Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is a Data Platform? And How to Build An Awesome One

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
An enterprise data platform, often referred to as a ‘modern data stack,’ is the central processing hub for an organization’s data ecosystem. The data platform manages the collection, normalization, transformation, and application of data for a given data product—from business insights and dashboards to ML and AI engineering.
By integrating tools from a variety of vendors, an enterprise data platform enables a data engineering team to not only manage an organization’s data but also activate it for a domain’s use cases.
A comprehensive enterprise data platform solution powers data acquisition, storage, preparation, delivery, governance, and even the robust security needs of users and applications.
In today’s data-driven landscape, building an enterprise data platform is no longer a nice-to-have, but a necessity for most organizations. In fact, many companies will even differentiate themselves from competitors based on their ability to glean actionable insights from their data—whether that’s to improve their customer experience, increase revenue, define their brand, or even create their own large language models for advanced AI applications.
And just like the companies they power, no two enterprise data platforms are ever exactly alike. From data sources and use cases to industry and company size, how a company structures its data platform will depend on a variety of critical factors. So, with all that ambiguity, where’s a data engineer to start?Even with a revolving door of new data platform tooling—in an increasingly business critical field no less—there are still a few must-haves to get you pointed in the right direction.
In this quick and dirty guide, I’ll lay out the blueprint for what your platform needs at a foundational level, what are some nice-to-haves, and how your team can think about each of those critical decisions.
We’ll cover:
- What is a data platform?
- The five must-have layers of a modern data platform
- Data Storage and Processing
- Data Ingestion
- Data Transformation and Modeling
- Business Intelligence (BI) and Analytics
- Data Observability
- Data Orchestration
- Other important data platform layers
- Data platform vs. customer data platform
- Build or buy your 5-layer data platform? It depends.
- Frequently Asked Questions
What is a data platform?
In the past, data platforms were viewed as a means to an end versus the final product built by your data team. Now, companies are taking a page from software engineering teams and beginning to treat data platforms like production-grade software (data-as-a-service), dedicating valuable team resources to maintaining and optimizing them.
A data platform is a central repository and processing house for all of an organization’s data. A data platform handles the collection, cleansing, transformation, and application of data to generate business insights.
Data-first companies have embraced data platforms as an effective way to aggregate, operationalize, and democratize data at scale across the organization. As more organizations begin implementing data mesh architecture, and principles like data products, data teams have also to consider the data platform as the machine that develops, manages, surfaces, and governs data products.
To make things a little easier, I’ve outlined the six must-have layers you need to include in your data platform and the order in which many of the best teams choose to implement them. I’ve also updated this post to include additional layers frequently found within a modern data platform such as data governance, access management, and machine learning.
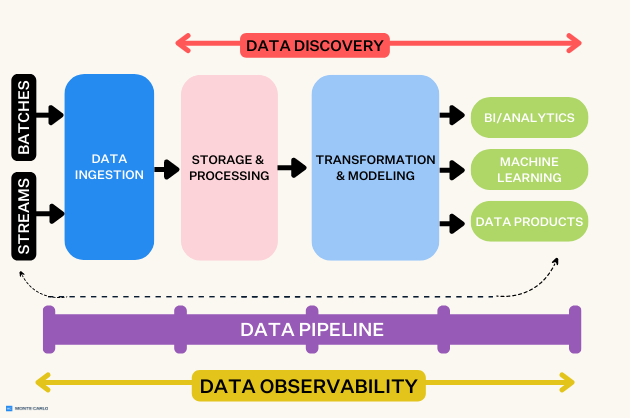
The five must-have layers of a modern data platform
Second to “how do I build my data platform?”, the most frequent data platform question I get from customers is “where do I start?”
The “right” data stack will look vastly different for a 5,000-person e-commerce company than it will for a 200-person startup in the FinTech space, but there are a few core layers that all data platforms must have in one shape or another.
Keep in mind: just as you can’t build a house without a foundation, frame, and roof, at the end of the day, you can’t build a truly scalable data platform without these five layers. Below, we share what the “basic” enterprise data platform looks like and list some hot tools in each space (you’re likely using several of them):
Data Storage and Processing
The first layer? Data storage and processing layer – as you are need a place to store your data and process it before it is later transformed and sent off for analysis. It becomes especially important to have a data storage and processing layer when you start to deal with large amounts of data and are holding that data for a long period of time and need it to be readily available for analysis.
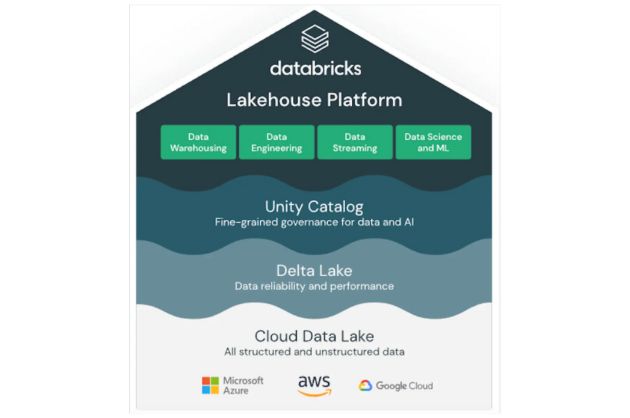
With companies moving their data platforms to the cloud, the emergence of cloud-native solutions (data warehouse vs data lake or even a data lakehouse) have taken over the market, offering more accessible and affordable options for storing data relative to many on-premises solutions.
Whether you choose to go with a data warehouse, data lake or some combination of both is entirely up to the needs of your business.
Recently, there’s been a lot of discussion around whether to go with open source or closed source solutions (the dialogue between Snowflake and Databricks’ marketing teams really brings this to light) when it comes to building your data platform.
Regardless of which side you take, you quite literally cannot build a modern data platform without investing in cloud storage and compute.
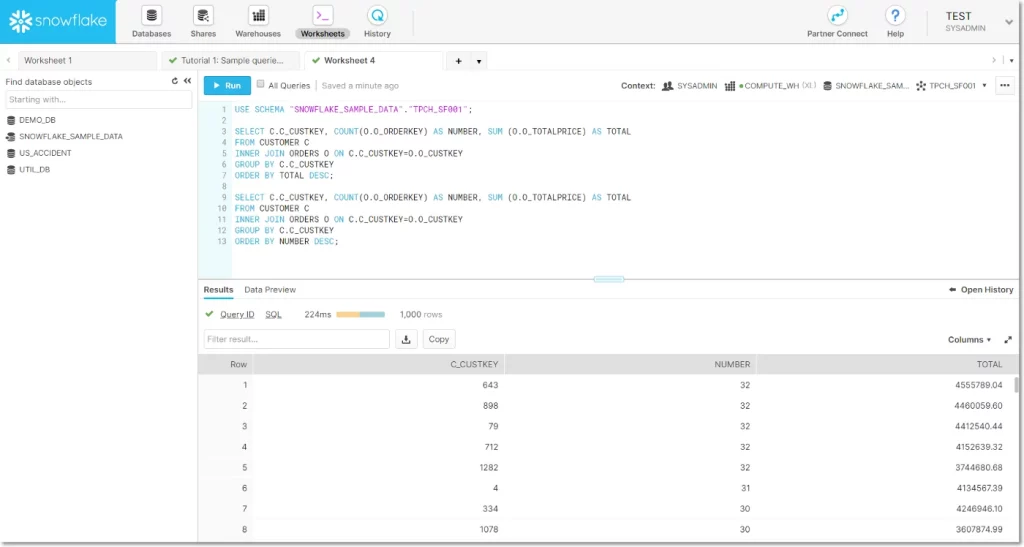
Below, we highlight some leading options in today’s cloud warehouse, lake, or [insert your own variation here] landscape:
- Snowflake – The original cloud data warehouse, Snowflake provides a flexible payment structure for data teams, as users pay separate fees for computing and storing data.
- Google BigQuery – Google’s cloud warehouse, BigQuery, provides a serverless architecture that allows for quick querying due to parallel processing, as well as separate storage and compare for scalable processing and memory.
- Amazon Redshift – Amazon Redshift, one of the most widely used options, sits on top of Amazon Web Services (AWS) and easily integrates with other data tools in the space.
- Firebolt – A SQL-based cloud data warehouse that claims its performance is up to 182 times faster than other options, as the warehouse handles data in a lighter way thanks to new techniques for compression and data parsing.
- Microsoft Azure – Microsoft’s cloud computing entrant in this list common among teams that leverage heavy Windows integrations.
- Amazon S3 – An object storage service for structured and unstructured data, S3 gives you the compute resources to build a data lake from scratch.
- Databricks – Databricks, the Apache Spark-as-a-service platform, has pioneered the data lakehouse, giving users the options to leverage both structured and unstructured data and offers the low-cost storage features of a data lake.
- Dremio – Dremio’s data lake engine provides analysts, data scientists, and data engineers with an integrated, self-service interface for data lakes.
Data Ingestion
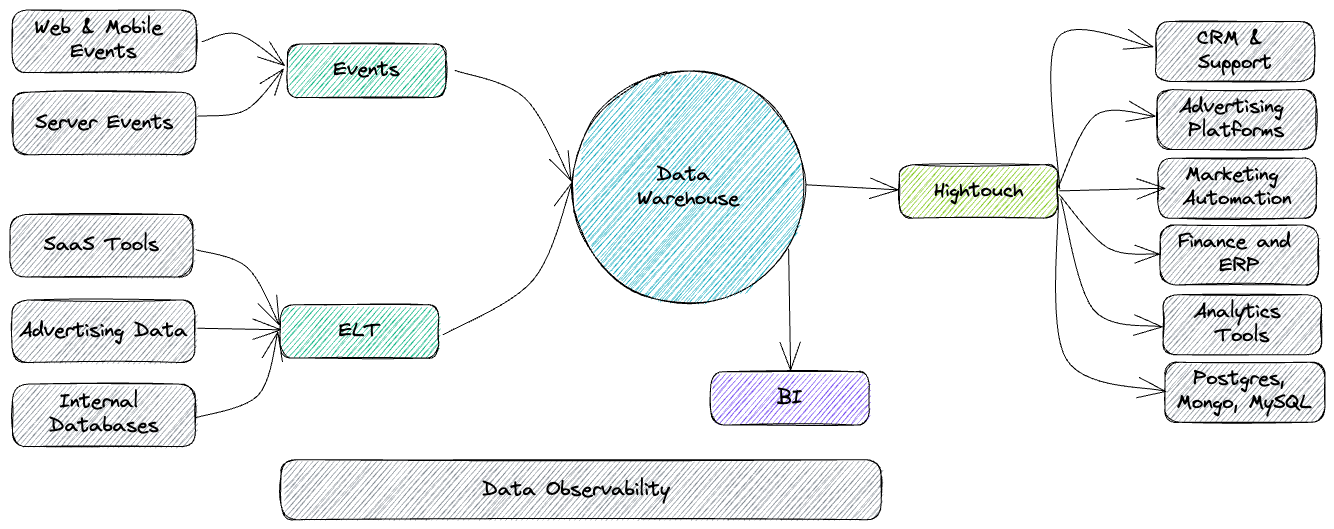
As is the case for nearly any modern data platform, there will be a need to ingest data from one system to another.
As data infrastructures become increasingly complex, data teams are left with the challenging task of ingesting structured and unstructured data from a wide variety of sources. This is often referred to as the extraction and loading stage of Extract Transform Load (ETL) and Extract Load Transform (ELT).
While you may have heard the term “zero-ETL” in reference to integrating data from one location to another without the need for data pipelines, the widespread adoption of this practice is still quite a ways into the future.
Below, we outline some popular tools in the space broken into two groups. Batch, which ingests data from a source at a pre-defined time or in pre-defined groupings, is the most popular way for data engineers to gather data. Data streaming is becoming more popular, especially for operational use cases where the value of (near) real-time data is worth the added complexity (see batch vs streaming).
Batch data ingestion solutions include:
- Fivetran – A leading enterprise ETL solution that manages data delivery from the data source to the destination.
- Singer – An open source tool for moving data from a source to a destination.
- Stitch – A cloud-based open source platform that allows you to rapidly move data from a source to a destination.
- Airbyte – An open source platform that easily allows you to sync data from applications.
Data streaming ingestion solutions include:
- Apache Kafka – Confluent is the vendor that supports Kafka, the open source event streaming platform to handle streaming analytics and data ingestion. They also recently acquired Apache Flink, another streaming solution.
- Amazon Kinesis– A streaming solution from AWS that may be ideal for those utilizing Redshift as their data warehouse.
- Google Pub/Sub– A GCP service that enables you to ingest streaming data into BigQuery, data lakes, or operational data bases. Google made waves last year when they announced the ability to stream Pub/Sub directly into BigQuery without pipelines.
- Apache Spark– Labeled as a unified analytics engine for large scale data processing, many leverage this open source solution for streaming use cases, often in conjunction with Databricks.
Even with the prevalence of ingestion tools available on today’s market, some data teams choose to build custom code to ingest data from internal and external sources, and many organizations even build their own custom frameworks to handle this task.
Orchestration and workflow automation, featuring such tools as Apache Airflow, Prefect, and Dagster, often folds into the ingestion layer, too. Orchestration takes ingestion a step further by taking siloed data, combining it with other sources, and making it available for analysis.
I would argue, though, orchestration can be (and should be) weaved into the data platform after you handle the storage, processing, and business intelligence layers. You can’t orchestrate without an orchestra of queryable data, after all!
Data Transformation and Modeling
Data transformation and modeling are often used interchangeably, but they are two very different processes.
When you transform your data, you are taking raw data and cleaning it up with business logic to get the data ready for analysis and reporting. When you model data, you are creating a visual representation of data for storage in a data warehouse.
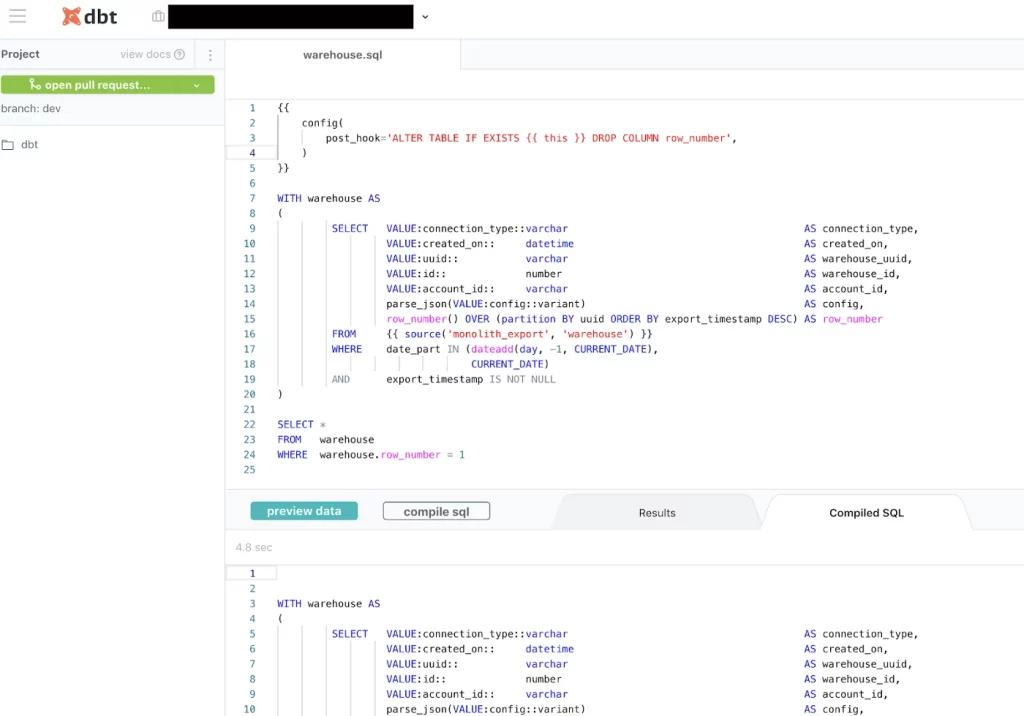
Below, we share a list of common data transformation and modeling tools that data engineers rely on:
- dbt – Short for data build tool, is the open source leader for transforming data once it’s loaded into your warehouse.
- Dataform – Now part of the Google Cloud, Dataform allows you to transform raw data from your warehouse into something usable by BI and analytics tools.
- Sequel Server Integration Services (SSIS) – Hosted by Microsoft, SSIS allows your business to extract and then transform that data from a wide variety of sources which you can then later use to load into your destination of choice.
- Custom Python code and Apache Airflow – Before the rise of tools like dbt and Dataform, data engineers commonly wrote their transformations in pure Python. While it might be tempting to continue using custom code to transform your data, it does increase the chances of errors being made as the code is not easily replicable and must be rewritten every time a process takes place.
The data transformation and modeling layer turns data into something a little more useful, readying it for the next stage in its journey: analytics.
Business Intelligence (BI) and Analytics
The data you have collected, transformed, and stored within your data platform serves your business no good if your employees can’t use it.
If the data platform was a book, the BI and analytics layer would be the cover, replete with an engaging title, visuals, and summary of what the data is actually trying to tell you. In fact, this layer is often what end-users think of when they picture a data platform, and for good reason: it makes data actionable and intelligent, and without it, your data lacks meaning.
Tableau is a leading business intelligence tool that gives data analysts and scientists the capability to build dashboards and other visualizations that power decision making. Image courtesy of Tableau
Below, we outline some popular BI solutions among top data teams:
- Looker – A BI platform that is optimized for big data and allows members of your team to easily collaborate on building reports and dashboards.
- Sigma Computing – A BI platform that delivers cloud-scale analytics with the simplicity of a spreadsheet and familiar data visualizations.
- Tableau – Often referred to as a leader in the BI industry, it has an easy-to-use interface.
- Mode – A collaborative data science platform that incorporates SQL, R, Python, and visual analytics in one single UI.
- Power BI – A Microsoft-based tool that easily integrates with Excel and provides self-service analytics for everyone on your team.
This list is by no means extensive, but it will get you started on your search for the right BI layer for your stack.
Data Observability
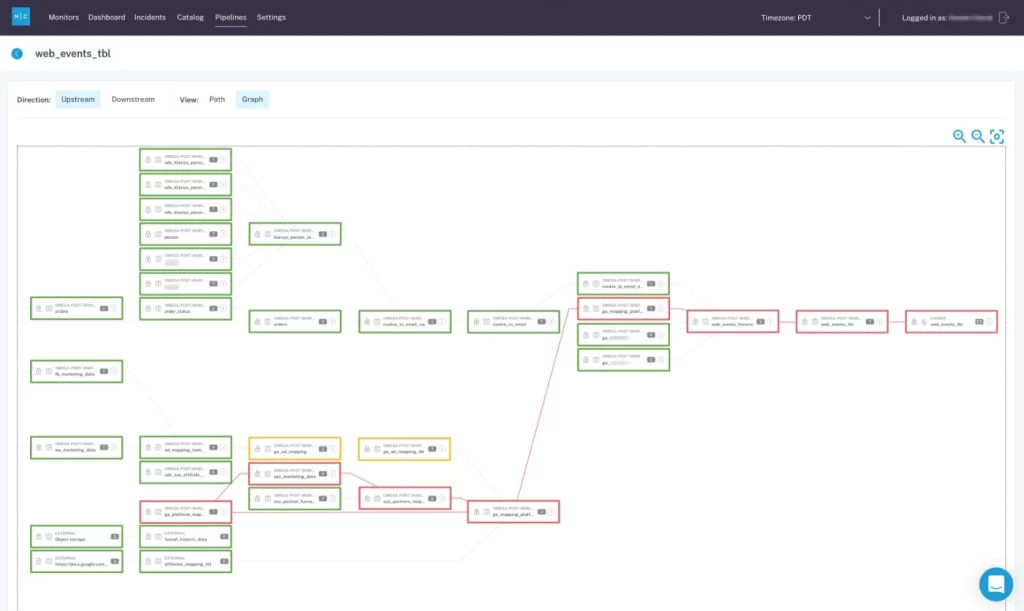
With data pipelines becoming increasingly complex and organizations relying on data to drive decision-making, the need for this data being ingested, stored, processed, analyzed, and transformed to be trustworthy and reliable has never been higher. Simply put, organizations can no longer afford data downtime i.e., partial, inaccurate, missing, or erroneous data. Data observability is an organization’s ability to fully understand the health of the data in their data ecosystem. It eliminates data downtime by applying best practices learned from DevOps to data pipelines, ensuring that the data is usable and actionable.
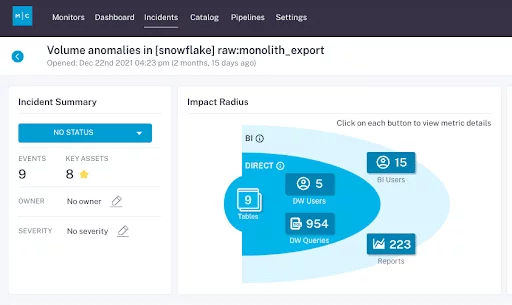
Your data observability layer must be able to monitor and alert for the following pillars of observability within an enterprise data platform:
- Freshness: is the data recent? When was the last time it was generated? What upstream data is included/omitted?
- Distribution: is the data within accepted ranges? Is it properly formatted? Is it complete?
- Volume: has all the data arrived?
- Schema: what is the schema, and how has it changed? Who has made these changes and for what reasons?
- Lineage: for a given data asset, what are the upstream sources and downstream assets which are impacted by it? Who are the people generating this data, and who is relying on it for decision-making?
An effective, proactive data observability solution will connect to your existing data platform quickly and seamlessly, providing end-to-end lineage that allows you to track downstream dependencies.
Additionally, it will automatically monitor your data-at-rest without requiring the extraction of data from your data store. This approach ensures you meet the highest levels of security and compliance requirements and scale to the most demanding data volumes.
Data Orchestration
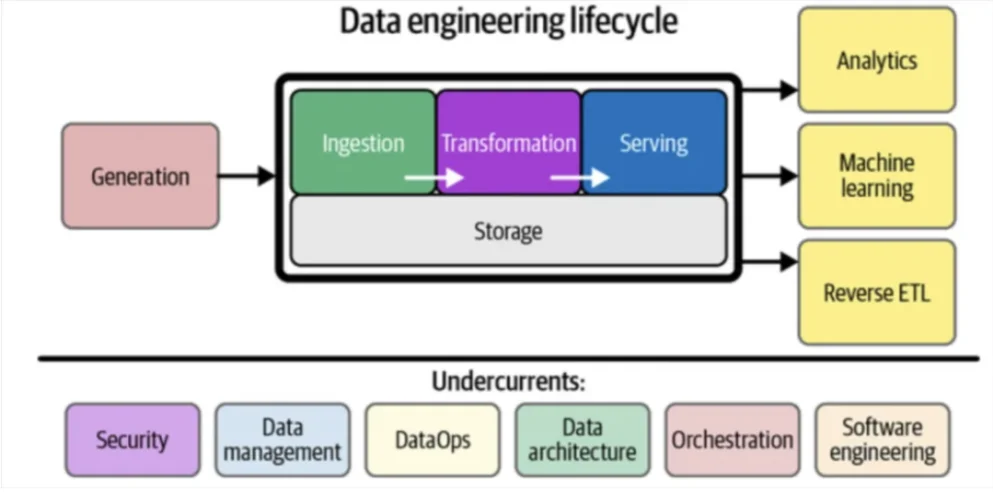
Data orchestration is the organization of multiple tasks (manual or automated) into a single end-to-end process. By controlling when and how critical jobs are activated, orchestration ensures that data flows predictably through your platform, arriving at the right time, in the right order, and at the right velocity to maintain production standards.
The reason that orchestration is a functional necessity of the 5 Layer Data Stack—if not a literal one—is due to the inherent lack of scalability in hand-coded pipelines. While data pipelines don’t require orchestration to be considered functional, once data platforms scale beyond a certain level of complexity, managing jobs will become nearly impossible without one.
Much like transformation and data quality, engineering resources become the limiting principle for scheduling and managing pipelines.
When you’re extracting and processing a small amount of data, the effort to schedule those jobs is also relatively small. But when you’re extracting and processing much larger amounts of data including multiple sources and use cases, the effort is exponentially greater—and that’s where an orchestration layer shines.
Some of the most popular solutions for data orchestration include Apache Airflow, Dagster, and relative newcomer Prefect.
Other important data platform layers
Data governance
Data governance is the decision-making process organizations used to maintain the availability, usability, and security of data. Good governance programs help organizations “decide how to decide” about data. And as one data leader told us, it’s the “keep your CFO out of jail card.“
- How is data created, collected, and processed?
- Who should have permission to access this data?
- What data is relevant for each role?
- Where is this data stored?
- When do we retire this data?
Unlike most layers of the modern enterprise data stack, data governance isn’t strictly a Saas solution. While SaaS tools like data catalogs can be helpful for enabling some functions of data governance, they can’t be utilized as a comprehensive solution. True data governance will need to include a combination of people, processes, and principles that all converge to help teams set and maintain standards, manage visibility over datasets, and facilitate compliance.
Data catalog
Just because a data catalog isn’t the substance of data governance doesn’t mean it’s not useful. Many organizations choose to implement data catalog solutions as part of their data governance motion to support compliance use cases. Data catalogs leverage the metadata generated through a modern data platform to provide descriptive information on critical data assets such as tables, key metrics, and more. Think an automatically updating encyclopedia for your data platform.
Here’s a list of the best data catalog tools for 2023.
Data Discovery
As data becomes increasingly complex and the need for real-time access to reliable data becomes a priority, the processes and technologies underlying this layer of the data platform need to evolve, too. If data catalogs are a map, data discovery is the navigation system that’s being updated with the latest insights and information.
At a bare minimum, data discovery should address the following needs:
- Self-service discovery and automation: Data teams should be able to easily leverage their data catalog without a dedicated support team.
- Scalability as data evolves: As companies ingest more and more data and unstructured data becomes the norm, the ability to scale to meet these demands will be critical for the success of your data initiatives. Data discovery leverages machine learning to gain a bird’s eye view of your data assets as they scale, ensuring that your understanding adapts as your data evolves.
- Real-time visibility into data health: Unlike a traditional data catalog, data discovery provides real-time visibility into the data’s current state, as opposed to its “cataloged” or ideal state. Since discovery encompasses how your data is being ingested, stored, aggregated, and used by consumers, you can glean insights such as which data sets are outdated and can be deprecated, whether a given data set is production-quality, or when a given table was last updated.
- Support for governance and warehouse/lake optimization: A proper data discovery tool can serve as a central source of truth which is critical to making data available and usable across domains.
Data discovery empowers data teams to trust that their assumptions about data match reality, enabling dynamic discovery and a high degree of reliability across your data infrastructure, regardless of domain.
The semantic layer
A semantic layer, sometimes referred to as a metrics layer, is the component of the modern data stack that defines and locks down the aggregated metrics that are important to business operations. This is important because to work toward shared goals, the business needs to have one source of truth for how they calculate key metrics like, “customer,” or “active orders.”
The semantic layer was pioneered years ago by Looker and LookML, but bundling the semantic layer within the BI layer can create siloes for those users (typically data scientists working within a machine learning stack) who don’t interface with it. In response, dbt has recently staked a claim on the semantic layer as it starts to become the connective tissue of the modern data platform.
Access management
You want the data in your modern data platform to be highly available only to those who have a need to access it. Access management solutions have become more critical as a means to protect sensitive information and PII as well as to avoid fines from data regulations such as GDPR or CCPA. Vendors in this space include:
- Immuta– Removes the complexity of managing and enforcing data policies so that organizations can speed up access to data without compromising security.
- BigID– A modern, extensible platform for privacy, protection, and perspective – across all data, everywhere.
- Privacera– Automates data access, security and policy management across multiple cloud services from a single, unified interface.
- Okera– Provides multiple enforcement patterns and platform-agnostic, policy-based data access control so policies are enforced consistently across all environments.
- SatoriCyber– Decouples security, privacy and access controls from the data layer, enabling data teams to move faster.
Machine learning and generative AI
Notebooks, feature stores, ML OPs, and ML Observability could all fall under the banner of machine learning and AI.
However, with the recent obsession (dare we say mania?) surrounding large language models, what most people are probably asking is “how long before a robot layer takes my job?”
And fortunately for all of us…that probably won’t be any time soon. Current generative AI use cases in data and engineering are focused almost exclusively on scaling productivity. That means that data engineers are still fully at the helm of their platforms, and generative AI is really just hanging around to bring you your coffee.
Tools like GitHub Co-Pilot, Snowflake Document AI, and Databricks LakehouseIQ are all AI-based solutions focused on expanding productivity that we could see operationalized more frequently across data teams in the coming years.
Another thing to note is that, by and large, the vast majority of generative AI applications in-use today are hosted in the cloud and surfaced with an API. That means that to support them, you’ll also need a robust, cloud-based data stack to reliably store, transform, train, and serve the data powering them. (A data platform like the one we’re talking about in this article, conveniently enough.)
In many ways, we still don’t know what the future of generative AI will hold for data platforms. But what we do know is that data teams will play a big part in its success.
Data platform vs. customer data platform
Data platforms can sometimes be confused with a customer data platform. It’s important to note a customer data platform solely deals with customer-related data.
The Customer Data Platform Institute defines a customer data platform as a “packaged software that creates a persistent, unified customer database accessible to other systems.” Customer data platforms consist of data from various first, second, or third-party sources including web forms, web page activity, social media activity, and behavioral data.
Customer data platforms and data platforms shouldn’t be used interchangeably. They are two entirely different tools, with very different purposes. Customer data platforms exist to create a single source of truth for a customer profile, helping businesses piece together disparate behaviors and information about a given customer to improve experiences or send more targeting communications and advertisements.
Data platforms, on the other hand, aggregate all of a company’s analytical data – both customer data and operational data – to help the business drive better decision making and power digital services.
Build or buy your 5-layer data platform? It depends.
Building a data platform is no easy task, and there’s a lot to take into consideration. One of the biggest challenges our customers face when standing up their data platform is whether they should just build certain layers in-house, invest in SaaS solutions, or explore the wide world of open source.
Our answer? Unless you’re Airbnb, Netflix, or Uber, you generally need to include all three. Check out the story told by Freshly’s Senior Director of Data on how they built their 5-layer data platform over the years.
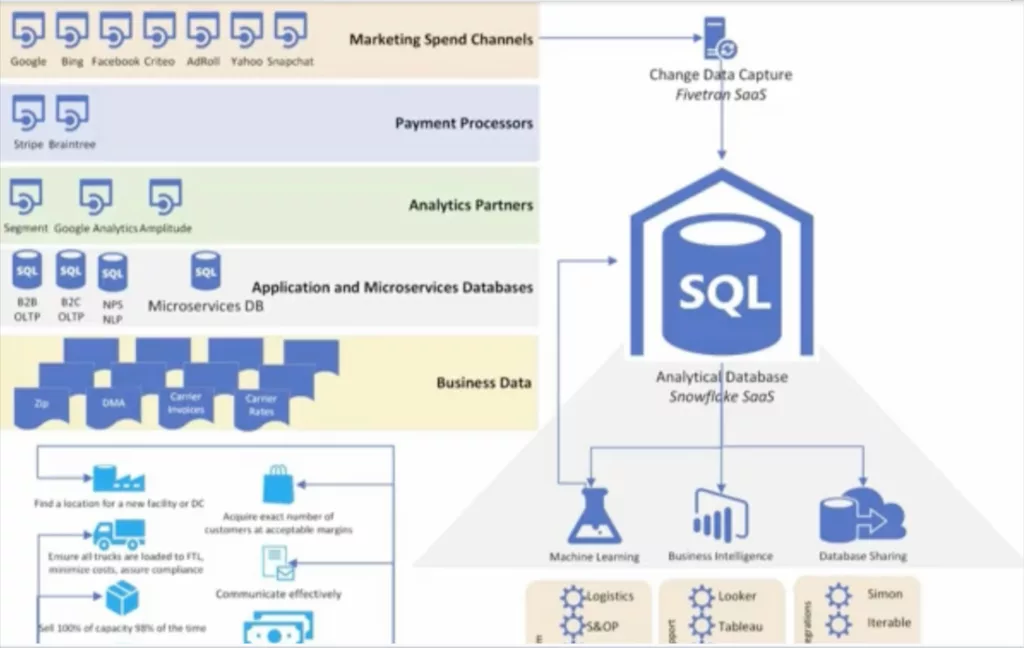
There are pros and cons to each of these solutions, but your decision will depend on many factors, including but not limited to:
- The size of your data team. Data engineers and analysts already have enough on their plates, and requiring them to build an in-house tool might cost more time and money than you think. Simply put, lean data teams do not have the time to get new team members up to speed with in-house tools, let alone build them. Investing in easily configurable, automated, or popular solutions (i.e., open-source or low-code/no-code SaaS) is becoming increasingly common among non-Uber/Airbnb/Netflix data teams.
- The amount of data your organization stores and processes. When choosing a solution it is important to select one that will scale with your business. Chances are, it doesn’t make sense for a lone wolf data analyst at a 20-person company to go with a $10K per year transformation solution if all you need is a few lines of code to do the job.
- Your data team’s budget. If your team is working with a limited budget but many hands, then open source options might be a good fit for you. However, keep in mind you are typically on your own when it comes to setting up and implementing open-source tools across your data stack, frequently relying on other members of the community or the project creators themselves to build out and maintain features. When you take into account that only about 2 percent of projects see growth after their first few years, you have to be careful with what you fork.
- Who’s going to use the tool? If the tool is meant for data engineers, it might make sense to build the tool. If it’s a blend of stakeholders from across the organization, you might be better off buying a user-friendly and collaborative tool.
- What data problems is the tool solving? If the use case is highly specific to your business, it likely makes sense to build the solution in-house. If the tool is solving a common industry problem, you might benefit from the expertise and experience of a third-party vendor.
- What are your data governance requirements? With data governance being top of mind for most organizations in 2022, it is crucial that the solution you choose can meet your businesses’ needs and comply with regulations such as CCPA and GDPR. Some companies that deal with highly sensitive data are more comfortable building their own solutions to ensure compliance across multiple jurisdictions.
Regardless of which path you choose, building out these layers will give you the foundation to grow and scale and, most importantly, deliver insights and products your company can trust.
Did we miss anything? Reach out to Barr Moses or Lior Gavish with any comments or suggestions.
Interested in learning more about Data Observability? Grab a time to speak with us using the form below.
Our promise: we will show you the product.
Frequently Asked Questions
What is a modern data platform?
A modern data platform consists of multiple integrated cloud based solutions typically with a data warehouse or lakehouse at the center for storage and processing. Other common data platform components include ingestion, orchestration, transformation, business intelligence, and data observability.
What is a good data platform?
A good data platform is one that fits your organization’s requirements. Common characteristics of good data platforms include being cloud native, highly scaleable, structured metadata, support for ACID transactions and modular (easy to change smaller components). Examples include data platforms built around Snowflake, BigQuery, Redshift, and Databricks.
What is an example of a data platform?
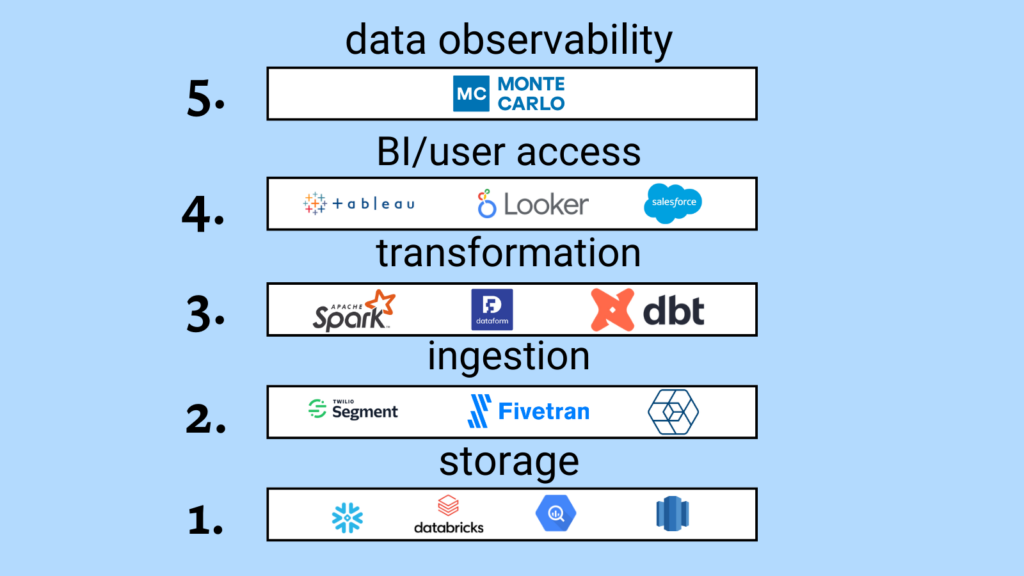
One of the most common data platforms used by data teams today would be FiveTran for ingestion, Airflow for orchestration, dbt for transformation, Snowflake for storage and compute, Looker for BI, and Monte Carlo for data observability.
Why do I need a modern data platform?
You need a modern data platform to centralize, manage, and process your organization’s data efficiently. It enables data collection, normalization, transformation, and application to generate business insights, improve customer experience, increase revenue, and support advanced AI applications.
How to build a modern data platform?
To build a modern data platform, you should start with data storage and processing, followed by data ingestion, data transformation and modeling, business intelligence (BI) and analytics, data observability, and data orchestration. Consider integrating additional layers such as data governance, access management, and machine learning.
What is the difference between modern data platform and modern data stack?
A modern data platform is a central repository and processing hub for all of an organization’s data, handling its collection, transformation, and application. A modern data stack refers to the collection of tools and technologies used to build this platform.
How does a data platform work?
A data platform works by collecting, cleansing, transforming, and applying data to generate business insights. It integrates various tools to manage data from ingestion to storage, transformation, analysis, and governance, ensuring data is ready for use across the organization.
What is the purpose of a data platform?
The purpose of a data platform is to centralize and manage all of an organization’s data, enabling efficient processing and analysis to generate actionable insights, support decision-making, and power digital services.
What is the difference between database and data platform?
A database is a system that stores and manages data, often for specific applications. A data platform is a comprehensive system that includes databases and other tools to handle the entire lifecycle of data, from collection and storage to transformation, analysis, and governance.
Read more posts.