Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Don’t Make a Schema Change Before Answering These Five Questions


Scott O'Leary
Scott O'Leary is a founding member of Monte Carlo's Sales team.
As data professionals, it can often seem easier to address problems with new technology instead of actually getting to the source of the problem.
Have too much work on your plate? Try Asana.
Struggling with communication between various departments? Let’s use Slack.
One too many null values in your executive’s dashboards? Spin up some more data tests.
Don’t get us wrong – technology can certainly help solve these problems, and for many teams, it’s hugely important.
However, nine times out of ten, the root of most data issues aren’t technological – they’re process-oriented.
Unexpected schema changes will continue to occur without the right workflows in place to communicate them and the potential impact those changes can have on others downstream.
If our software engineering counterparts can put together an effective system to better manage schema changes (via the DevOps lifecycle), why hasn’t the same happened in data?
Here are the five questions you need to answer before pushing schema changes off to production:
Is a change management process embedded into your data engineering workflow?
What is the structure of your data organization?
What impact up and downstream will the schema change have?
How will you communicate schema changes with the broader data team?
Are you measuring the impact of change management on your organization?
Is a change management process embedded into your data engineering workflow?

As software engineering teams have matured, they’ve developed systems and processes to better manage the inevitable and repeatable change that occurs when deploying new code. Enter the DevOps lifecycle, one of the most effective ways for software development teams to manage schema changes.
The DevOps lifecycle applies a continuous feedback loop to help teams deliver reliable features that align with business objectives, breaking down silos between software engineering teams to speed up application development.
As is the case with most data engineering best practices, data teams should follow suit and begin to treat data like a product.
After talking with hundreds of teams over the past few years, I’ve put together a few best practices for embedding change management into data engineering workflows:
- Train team members on the consequences of not managing schema changes properly. Given the intricacies and interdependencies in modern data systems, data engineers often aren’t aware of the consequences a slight change to schema can have on their data pipelines. They can’t predict everything that could potentially go wrong when updating schema (nor should they have to spend tedious hours mapping out upstream and downstream dependencies.) Therefore, it is best to educate your data team on the potential repercussions changes to schema can have on others in the organization. During a recent conversation with a CDO at a leading e-commerce company, he revealed that he requires all new data engineers to complete a change management certification program to ensure that they’re trained on these potential downstream impacts.
- Hold monthly meetings with data teams to review recent schema changes and the impact of these changes not being properly managed. It’s one thing to train your employees on the consequences of poorly managed schema changes, but to really create a culture around proactive communication, you should highlight examples of silent schema changes that led to broken data products downstream. During this meeting, you should correlate poorly managed schema changes to a rise in data incidents happening. Pro-tip: be careful not to point the finger; you can even structure the discussion as a blameless postmortem.
- Establish stakeholders who will sign off on schema changes. I recently spoke with another Head of Data, this time at a 3,000-person FinTech company, who told me that, “If everyone owns data, then no one owns it.” Getting too many stakeholders involved in signing off for schema changes creates friction and ultimately slows down your process to update schemas. Establish a few key stakeholders early on to represent each data team to sign off on all changes.
- Create a communication strategy early on to flag new schema changes. All of your hard work to educate and train your data engineers on managing schema changes goes to waste if you don’t have a strategy to communicate these changes with the broader team. Establish a communication plan early on, share it widely, and ensure it is part of your data engineering team’s workflow. Otherwise, schema change communication will become an afterthought, forcing your team to put on their firefighting hats instead of building pipelines.
What is the structure of your data organization?
Customers have shared with us that the structure of their data team plays a crucial role in how they communicate schema changes. Ultimately, it depends on whether they are spread across multiple departments.
So, how does the structure of your team affect schema communication? Let’s assess the most common team structures: centralized and decentralized.
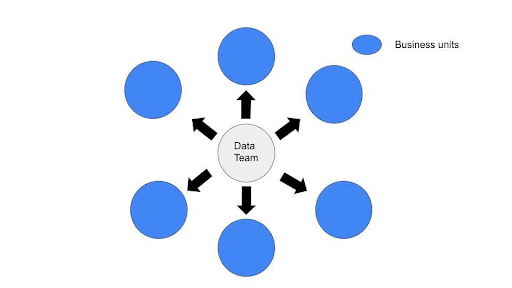
If your data team is centralized
It is likely that engineers can effectively communicate schema changes as other team members have visibility into the projects you are working on at any moment. While this is not always the case for every organization, our customers have found that centralized data teams typically have fewer bottlenecks to manage. For example, one data leader shared that their team was decentralized at a previous company, which led to schema changes requiring over 50 people to approve. Schema changes that should have occurred in a few hours took up to two weeks to happen. Talk about a waste of time…
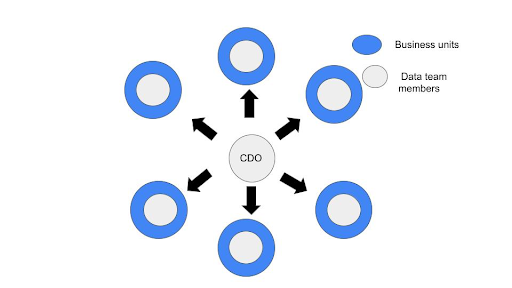
If your data team is decentralized (or your team is moving in that direction)
Decentralized teams are at greater risk of unexpected schema changes occurring without the proper structure in place for team members, as you are not always aware of how other teams are using data sets that you are responsible for.
Therefore, it is best to communicate schema changes as they happen instead of weekly or bi-weekly to minimize risk. In addition, when sharing schema modifications, you should share with the team what is changing and why you are updating, adding, or even deleting schema.
(It’s important to note, however, that another option exists: hybrid team structures, which blend characteristics of both approaches.)
What impact up and downstream will the schema change have?
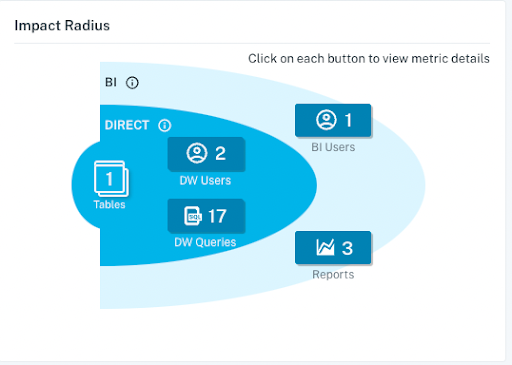
Data engineering teams often face unfortunate impacts from minor schema changes. However, constant schema updates often signify the development and progression of data pipelines to larger and more advanced workloads. Without proper context into which fields feed into and rely on others, it is challenging to measure the potential impact of these changes on your data products, from Excel spreadsheets to Looker dashboards.
Before making schema changes, your team should understand the lineage of your data pipelines. Without automation in place to do this for your team, it becomes a highly tedious process, leading to tribal knowledge of data pipelines living among certain data team members.
Marion Rybnikar, the Senior Director of Data Strategy & Governance for Slice, a data-driven company that empowers over 18,000 independent pizzerias with modern tooling, is an advocate for communicating and properly managing schema changes.
“Schema changes are flagged to us through a channel and we perform an impact analysis on behalf of the business, where we look at upstream and downstream consequences. Then at that point we provide approvals to different parts of the organization or manage subsequent change,” she said.
“For example, if someone is going to make a change that is going to break something, we would project manage to make sure that those changes are all implemented before the next stage occurs.”
How will you communicate schema changes with the broader data team?
If a schema change occurs and no one knows about it, did it really happen? Data team members shouldn’t be left in the dark when schema changes occur.
Below are a few ways data teams are communicating schema changes to the broader data organization:
- Slack and Microsoft teams: Data teams have dedicated channels specifically for schema change announcements, and every time a change is made, it is shared there for greater visibility.
- Department heads communicating changes: Schema changes often have to be signed off on by various departments inside the data team, such as Business Intelligence, Data Science, Data Governance, and Data Engineering. Therefore, when changes happen and make their way to production, it falls in the hands of team leaders to effectively communicate what was changed and why the change occurred.
- Appoint a change management manager: Managing schema changes swiftly and efficiently is particularly challenging and time-consuming. If your team is large enough, it can feel like a part-time job, which has led to data teams hiring or promoting team members who are responsibility is to communicate schema changes to the broader data organization. The change management manager communicates changes, facilitates department heads signing off on changes, and conducts impact analysis before a change occurs to ensure data pipelines will still run as expected.
Are you measuring the impact of change management on your organization?
To accelerate the adoption of change management across your data team, it is crucial to measure the impact of communicating schema updates. After all, if you can’t measure it, you can’t improve it.
Marion from Slice shared two specific signals for your data team to track:
- Identify clear success stories. Find specific use cases that correlate a lack of communication around schema changes which led to an increase in data incidents resulting from changes not being communicated. For instance, did a data engineer change the naming convention for columns inside your daily sales table, causing critical forecasts to break, sending your Head of Revenue into hysterics? Hopefully not – but if you didn’t, that’s a good narrative to share when you’re advocating for change management’s value.
- Track the number of data incidents. If the number of data incidents decreases over time for your organization, can you directly correlate that decrease to your organization’s change management efforts? For example, are engineers making schema changes and communicating to the rest of the team what they are changing and why those changes are occurring? If they are communicated, you’ll likely see a decrease in data incidents.
While there are plenty of other signals to look out for, such as an increase in time-to-resolution (TTR) and time-to-detection (TTD), it ultimately comes down to ensuring the work your data team is putting into managing schema changes is valuable for the organization.
Change management is both a technological and cultural challenge
Managing change is not easy. Especially inside organizations that prioritize speed and quality, striking a balance between the two almost seems impossible at times.
At the end of the day, without a plan in place to manage schema changes, three things will likely happen:
- Your data pipelines will contain bad data as schema changes go unnoticed until an executive pulls a report and later complains the data was wrong. Or even worse, business decisions will be made based on faulty data, costing the business money and eroding trust in data quality with business stakeholders.
- Your data team’s approach to data quality will be reactive instead of proactive, as engineers will spend valuable time firefighting data quality issues, disrupting tasks they were previously completing.
- Data downtime incidents will increase. Data downtime refers to periods of time when your data is partial, erroneous, missing or otherwise inaccurate. It is highly costly for data-driven organizations today and affects almost every team, yet it is typically addressed on an ad-hoc basis.
An effective change management program involves having the right technologies and mindset in place. I recommend implementing the following that seamlessly integrate with the data engineering workflow:
- CI/CD tools like GitHub or GitLab: These types of tools help your team verify code changes and ship high quality code faster by embracing continuous integration.
- Data testing: Data teams need a way to stop bad quality data from working its way downstream. Tests can be set up to ensure data is unique, not null, and between certain values.
- Data observability: Schema is one of the five pillars of data observability. With data observability you can monitor tables to see who is making schema changes and trace which tables downstream rely on that table.
Here’s to more change management, healthier pipelines, and most importantly, reliable data.
Interested in learning about how Monte Carlo can help your team improve schema change management? Reach out to Scott O’Leary and book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.