Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Top Data Lake Vendors (Quick Reference Guide)

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Data lakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. By accommodating various data types, reducing preprocessing overhead, and offering scalability, data lakes have become an essential component of modern data platforms, particularly those serving streaming or machine learning use cases.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
However, one of the biggest trends in data lake technologies, and a capability to evaluate carefully, is the addition of more structured metadata creating “lakehouse” architecture. Databricks Data Catalog and AWS Lake Formation are examples in this vein.
This trend has enabled data teams to leverage the data lakehouse for more analytical use cases traditionally reserved for the data warehouse. See our post: Data Lakes vs. Data Warehouses.
While the lines between data lake and data warehouse have blurred, the value of data lakes or lakehouses is as clear as ever. To help data teams evaluate this value we listed, in no particular order, some of the top data lake vendors to consider including:
- Databricks Delta Lake
- Snowflake
- Amazon S3 and/or Lake Formation
- Google Cloud Platform and/or BigLake
- Starburst Data Lakehouse
- Dremio Lakehouse Platform
- Azure Data Lake Storage
- Cloudera Data Platform
- Teradata VantageCloud
- Oracle Cloud Infrastructure
- Vertica Unified Analytics Platform
Databricks Delta Lake
Databricks has native integration with multiple cloud providers–including AWS, Azure, and GCP–but what sets Databricks apart is its approach to collaborative machine learning. A notebook-based environment allows data engineers, data scientists, and analysts to work together seamlessly, streamlining data processing, model development, and deployment.
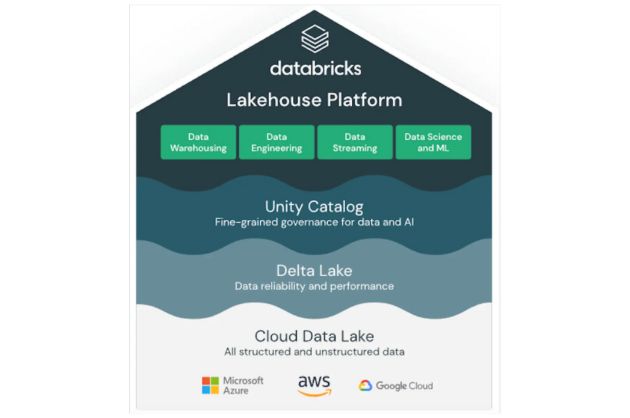
Databricks also pioneered the modern data lakehouse architecture, which combines the best of data lakes and data warehouses. Their revolutionary Delta Lake provides more metadata structure such as ACID transactions, schema enforcement, versioning, and unified batch/streaming capabilities. This significantly improves the ability to manage data at scale within a data lake environment.
One weakness of the data lake architecture was the need to “bolt on” a data store such as Hive or Glue. This was largely overcome when Databricks announced their Unity Catalog feature which fully integrates those metastores along with other partnering data catalog and data security technologies.
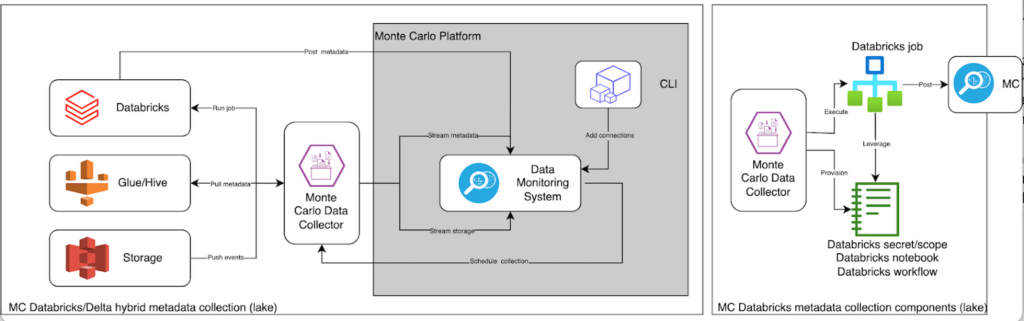
The Monte Carlo data observability platform, for example, can leverage the metadata within Unity Catalog to enhance its incident detection, resolution, and prevention capabilities within the Databricks environment.
As with other cloud-based storage solutions, the pay-as-you-go pricing model can be challenging for organizations with large or variable data workloads that can generate unforeseen costs if not managed effectively.
Snowflake
You may be surprised to see the pioneer of the modern data warehouse, Snowflake, on a list of top data lake vendors, and I don’t blame you. But remember that line from the introduction about the blurring line between data warehouses and data lakes? It works in both directions.
Notice how Snowflake dutifully avoids (what may be a false) dichotomy by simply calling themselves a “data cloud.”
Either way, Snowflake has emerged as a top “data lake vendor” by offering a scalable, high-performance, and fully managed solution for raw data storage. Snowflake has always prioritized two underpinning attributes of data lakes: flexibility and simplicity. We continuously hear data professionals describe the advantage of the Snowflake platform as “it just works.”
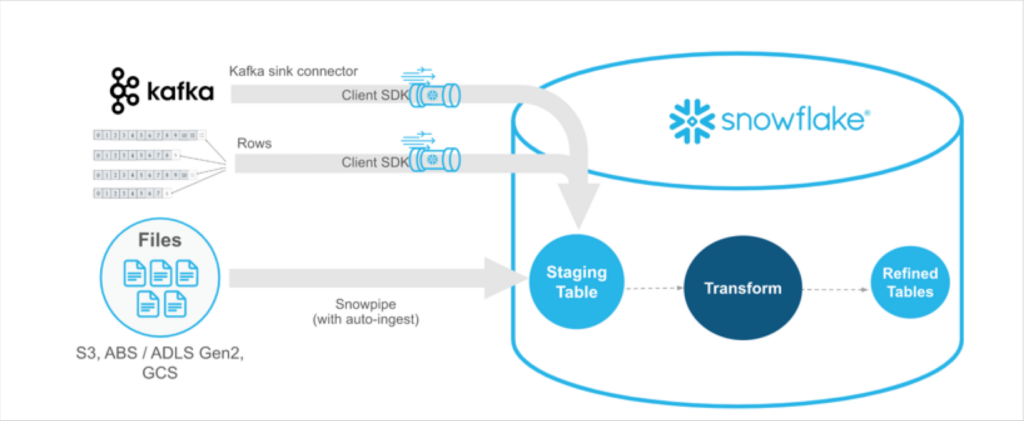
Snowflake simplifies data ingestion, querying, and transformation through its built-in support for SQL and compatibility with numerous data processing and integration tools. Snowpark and Snowpipe were giant steps forward adding the ability to program in multiple languages like Python and data streaming respectively.
Compatible with multiple cloud providers, including AWS, Azure, and GCP, Snowflake allows organizations to leverage their preferred cloud infrastructure without vendor lock-in.
Amazon S3 and/or Lake Formation
Amazon S3 is a popular storage platform to build and store data lakes thanks to its high availability and low latency access. It’s especially attractive for organizations that would like to leverage other complementary Amazon Web Services (AWS) services or database engines like Aurora.
S3 has seamless integration with the AWS ecosystem including AWS Glue for data cataloging, Amazon Athena for ad-hoc querying, and Amazon Redshift for data warehousing. The sheer number of services and configurations within the AWS ecosystem can be overwhelming and often requires specialized expertise to navigate effectively.
If not paired with Glue, or another metastore/catalog solution, S3 will also lack some of the metadata structure required for more advanced data management tasks.
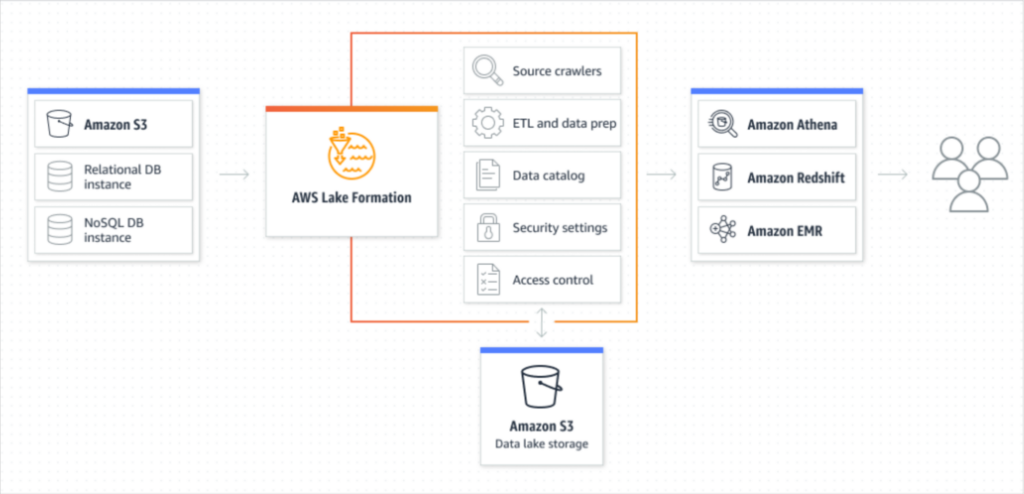
AWS Lake Formation offers an alternative for data teams looking for a more structured data lake or data lakehouse solution. As then AWS CEO and now Amazon CEO, Andy Jassy, explained when the service debuted at re:Invent in 2018:
“Setting up a data lake today means you have to, among other things, configure your storage and (on AWS) S3 buckets, move your data, add metadata and add that to a catalog. And then you have to clean up that data and set up the right security policies for the data lake. “This is a lot of work and for most companies, it takes them several months to set up a data lake. It’s frustrating…[Lake Formation] is a step-level change for how easy it is to set up data lakes,” he said.
Google Cloud Platform and/or BigLake
Google offers a couple options for building data lakes. You could use Google Cloud Storage (GCS) to store your data or there’s the new BigLake solution to build a distributed data lake that spans across warehouses, object stores and clouds (even those not on Google’s cloud).
If you plan to stay completely within Google’s cloud ecosystem, GCS may be the best fit. But if you have data already distributed across lakes, warehouses, and clouds, you could use BigLake to manage your data as if it were BigQuery tables and to greatly simplify access control management.
The added structure and governance from Dataplex makes BigLake an intriguing data lakehouse option as well. Sudhir Hasbe, Google Cloud’s senior director of Product Management for data analytics discussed BigLake in 2022 saying:
“We are going to seamlessly integrate our data management and governance capability with Dataplex, so any data that goes into BigLake will be managed [and] governed in a consistent fashion,” he said. “All of our machine-learning and AI capabilities … will also work on BigLake, as well as all our analytics engines, whether it’s BigQuery, whether it’s Spark, whether it’s Dataflow.”
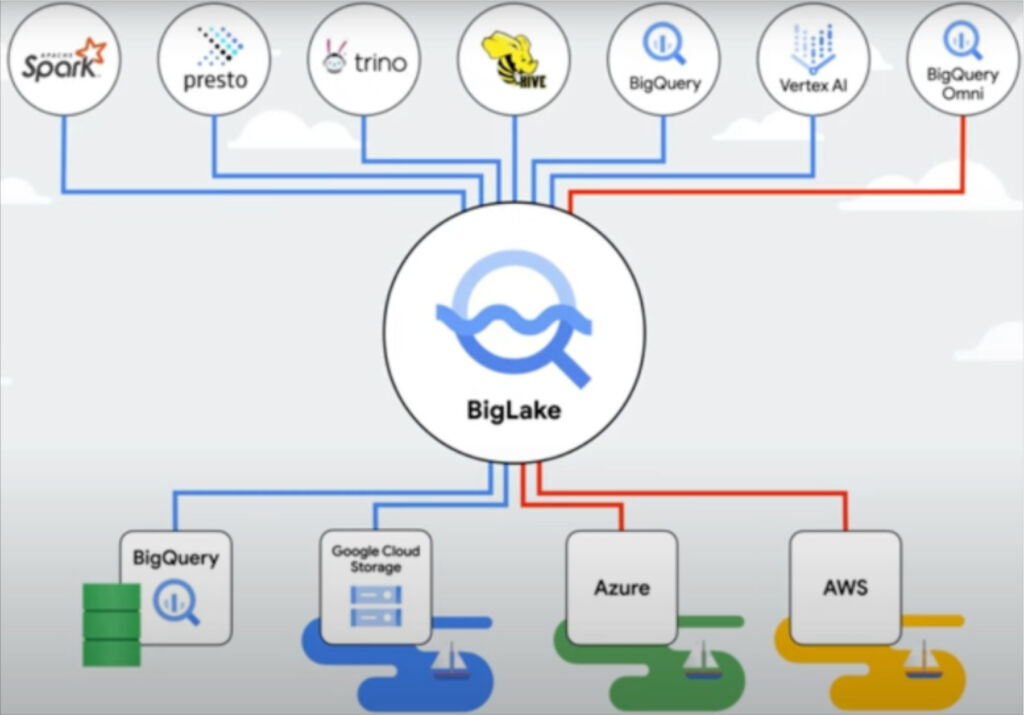
Besides connecting to data in GCS, BigLake also supports Amazon S3 and Azure data lake storage Gen 2. This eliminates the need to duplicate or move data, reducing cost and inefficiencies, and enables you to choose the best analytics tools regardless of where or how data is stored.
To summarize, the difference between Google Cloud Storage and BigLake is that Google Cloud Storage is an object storage service, whereas BigLake is a storage engine that extends storage capabilities to open formats on multi-cloud object stores, enabling organizations to unify data warehouses and lakes into a consistent format for faster data analytics.
Starburst Data Lakehouse
What sets Starburst Data Lakehouse apart from many data lake vendors is its flexibility of a data lake with the live, interactive querying capabilities of a data warehouse. Starburst excels in analytics use cases and their homepage boasts about it being the “fastest path from data to insights.”
Another benefit to Starburst is the strong support and integrations for more than 50 data sources, including even some legacy enterprise sources. If you are looking for a data lake that can function across Delta, Iceberg, MinIO table formats and connect with Oracle, Teradata and more–Starburst may be for you.
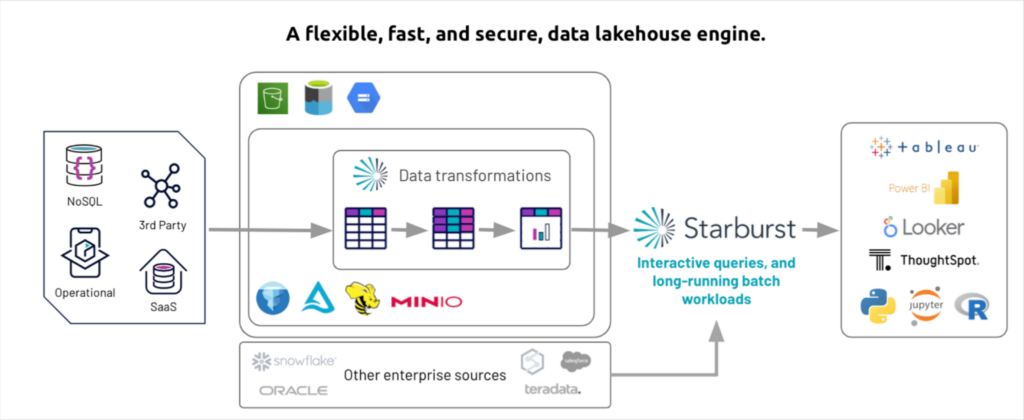
Performance can be affected when dealing with very large datasets or complex analytical workloads, as it relies on the underlying Presto engine. “Paying for the technical account manager is a must to achieve optimal efficiency for the tool,” one reviewer on G2 stated.
Dremio Lakehouse Platform
Dremio offers a forever-free lakehouse platform that supports numerous data sources and integrates well with popular analytics tools. One of the main benefits of Dremio is its ability to accelerate query performance through its Apache Arrow-based query engine called Sonar.
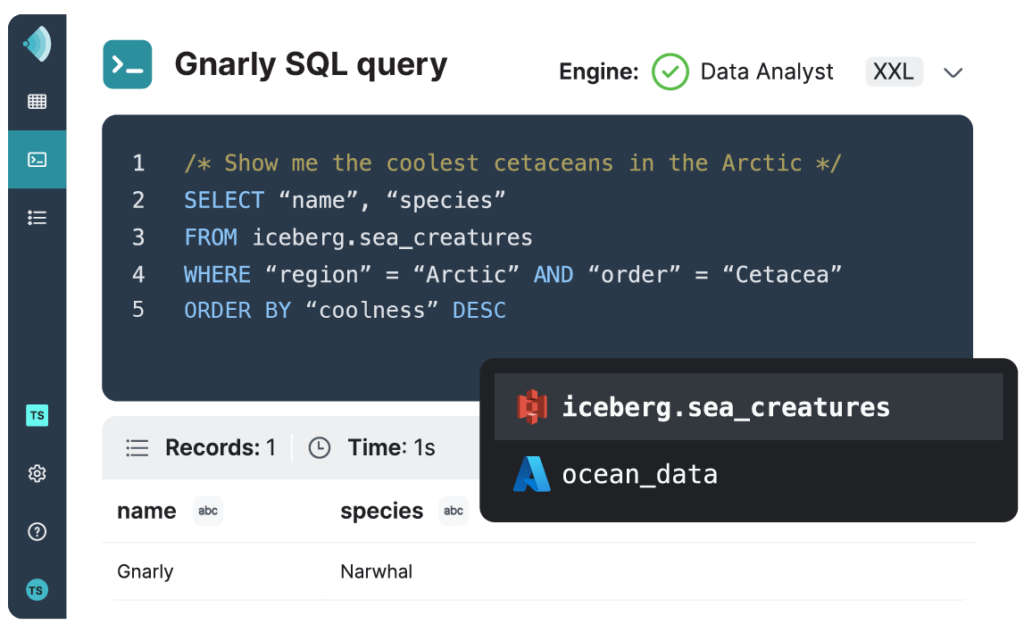
Sonar’s SQL Runner interface enables analysts to query data through features like auto-complete, multi-statement execution, and script sharing. Sonar’s SQL Profiler can analyze and optimize query performance, while Sonar’s Data Map offers dataset usage and lineage visualization for a comprehensive understanding of your data. Overall such features allow users to perform complex analytics on large datasets quickly and efficiently.
With strong G2 scores (4.7 of 5 stars) overall, some reviews express concerns about performance, limited database connectors, and the user interface. These items have continued to evolve overtime and improve.
Azure Data Lake Storage
Azure Data Lake Storage (ADLS), offered by Microsoft Azure, is another prominent data lake vendor and particularly compelling for businesses who already use or are considering Azure services. The newly released Data Lake Storage Gen2 isn’t a dedicated service or account type, but rather is implemented as a set of capabilities that you use with the Blob Storage service of your Azure Storage account.
What sets ADLS apart from its competitors is its focus on enterprise-grade security, data governance, and compliance features. ADLS provides built-in data encryption, granular access control policies, and comprehensive auditing capabilities to help organizations meet stringent security and compliance requirements.
Furthermore, ADLS supports Azure Private Link, enabling secure and private access to data lakes over a private network connection, which is especially beneficial for organizations with strict data protection requirements.
However, there are certain drawbacks to consider with ADLS. Similar to other data lake vendors, its pay-as-you-go pricing model can lead to unexpected costs if not managed effectively. Additionally, organizations new to the Azure ecosystem may experience a learning curve when navigating the numerous services and configurations available.
Cloudera Data Platform
Cloudera offers a comprehensive data lake solution with its Cloudera Data Platform (CDP), built on top of open-source technologies such as Hadoop, Spark, and Hive. Cloudera stands out for its focus on enterprise-grade security, governance, and compliance features, as well as its support for hybrid and multi-cloud deployments.
CDP can be complex, as the platform’s broad range of technologies and configurations can be challenging to manage, particularly for organizations with limited expertise in big data or open-source technologies.
Teradata VantageCloud
Teradata offers a comprehensive data lake solution through its VantageCloud platform. VantageCloud is a multi-cloud environment that simplifies data management tasks by providing a unified data access layer that allows users to query data across different sources without having to move or replicate data, reducing complexity and improving performance.
The platform shines for its powerful analytics capabilities, which include advanced SQL, machine learning, and graph analytics.
However, VantageCloud may not be as ideal as other data lake vendors for organizations dealing primarily with unstructured data or requiring extensive support for open-source technologies like Hadoop and Spark. The platform is proprietary and doesn’t have the same level of integration and support for open-source technologies compared to other data lake vendors.
Oracle Cloud Infrastructure
Oracle’s long-standing reputation in the database management and enterprise software space make it a necessary inclusion within this list of data lake vendors. Its Oracle Cloud Infrastructure (OCI) Data Lake platform supports various data formats, including structured, semi-structured, and unstructured data, has robust security features, and also supports popular open-source technologies such as Apache Spark, Apache Kafka, and Hadoop. Not to mention seamless integration with the Oracle ecosystem.
However, organizations should carefully consider pricing and integration challenges before choosing Oracle as their data lake vendor. Expect to experience some level of vendor lock-in too, which can limit flexibility if you decide to switch to another cloud provider or adopt a multi-cloud strategy in the future.
Vertica Unified Analytics Platform
Vertica is another of the data lake vendors focused on high-performance analytics. Its columnar storage architecture allows for efficient querying on large datasets, integrates with a wide range of data sources, and supports advanced analytics including machine learning and geospatial analytics.
Vertica also offers a hybrid deployment model, supporting on-premises, cloud, and multi-cloud environments. Besides managing the platform yourself, you can also run Vertica-as-a-service.
Build your data lake with data quality in mind
The data lake landscape offers a diverse range of solutions, each with its unique benefits and drawbacks. Our strong recommendation for data teams is to evaluate data lake vendors on the platform’s data management and overall integration capabilities.
Data lakes on the more structured “lakehouse” side of the spectrum will give your team the most flexibility by allowing them to integrate with the governance, data quality, and other modern data stack solutions critical to success today.
For example, data lakes with query logs that can be accessed by Monte Carlo, enable end-to-end data observability.
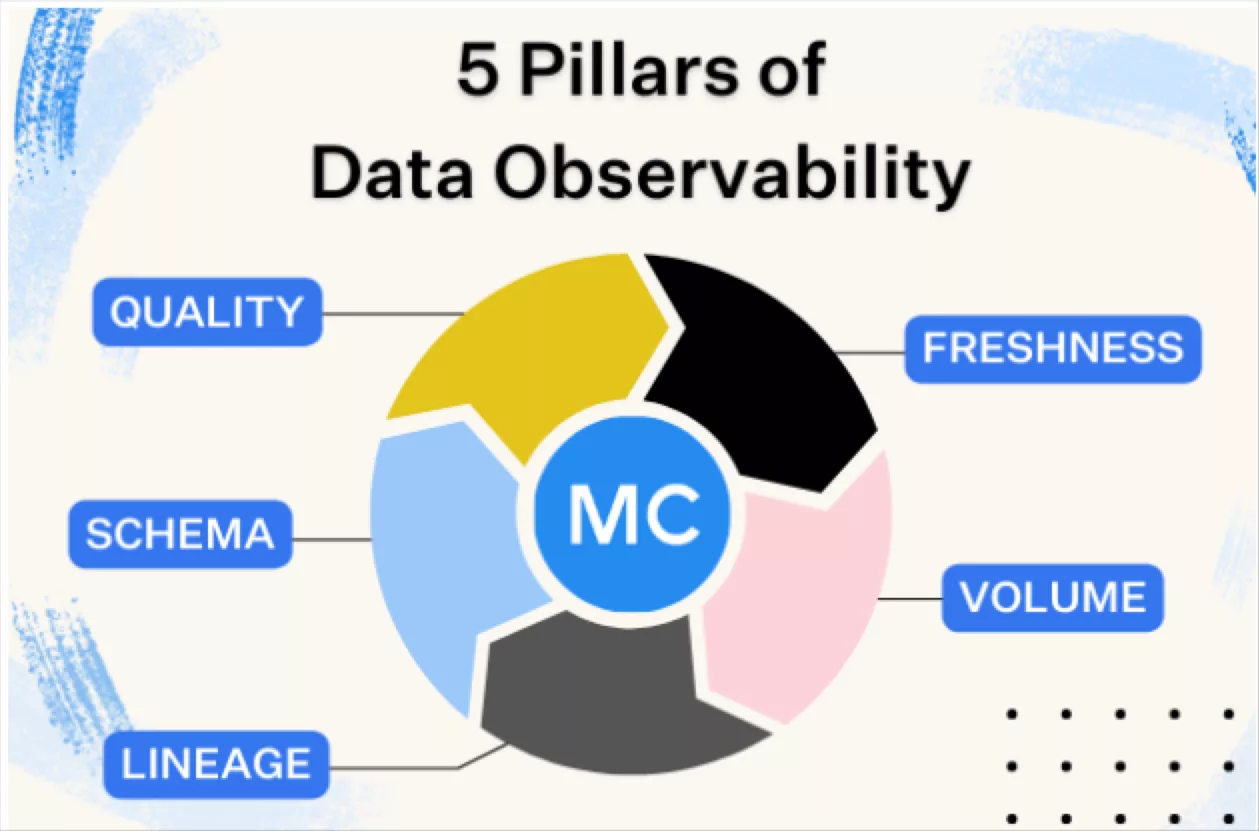
Data observability uses automated monitoring, root cause analysis, data lineage and data health insights to detect, resolve, and prevent data anomalies. Maintaining the quality of your data ultimately allows you to make well-informed decisions and gain valuable insights from your data lake.
Bring data quality to your chosen data lake vendor by requesting a demo of our data observability platform by filling out the form below:
Our promise: we will show you the product.
Read more posts.