Product demo.
Product demo.  What is data observability?
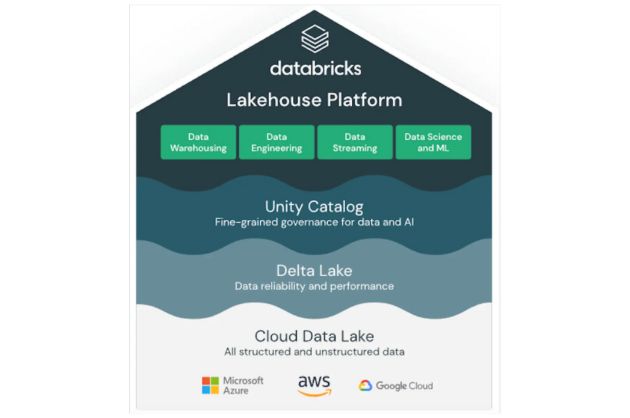
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 8 Data Ingestion Tools (Quick Reference Guide)


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time?
The growing field of data ingestion tools offers a range of answers, each with implications to ponder. There’s the dichotomy between batch and streaming, between all-in-one platforms and niche connectors in your modern data stack, and the trade-off between ease-of-use and powerful customization options.
One thing’s for certain: you definitely don’t want to be writing pipelines in Python anymore. Times have changed and there are better ways of doing things now.
Let’s explore what to consider when thinking about data ingestion tools and explore the leading tools in the field.
Table of Contents
What to consider when choosing a data ingestion tool
At its core, a data ingestion tool automates the process of importing data from disparate sources into a single, accessible location such as a data warehouse, allowing for more effective data management, analysis, and reporting.
Choosing one tool over another isn’t just about the features it offers today; it’s a bet on the future of how data will flow within organizations.
To help you identify the most suitable data ingestion tool for your organization, use the score card below when evaluating each tool’s functionality and its alignment with your data management needs.
| Consideration | What to Look For |
| Integration Capabilities | Support for a diverse array of data sources and destinations, ensuring compatibility with your data ecosystem. |
| Batch vs. Streaming | Assess if your data processing leans towards real-time analytics or if batch processing suffices for your use case. |
| Scalability | Tools should offer scalability to handle growing data volumes without significant additional investment. |
| Ease of Use | Look for intuitive interfaces and good documentation to minimize onboarding time and technical support needs. |
| Cost | Evaluate the total cost of ownership, including setup, maintenance, and scaling costs, against the tool’s features. |
Let’s navigate through the top contenders in this space using this scorecard.
Fivetran
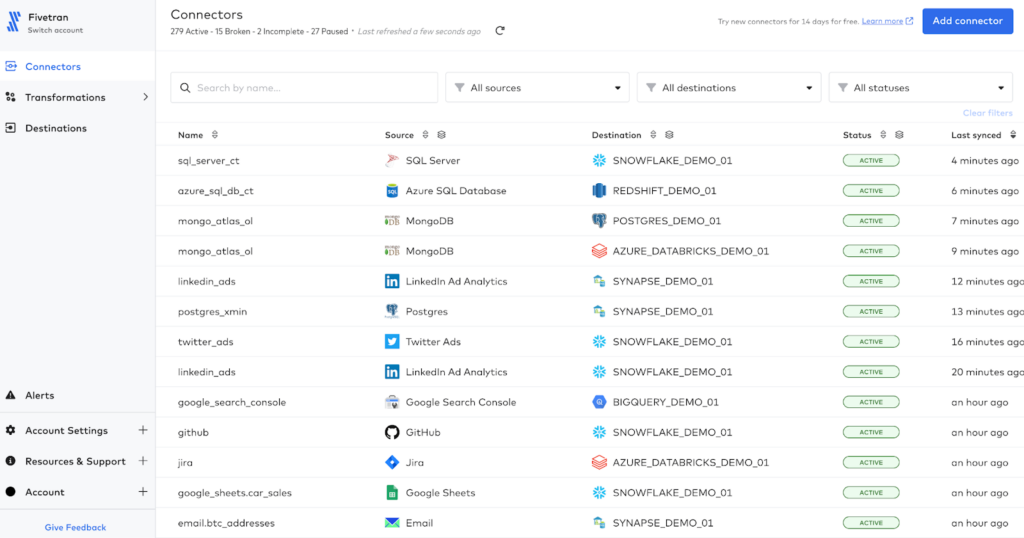
Fivetran is the leader in the data ingestion space, known for its ease of use and extensive connector ecosystem.
- Integrations: They offer a wide array of connectors for databases, SaaS applications, cloud storage solutions, and more, covering both popular and niche data sources.
- Batch vs Streaming: They focus on automated batch data integration but also support near real-time data replication for certain sources.
- Scalability: Cloud-native architecture ensures that as your data volumes grow, Fivetran can automatically adjust to maintain performance.
- Ease of Use: Known for its user-friendly interface, extensive docs, and large community.
- Cost: Pricing is based on the volume of data ingested, with transparent pricing tiers to suit different organizational sizes and needs. Their pricing guide estimates two users on their starter plan would run $6,056 per year.
Bottom Line: While not the cheapest option on the market, its ease of use and extensive connector support offer a high value for the investment, particularly for organizations looking to minimize engineering overhead.
Apache Kafka
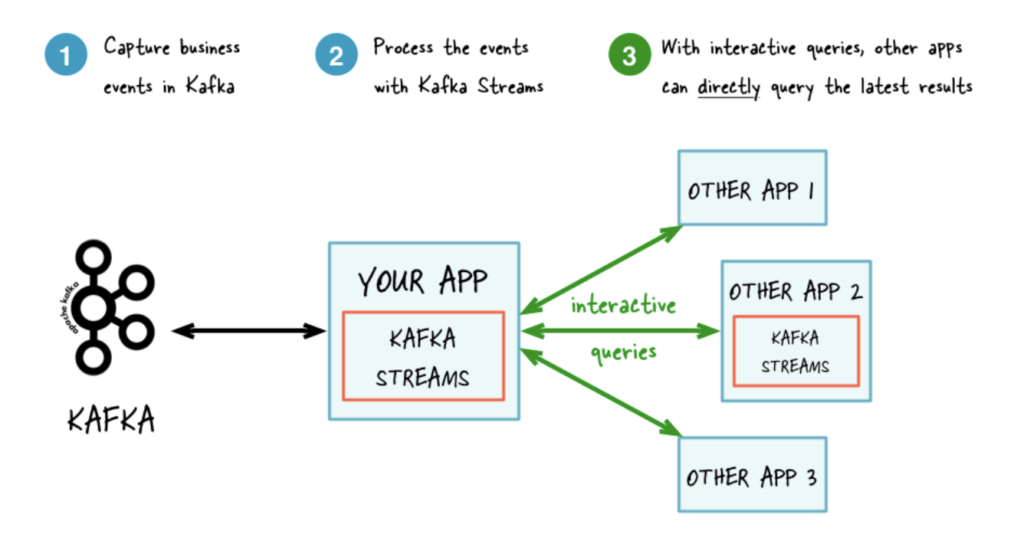
Apache Kafka is a powerful distributed streaming platform that acts as both a messaging queue and a data ingestion tool. It’s used by thousands of organizations from internet giants to car manufacturers to stock exchanges.
- Integrations: Kafka doesn’t come with pre-built connectors like other tools but offers Kafka Connect, a framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems.
- Batch vs Streaming: Designed for real-time data streaming, Kafka excels in scenarios requiring high throughput and low latency.
- Scalability: Kafka’s distributed architecture allows it to scale out and handle very large volumes of data across a cluster of servers, making it highly scalable and resilient.
- Ease of Use: Kafka is known for its robustness and performance rather than its ease of use. It has a steeper learning curve compared to tools like Fivetran. Extensive documentation and a large, active community are available though.
- Cost: It’s open-source software, so free. However, operational costs, including servers and management, should be considered. If you don’t want to manage everything yourself, there are managed Kafka services, such as Confluent Cloud, that offer Kafka as a service with various pricing plans based on usage.
Bottom Line: Apache Kafka is ideal for organizations requiring a high-performance, scalable system for real-time data streaming and processing. While it offers significant power and flexibility, it demands more in terms of setup and management compared to more user-friendly, plug-and-play solutions. Its cost-effectiveness will depend on your ability to manage its operational complexities efficiently.
Matillion
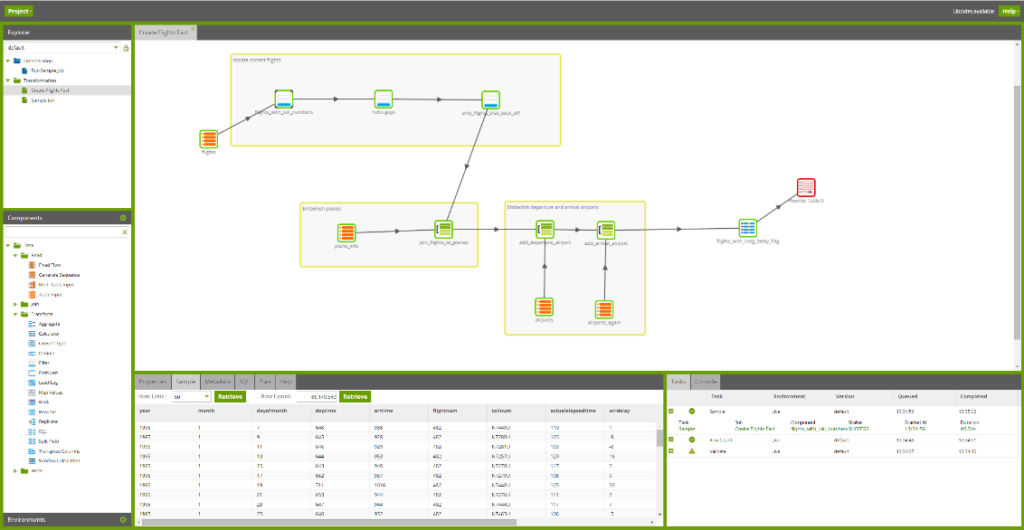
Matillion is an all-in-one ETL solution that stands out for its ability to handle complex data transformation tasks in all the popular cloud data warehouses.
- Integrations: Provides a wide range of pre-built connectors for both cloud and on-premises data sources, including databases, SaaS applications, CRM and ERP systems, social media platforms, and more.
- Batch vs Streaming: Primarily focuses on batch data processing, optimized for the transformation and loading phase of ETL within cloud data warehouses.
- Scalability: As a cloud-native solution, Matillion scales efficiently with your cloud data warehouse, leveraging the cloud’s elastic resources to handle varying data volumes and complex transformation workloads.
- Ease of Use: Known for its drag-and-drop interface along with visual job orchestration, allowing users to design, develop, and manage ETL jobs without extensive coding.
- Cost: Pricing is based on the computing resources consumed (instance hours) and the cloud data warehouse environment, offering flexibility and control over costs.
Bottom Line: Matillion’s strength lies in simplifying data transformations and loading processes in the cloud. While its focus on batch processing suits most data warehousing needs, businesses requiring extensive real-time streaming capabilities might need to complement it with other tools.
Amazon Kinesis
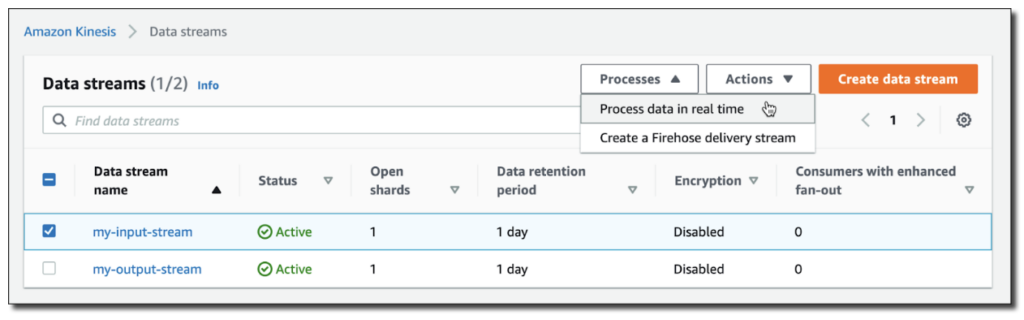
Amazon Kinesis is a platform within Amazon Web Services (AWS) designed to collect, process, and analyze real-time, streaming data.
- Integrations: Natively integrates with a wide range of AWS services, including Amazon S3, Amazon Redshift, Amazon DynamoDB, and AWS Lambda, facilitating seamless data flow within the AWS ecosystem. It also offers SDKs and APIs for custom integrations.
- Batch vs Streaming: Specializes in real-time data streaming, providing tools to easily collect, process, and analyze streaming data at scale.
- Scalability: Highly scalable, allowing users to scale their streaming data processing up or down without managing infrastructure.
- Ease of Use: Offers a user-friendly console and APIs, but requires some AWS knowledge and understanding of streaming data concepts for effective use.
- Cost: Uses a pay-as-you-go pricing model, charging based on the volume of data ingested and processed, as well as the resources used for data storage and processing.
Bottom Line: Kinesis excels in scalability and integration within AWS services. However, its cost and ease of use may require careful planning and you’ll need AWS expertise to optimize for specific use cases.
Airbyte
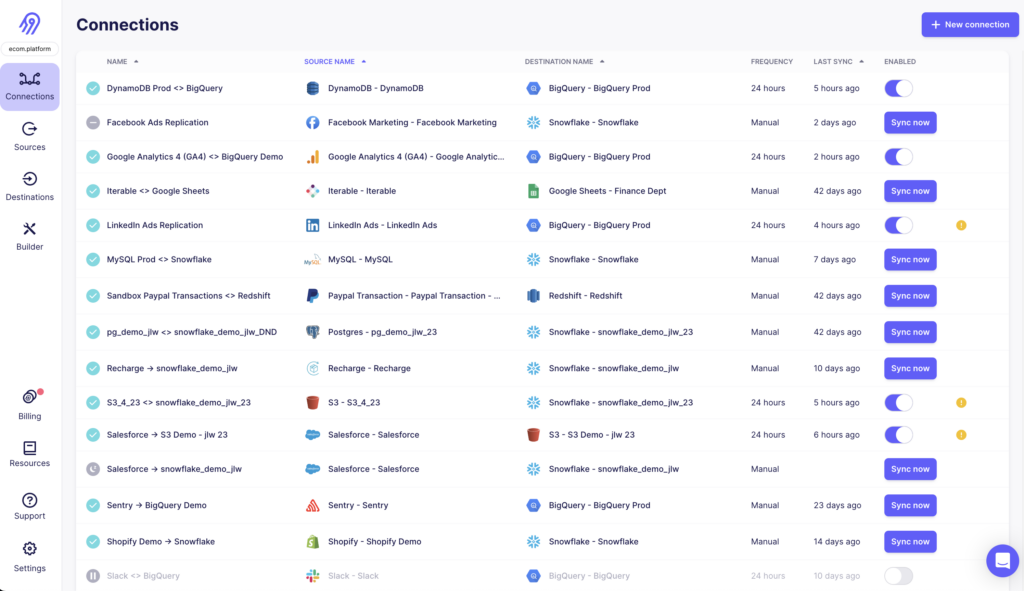
Airbyte is an open-source tool gaining popularity for its flexibility and growing number of connectors, including support for long tail connectors.
- Integrations: Provides an extensive connector library plus its open-source nature encourages the community to contribute new connectors, continuously expanding its integration capabilities.
- Batch vs Streaming: Only batch data integration and the minimum cadence for syncs is 5 minutes.
- Scalability: Designed to scale with your data needs. The self-hosted option allows for scalability based on the underlying infrastructure, while the cloud version manages scalability for you.
- Ease of Use: Features a user-friendly web UI for configuring and managing data pipelines, making it accessible to users without deep technical expertise. There’s detailed documentation and a community forum to aid in troubleshooting.
- Cost: The self-hosted version of Airbyte is free to use, with costs associated with the infrastructure it runs on. Airbyte Cloud offers a usage-based pricing model, charging for the volume of data replicated.
Bottom Line: Airbyte shines in its broad connector support, self-hosted option, and community-driven development. Look elsewhere if you need real-time streaming capabilities though.
Apache NiFi
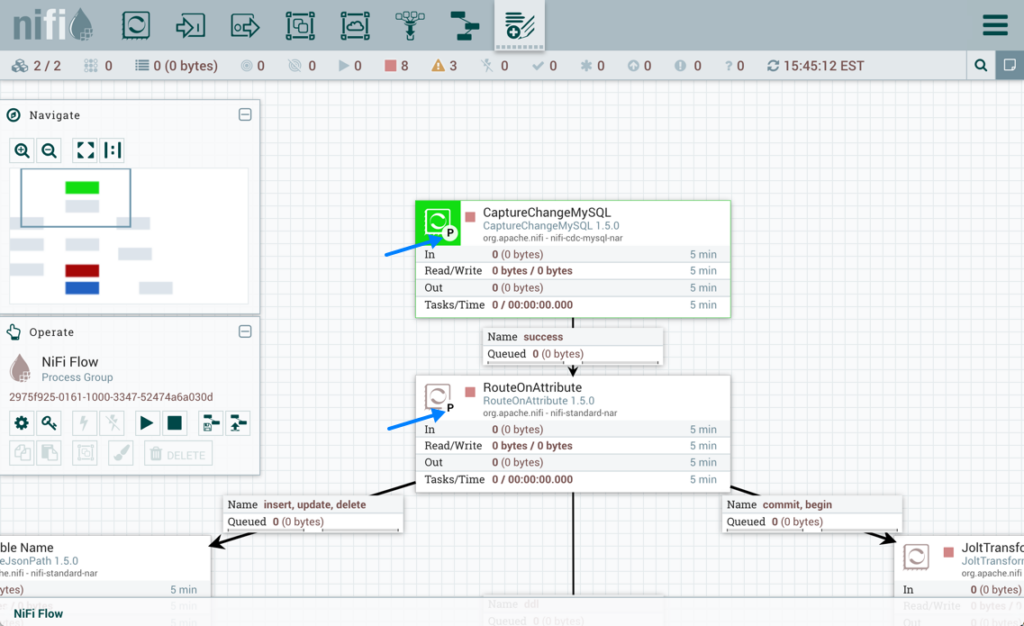
Apache NiFi focuses on automated data flow between systems, supporting both streaming and batch processing with a user-friendly interface.
- Integrations: Offers a wide range of pre-built processors for various data sources and destinations. Its extensible architecture allows you to develop custom processors too.
- Batch vs Streaming: Capable of handling both batch and real-time data flows, NiFi provides fine-grained control including backpressure and prioritization.
- Scalability: Designed to scale out in a cluster configuration, allowing for high availability and parallel processing of data flows across multiple nodes.
- Ease of Use: The intuitive web-based user interface facilitates the design, deployment, and monitoring of data flows without requiring advanced programming skills.
- Cost: As an open-source project, NiFi can be used freely. However, operational costs will depend on the infrastructure it runs on, whether self-hosted or cloud-based. Managing and scaling NiFi, especially in large deployments, may require investment in hardware and personnel.
Bottom Line: NiFi is well-suited for organizations that require robust, scalable data flow automation with a focus on real-time data processing. Its wide range of integrations, combined with the ability to handle both batch and streaming data, not to mention its open-source nature, makes it a flexible choice for diverse data ingestion needs.
Stitch
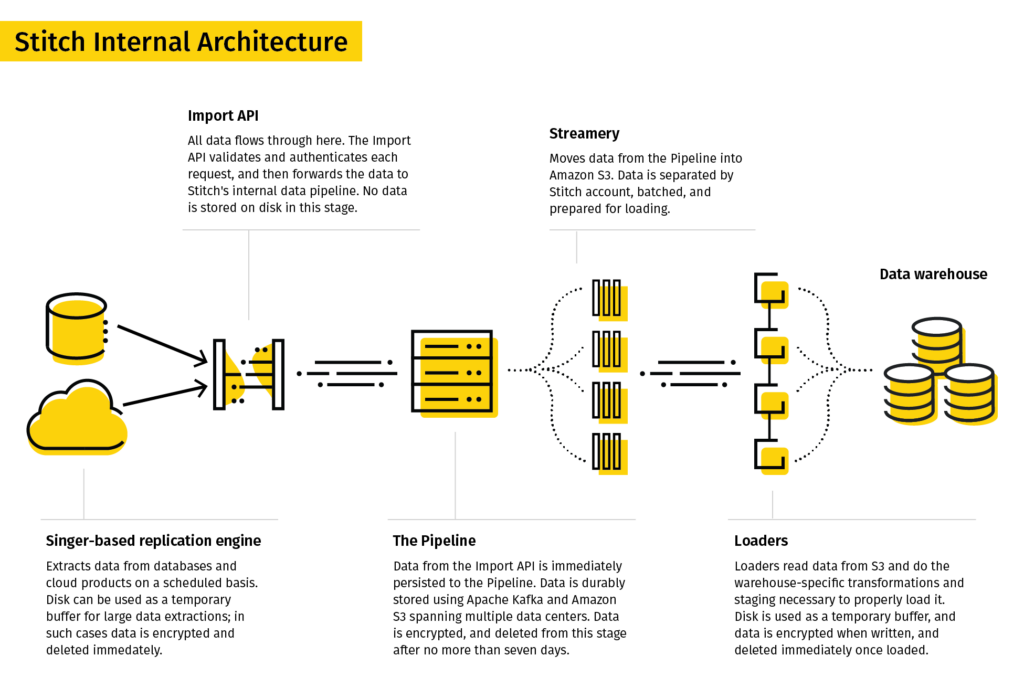
Stitch is a simple, powerful ETL service for businesses of all sizes to quickly move data.
- Integrations: Offers an extensive catalog of pre-built integrations and continuously expands its library of integrations, focusing on the most popular and widely used data sources.
- Batch vs Streaming: Operates on a batch processing model, designed for regular, scheduled ETL jobs to move data into a warehouse. While not a real-time streaming solution, Stitch can be configured for frequent data loads, minimizing latency and providing near real-time data availability.
- Scalability: As a managed service, Stitch scales automatically to accommodate data volume growth, with different pricing tiers based on usage.
- Ease of Use: Known for its user-friendly interface and straightforward setup process. Stitch has detailed documentation and a support team to assist.
- Cost: Charges based on the number of rows of data ingested into the destination. There’s also a free tier with limited rows per month.
Bottom Line: Stitch is a simple, effective way to set up ETL pipelines without the need for extensive data engineering resources. While it may not offer real-time streaming capabilities, its frequent data loading options provide a practical compromise for many use cases.
Google Cloud Dataflow
Google Cloud Dataflow is a fully managed, serverless service for stream and batch data processing within the Google Cloud Platform (GCP).
- Integrations: Seamlessly integrates with other GCP services, including Google Cloud Storage, BigQuery, Pub/Sub, and Datastore. It offers connectors for external data sources too.
- Batch vs Streaming: Supports both batch and streaming data processing natively, allowing developers to build flexible pipelines that can handle varying data volumes and latencies.
- Scalability: As a fully managed service, Dataflow automatically scales resources up or down based on the workload.
- Ease of Use: Dataflow is built on the open source Apache Beam project. You use the Apache Beam SDK to build pipelines for Dataflow. While powerful, Beam has a learning curve, but extensive documentation and community support are available.
- Cost: Uses a pay-as-you-go pricing model based on the resources consumed and costs can be optimized by leveraging Google’s recommendations for pipeline optimization and cost management.
Bottom Line: Dataflow is an ideal solution for organizations deeply invested in the Google Cloud Platform.
The journey doesn’t end with data ingestion tools
Once you solve data ingestion, the most important consideration is data quality. As data ecosystems grow in complexity, having a robust data observability strategy becomes indispensable for maintaining a steady stream of reliable, high-quality data all the way through your pipelines.
Data observability tools like Monte Carlo complement data ingestion by offering automated monitoring and resolution of data issues, thus ensuring reliability and building data trust across your organization.
To see how data observability can transform your data management practices, request a demo with Monte Carlo today.
Our promise: we will show you the product.
Read more posts.