 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Table-Level vs. Field-Level Data Lineage: What’s the Difference?

Sara Gates
Sara is a content strategist and writer at Monte Carlo.
Over the last few years, data lineage — a metadata map that visualizes the relationship between upstream and downstream dependencies in data — has skyrocketed in popularity. Data teams can use lineage to understand their data and, when data incidents occur, more quickly identify data products, assets, and consumers that may be impacted.
But, not all data lineage is created equal. Even though many data warehouses and tools are tacking lineage onto their offerings, it’s crucial for data teams to understand the different kinds of data lineage, and what actually empowers better root cause analysis and time-to-resolution.
So in this article, we’re going to take a fresh look at lineage, specifically: what’s the difference between table-level lineage and field-level lineage? And how does all of this relate to data observability?
Table of Contents
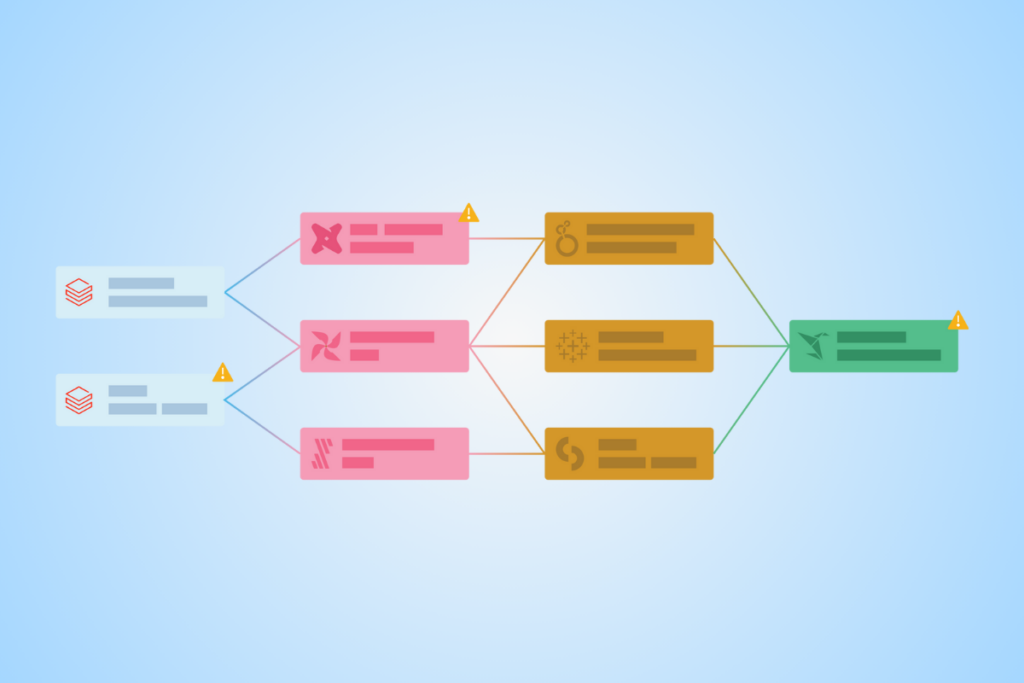
What is table-level data lineage?
Table-level lineage is just that: lineage that extends to the table level, and illustrates how tables within a data environment relate to one another.
Data teams can use table-level lineage to visualize and gain a basic understanding of how a given table has been formed, and how it maps to other tables.
But — and this is a big but — table-level lineage doesn’t reveal anything about the data within the table. It provides no information about the specific content or transformations that occur within the columns of the table.
What is field-level data lineage?
Field-level lineage — also known as column-level lineage — maps a dataset’s entire journey from ingestion, through every transformation it undergoes, until it reaches its final form in reports and dashboards. It traces the relationships across and between upstream source systems (like data warehouses and data lakes) and downstream outputs (like analytics reports and dashboards).
The granular visibility of field-level lineage allows data engineers not only to see which tables are involved, but also to understand precisely how data is modified, aggregated, or filtered at each step.

What’s the difference between table-level lineage and field-level data lineage?
The key difference between table-level lineage and field-level lineage lies in the depth of detail each provides. While table-level lineage reveals the paths between tables, field-level lineage delves into the specifics, showing how data is processed and utilized within the tables.
For instance, let’s say a data consumer reports that an important monthly sales report looks off. With table-level lineage, a data engineer can start investigating and see that the ‘Sales Transactions’ table feeds into the ‘Monthly Sales Summary’ table. That’s useful — but it doesn’t tell them which specific columns are involved, or how transformations like summations or categorizations are applied during the update process.
But, with field-level lineage, that data engineer can pinpoint exactly which columns in the ‘Sales Transactions’ table are critical inputs into the calculations for the sales report and understand how the data is transformed step-by-step across the pipeline. By examining the detailed transformations and data flows, the engineer can identify where the process broke down — say, a recent change in an ETL script incorrectly handled date formatting, excluding certain transactions from the final report.
This is why field-level lineage is essential to data observability. When data quality incidents occur, data engineers can use field-level lineage to trace the root cause back to its source — and conduct impact analysis to understand what downstream dependencies may be affected.
Field-level lineage also gives data teams the ability to understand what data is most valuable to their organization. They can easily identify if data is linked to a downstream report before deprecating outdated columns, tables, or assets. Table-level lineage can identify a few upstream dependencies, but field-level lineage will pinpoint the precise field in the singular table that impacts the one data point in a pertinent report. This significantly narrows the scope of the data team’s analysis.
How field-level data lineage enables better root cause analysis
In a modern data system, incidents of data downtime can manifest in numerous ways across an entire pipeline and impact dozens — if not hundreds — of tables. Figuring out the root cause of data downtime is incredibly complex.
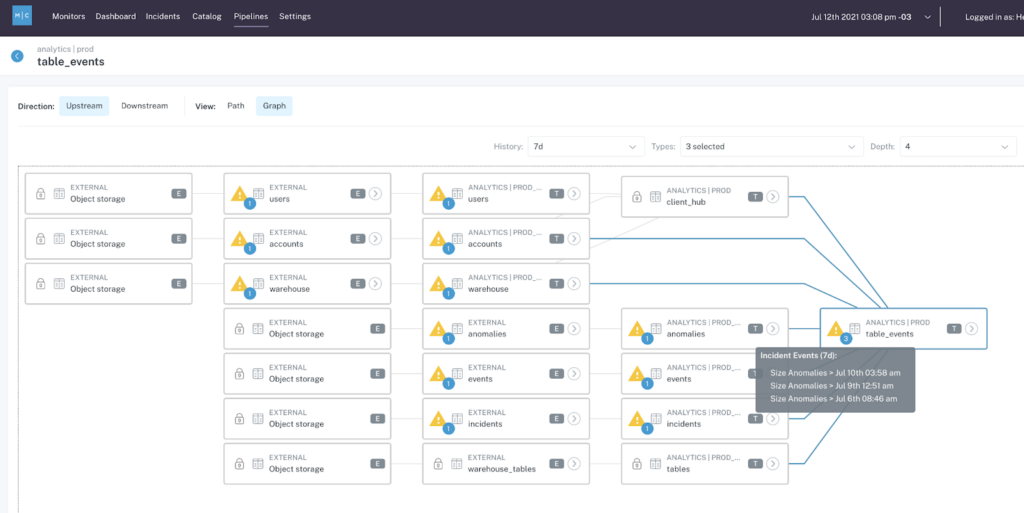
But field-level lineage is an invaluable tool data teams can use to identify what happened, why, and what other assets have been impacted. That’s why looking at field-level lineage is the first step in root cause analysis. It helps teams identify where a data quality incident occurs, often by visualizing the most upstream table where the issue is still present.
Once a team knows the most upstream table with an anomaly, they can dive deeper into root cause analysis — looking into not just where an incident occurred, but why.
Field-level lineage provides the granularity teams need to zero in on the specific impact of code, operational, and data changes that impact downstream fields and reports. Issues like failed ETL jobs, logic or schema changes, or operational issues like infrastructure failures or runtime errors can all be the culprit behind data downtime. And those are incredibly difficult to diagnose across multiple systems without field-level lineage and observability.
At Vox Media, Senior Product Manager Vanna Triue relies on the automated field-level lineage within the Monte Carlo platform to provide end-to-end visibility across their data systems.
“Lineage is by far my most favorite feature of Monte Carlo,” Vanna says. “If something does break for whatever reason, you can see how it impacts things across the life cycle review. So, whether it’s closer to the warehouse or all the way through to your dbt models or your analytics systems, you can see how breakages impact all the parts of your data stack.”
Data engineers can also rely on field-level lineage to surface and identify the most important and widely used downstream reports or data products. They can proactively notify teams of compromised or unreliable data and prioritize fixing the most impactful data pipelines, improving the efficiency of RCA and reducing time to resolution.
In action: Resident uses data lineage and data observability to reduce data issues by 90%
Before implementing data observability and lineage, the data engineering team at direct-to-consumer mattress brand Resident was constantly dealing with data downtime. Stakeholders, data consumers, and occasionally the CEO of the company would Slack the data team with questions about broken dashboards or inaccurate data. The data team was left to resolve those issues manually, relying on memory and basic tools. That led to duplicated views and processes, and the team didn’t have a clear understanding of what fields or tables affected downstream data consumers.
So when the Resident team learned about the Monte Carlo data observability platform and automated end-to-end lineage, it was a game-changer. As Daniel Rimon, Resident’s Head of Data Engineering, says, ““It takes me nothing to maintain this lineage. If I want some advanced monitoring, I can define that, but nothing is required for me to get this level of lineage. It’s the dream.”
To create the lineage graph, Monte Carlo automatically parses the SQL out of the query logs in BigQuery, and extends the lineage through a connector to Looker and Github. The lineage automatically updates as the data evolves. And Daniel’s favorite use case is a table called “Admin Orders”, which contains all the information about orders.
“This is my favorite table, and I can see a lot of information about how it behaves, like the other tables and views that feed it,” she says. Daniel can understand what changes were made in the past and see the downstream views that will be affected by changes to Admin Orders, and what Looker dashboards are ultimately connected to her table, so she can collaborate with her analysts and engineers to understand the impact of any changes.
“Because they built those views—not me,” said Daniel. “We can collaborate together and make sure we prevent data disasters before we make them.”
Since implementing Monte Carlo, Resident’s data team has seen a 90% decrease in data issues, and restored trust in data across the organization. So long, late night Slack alerts.
How data observability empowers data lineage
Lineage is one of the five pillars of data observability. Along with freshness, quality, volume, and schema, lineage plays an integral part in providing full visibility into the health of an organization’s data and data systems — so the data team can be the first to know when the data is wrong, what broke, and how to fix it.
Observability involves automated monitoring and alerting to detect when incidents occur, and these functions are crucial to reducing time to detection — knowing that something’s wrong with the data in your system. But lineage is required to answer vital questions about where an outage occurred, what upstream sources and downstream ingestors were impacted, and which teams are generating and accessing the data. Observability tooling also helps teams prioritize and route alerting based on usage and ownership, reducing the very real threat of alert fatigue.
Automated data observability tooling delivers the most robust, end-to-end data lineage available. Because in order for lineage to be truly useful, it can’t be limited to your data catalog or cloud storage tooling — it has to encompass every integration point and layer of the data stack. How did changes in dbt models impact your data quality? Did a failed Airflow job create a freshness issue? Are you using a multi-cloud environment? Any of these instances require the automated end-to-end lineage provided by observability.
Let’s be real: for today’s data teams, table-level lineage is table stakes. Organizations that really want to drive value with data need field-level lineage that reduces time-to-resolution and speeds up root cause analysis — including data streaming lineage and rich, in-depth orchestration lineage.
Data lineage has been part of the Monte Carlo platform since our inception, and we’ve been at the forefront of driving more advanced lineage capabilities. As the modern data and AI stack continues to evolve, we’re committed to helping teams create more value from data by unifying critical information from across systems into one cohesive mapping of data flows.
Want to learn how data observability and field-level lineage can help you deliver more reliable data? Let’s talk!
Our promise: we will show you the product.
Read more posts.





