Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is Data Discovery: Definitions & Overview

Michael Segner
Michael writes about data engineering, data quality, and data teams.
In the world of data engineering, data discovery refers to the ability to find relevant data sets across your data platform and understand their context. Data discovery makes data engineering and analytical engineering tasks more efficient and can enable self-service access for other types of data consumers.
Just like knowledge workers need to tap into a shared repository to discover and combine relevant information across documents or slide decks, data professionals need to do the same with data assets such as tables, models, and dashboards.
The same challenges exist across both use cases as well. Without enough context, users can grab the wrong asset (or wrong version), spend hours trying to find what they need, or be unable to determine the owner/expert who can provide additional value to their task.
Data discovery is a broad term and is used by other fields to mean different things. For privacy, security, and compliance teams, for example, data discovery is the ability to scan collaboration data to identify, classify, and protect sensitive data, particularly the misuse of personal identifiable information (PII).
Others use the term more loosely to describe the process mainly done by analytics engineers or data analysts to prepare, visualize and report on large amounts of data to draw insights and correlations. Data discovery is also frequently confused with data mining, which is the process of scraping and extracting open source data, like websites, at a large scale. A common data mining use case would be to scrape a site like Amazon to provide ecommerce retailers data and insights on item stock and pricing levels online.
In this article, we’ll discuss the benefits, highlight the trends, and answer common questions around data discovery as it relates to the ability to find and understand relevant data assets. We will also get into some of the trends in this space including the emergence of data discovery tools, automated data discovery, and more.
Table of Contents
Data discovery benefits
One of the main benefits of data discovery is that it allows data engineers and others involved in the ETL process to be sure they are leveraging the most up-to-date (and often, correct) data set for a given use case.
Once your organization’s operations start to exceed 50 tables or so, even the most experienced data engineers start to lose their mental map of the entire ecosystem. That’s because it’s one thing to remember 50 discrete items, it’s another to understand the purpose and connections between them all. Furthermore, without strong data discovery capabilities it takes longer for new members of the data team to onramp and become familiar with the environment.
Data discovery also plays a key role outside of the data team. One of the most strategic initiatives of any organization is to become more data-driven or to accelerate data democratization. For these initiatives to succeed, robust data self-service is a must…and data discovery capabilities (along with documentation) are foundational to that effort.
When data teams unlock data self-service access they also unlock additional capacity within their team. Now data engineers spend less time acting as a personal guide to the data platform and more time adding value to the business.
Data discovery challenges
If data discovery and self-service was easy, then every data team would be doing it. There are several challenges that must be overcome including:
- No one likes writing documentation: We have decades of experience to show that no one, whether they are a software engineer or a data engineer, likes writing documentation. Even in the best case scenarios (they are rare) with strong enforcement and policing mechanisms in place there are gaps. Documentation tasks are typically outside of the normal workflow and there is just too much work to be done. This is why automated data discovery tools are so helpful.
- There is a chasm between data producers and consumers: Data is constantly in motion and there is typically a gap between those who produce it and those who consume it. This means that the producer is typically not thinking how to make data assets or products as usable or as discoverable as possible. Ironically, data discovery systems and mechanisms like data contracts can be extremely helpful to bridge this chasm.
- Data literacy: Data discovery depends on making data sets easily accessible and usable, but it also depends on consumers who have the capability to know how to surface it and how to use it effectively once they have done so. Analytics engineers occupy a relatively new role on the data team, which is specifically designed to cover the last mile between data in its raw state and in a more accessible, usable form.
- Ad-hoc reporting never dies: You can have great data discovery in place, but keep in mind there will always be that executive who needs a new report on a unique set of metrics yesterday. These ad-hoc requests can be dramatically reduced with good data discovery, but rarely eradicated–such is life.
- Organizational alignment: Strong data discovery means having strong lines of ownership across the organization for each data asset. It also means creating a shared understanding of what certain metrics mean and how they are used. This is where the data mesh (more on this later) and decentralizing the data team, can really help to reduce these gray areas of overlap and make the process more agile.
Data discovery 101 and building understanding
Now that we understand the benefits and challenges of data discovery, let’s dive into some of the best practices.
While “providing context to understand data sets” is easy to say, it’s much more involved in reality. To do so, you need to answer the “who, what, when, where, why” of data.
- Who: Who owns and is accountable for this table? Who is an expert about this table and the processes it’s involved in? Who is impacted if this table has an issue?
- What: How is this data organized, what it’s schema? What are the requirements or service level agreement to which it’s being held? Is it high data quality?
- When: How frequently is this data updated or accessed? When does it need to be delivered? When were the last changes or modifications made and by who?
- Where: Answering this question isn’t as easy as it seems. Data isn’t static and stored in a single table or system, it flows like water. It also has a lot of dependencies, if there is a leak upstream, everything downstream is impacted. This is why data lineage, understanding how different data assets are connected from source system to final consumption, is so critical.
- Why? What business process does this data contribute to? How does it add value? What is the business logic behind it?
Of course the context and relevance changes based on who is consuming the data and what they are trying to do with it. A data engineer is likely going to be more focused on data lineage and reliability, but an analytics engineer may be more concerned with the schema and the frequency of read/writes.
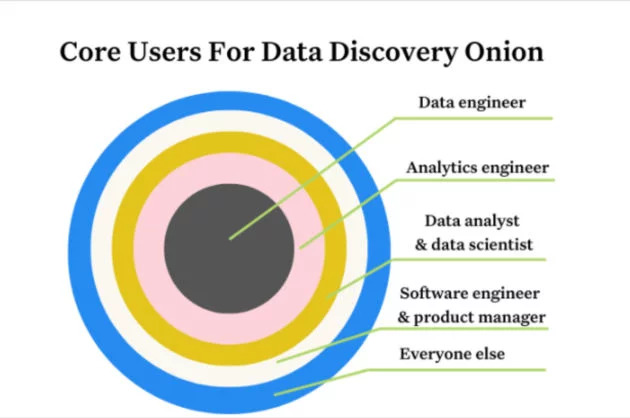
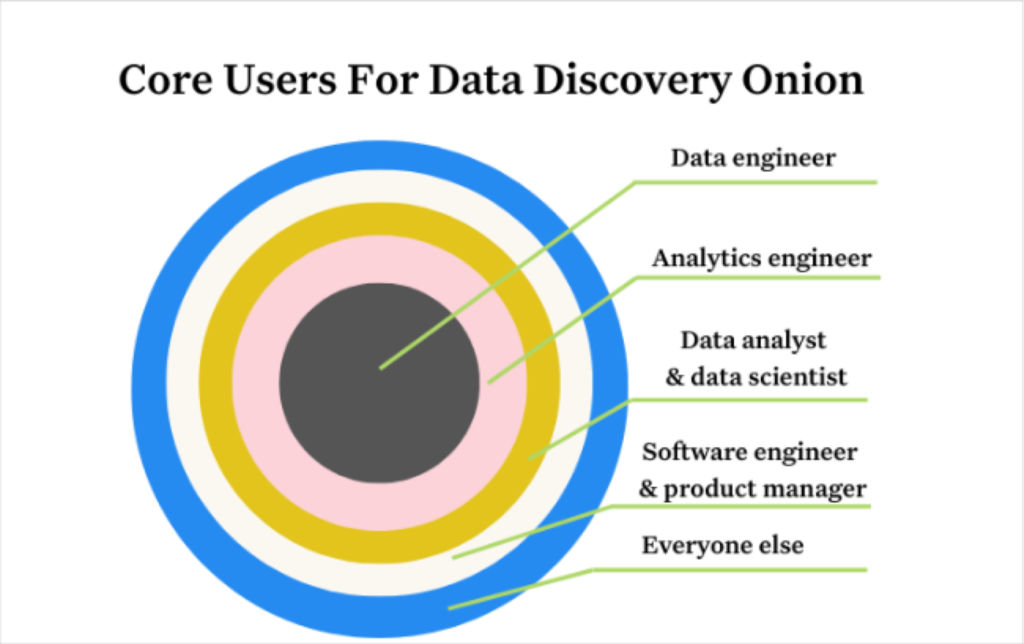
The best data discovery tools will answer these questions within a clean interface that prioritizes user experiences according to the data consumer onion. At the core are data engineers, the practitioners manipulating data in its rawest form everyday.
Then, that data is consumed by analytics engineers who clean it up to make it more usable for the next layer of consumers which are data scientists and data analysts. Next come data power users and stakeholders, such as software engineers and product managers followed by your everyday business consumer.
Data discovery and the data mesh
The concept of data discovery is aligned with the distributed domain-oriented architecture proposed by Zhamak Deghani and Thoughtworks’ data mesh paradigm of data management.
Data discovery works well when different data owners are held accountable for their data as products, as well as for facilitating communication between distributed data across different locations. Once data has been served to and transformed by a given domain, the domain data owners can leverage the data for their operational or analytic needs.
Data discovery can provide domain-specific, dynamic understanding of your data based on how it’s being ingested, stored, aggregated, and used by a set of specific consumers. Governance standards and tooling are federated across these domains (allowing for greater accessibility and interoperability).
Data discovery tools
Data discovery tools come in four basic flavors: discovery only, data observability, data catalog, and homegrown.
There are some solutions that focus exclusively on data discovery with an emphasis on the democratization of data. These are similar to the homegrown solutions at mega-tech companies like Meta, Airbnb, and Uber.
More often though, you will see data observability capabilities as part of a larger solution with automated data lineage such as data observability or a data catalog. Each have their own flavor, and we’ve weighed in on how data teams should prioritize a data observability vs data catalog decision.
The difference between the two is the emphasis and additional capabilities that come with the rest of the platform. For example, Monte Carlo builds our data lineage and data discovery capabilities with data engineers in mind to prevent data incidents and accelerate their resolution whereas a catalog’s discovery capabilities are more designed for a steward to help their cataloging and governance activities.
A data observability platform also features real-time data monitoring and alerting capabilities to ensure your data is trustworthy and reliable. As Datanami points out, data catalogs provide a lot of value from their ability, “to provide a bridge between how business talks about data and how that data is technically stored. Nearly every data catalog in the market–and there are close to 100 of them now–can do that.”
We’ve previously (and perhaps controversially) written that data catalogs are dead, and that’s partly due to the emergence of data discovery and data observability.
The future of data discovery
Through a combination of smart data discovery tools and automation, it’s easier than ever to ensure your data team has the context they need to find and effectively use data assets across your ecosystem.
And that, in a nutshell, is the answer to the question: “what is data discovery?”
Keep in mind that creating new categories and types of tooling is an iterative process; we have no doubt that what data discovery looks like will continue to change as data volumes grow, the pursuit of real-time analytics continues, and artificial intelligence improves. Balancing speed and reliability remains vital, as does the need for proper governance and compliance with regulatory measures.
Did we miss something? Feel free to leave your thoughts in the comments below.
Interested in learning about how data observability can help your team make the most of their data discovery investments? Schedule time with us by filling out the form below.
Our promise: we will show you the product.
Read more posts.