protect the integrity of your platform, you need layer four: data observability.
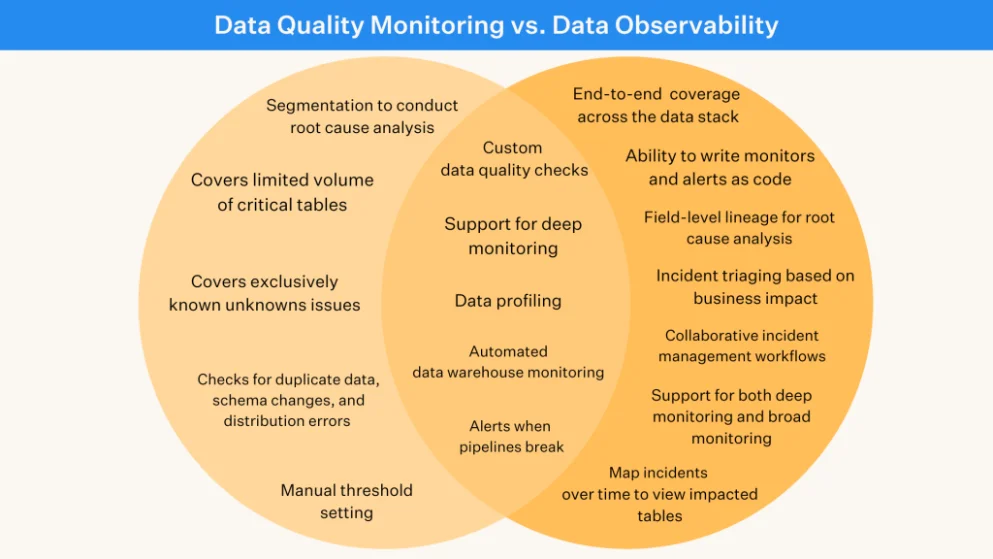
Before data observability, one of the most common ways to discover data quality issues was through manual SQL tests. Open source data testing tools like Great Expectations and dbt enabled data engineers to validate their organization’s assumptions about the data and write logic to prevent the issue from working its way downstream.
Like much of the innovation that’s taken place in the modern data stack, Data Observability was designed to improve efficiency and impact for overworked data teams.
Instead of manual coding, data observability platforms use machine learning to automatically generate quality checks for things like freshness, volume, schema, and null rates across your full suite of production tables. In addition to comprehensive quality coverage, a good data observability solution will also generate both table and column-level lineage to help teams quickly identify where a break happened and what’s been impacted based on upstream and downstream dependencies.
The value of your modern data stack—and by extension its products—is inextricably tied to the quality of the data that feeds it. Garbage in, garbage out. (Or nothing out if you’ve got a broken ingestion job.) To have reliable, actionable, and useful data products, the underlying data has to be trustworthy. If you can’t trust the data, you can’t trust the data product.
Unfortunately, as your data grows, your data quality issues will grow right along with it. The more complex your modern data stack becomes, the more sources you ingest, the more teams you support—the more quality incidents you’re likely to have. And as teams increasingly leverage data to power AI models and ML use cases, the need to ensure its trust and reliability grows exponentially.
While data testing can provide some quality coverage, its function is limited to known issues and specific tables. And because each manual test needs to be coded by hand, scalability is only proportionate to your available engineering resources. Data observability, on the other hand, provides plug-and-play coverage across every table automatically, so you’ll be alerted to any data quality incident—known or unknown—before it impacts downstream consumers. And as your platform and your data scale, your quality coverage will scale along with it.
Plus, on top of automated coverage, most data observability tools offer end-to-end lineage down to the BI layer, which makes it possible to actually root cause and resolve quality incidents. That can mean hours of time recovered for your data team. While traditional manual testing may be able to catch a portion of quality incidents, it’s useless to help you resolve them. That’s even more alarming when you realize that time-to-resolution has nearly doubled for data teams year-over-year.
Unlike data testing which is reactionary by nature, data observability provides proactive visibility into known and unknown issues with a real-time record of your pipeline lineage to position your data platform for growth—all without sacrificing your team’s time or resources.
Data orchestration
When you’re extracting and processing data for analytics, the order of operation matters. As we’ve seen already, your data doesn’t simply exist within the storage layer of your modern data stack. It’s ingested from one source, housed in another, then ferried somewhere else to be transformed and visualized.
In the broadest terms, data orchestration is the configuration of multiple tasks (some may be automated) into a single end-to-end process. It triggers when and how critical jobs will be activated to ensure data flows predictably through your platform at the right time, in the right sequence, and at the appropriate velocity to maintain production standards (Kind of like a conveyor belt for your data products).
Unlike storage or transformation, pipelines don’t require orchestration to be considered functional—at least not at a foundational level. However, once data platforms scale beyond a certain point, managing jobs will quickly become unwieldy by in-house standards.
When you’re extracting and processing a small amount of data, scheduling jobs requires only a small amount of effort. But when you’re extracting and processing very large amounts of data from multiple sources and for countless use cases, scheduling those jobs requires a very large amount of effort—an inhuman amount of effort.
The reason that orchestration is a functional necessity of the 5 Layer Modern Data Stack—if not a literal one—is due to the inherent lack of scalability in hand-coded pipelines. Much like transformation and data quality, engineering resources become the limiting principle for scheduling and managing pipelines.
The beauty of so much of the modern data stack is that it enables tools and integrations that remove engineering bottlenecks, freeing up engineers to provide new value to their organizations. These are the tools that justify themselves. That’s exactly what orchestration does as well.
And as your organization grows and silos naturally begin to develop across your data, having an orchestration layer in place will position your data team to maintain control of your data sources and continue to provide value across domains.
Some of the most popular solutions for data orchestration include Apache Airflow, Dagster, and relative newcomer Prefect.
The most important part? Building for impact and scale
Of course, five isn’t the magic number. A great modern data stack might have six layers, seven layers, or 57 layers. And many of those potential layers—like governance, contracts, and even some additional testing—can be quite useful depending on the stage of your organization and its platform.
However, when you’re just getting started, you don’t have the resources, the time, or even the requisite use cases to boil the Mariana Trench of platform tooling available to the modern data stack. More than that, each new layer will introduce new complexities, new challenges, and new costs that will need to be justified. Instead, focus on what matters most to realize the potential of your data and drive company growth in the near term.
Each of the layers mentioned above—storage, transformation, BI, data observability, and orchestration—provides an essential function of any fully operational modern data stack that maximizes impact and provides the immediate scalability you’ll need to rapidly grow your platform, your use cases, and your team in the future.
If you’re a data leader who’s just getting started on their data journey and you want to deliver a lean data platform that limits costs without sacrificing power, the Five Layer Modern Data Stack is the one to beat.
Want to know how Monte Carlo fits into your own five layer modern data stack? Drop your email in the form below to get started on the path to data reliability.
Our promise: we will show you the product.
Read more posts.