Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What We Got Wrong About Data Governance


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Data governance is top of mind for many of my customers, particularly in light of GDPR, CCPA, COVID-19, and any number of other acronyms that speak to the increasing importance of data management when it comes to protecting user data.
Over the past several years, data catalogs have emerged as a powerful tool for data governance, and I couldn’t be happier. As companies digitize and their data operations democratize, it’s important for all elements of the data stack, from warehouses to business intelligence platforms, and now, catalogs, to participate in compliance best practices.
But are data catalogs all we need to build a robust data governance program?
Data catalogs for data governance?
Analogous to a physical library catalog, data catalogs serve as an inventory of metadata and give investors the information necessary to evaluate data accessibility, health, and location. Companies like Alation, Collibra, and Informatica tout solutions that not only keep tabs on your data, but also integrate with machine learning and automation to make data more discoverable, collaborative, and now, in compliance with organizational, industry-wide, or even government regulations.
Since data catalogs provide a single source of truth about a company’s data sources, it’s very easy to leverage data catalogs to manage the data in your pipelines. Data catalogs can be used to store metadata that gives stakeholders a better understanding of a specific source’s lineage, thereby instilling greater trust in the data itself. Additionally, data catalogs make it easy to keep track of where personally identifiable information (PII) can both be housed and sprawl downstream, as well as who in the organization has the permission to access it across the pipeline.
What’s right for my organization?
So, what type of data catalog makes the most sense for your organization? To make your life a little easier, I spoke with data teams in the field to learn about their data catalog solutions, breaking them down into three distinct categories: in-house, third-party, and open source.
In-house
Some B2C companies — I’m talking the Airbnbs, Netflixs, and Ubers of the world — build their own data catalogs to ensure data compliance with state, country, and even economic union (I’m looking at you GDPR) level regulations. The biggest perk of in-house solutions is the ability to quickly spin up customizable dashboards, pulling out fields your team needs the most.
While in-house tools make for quick customization, over time, such hacks can lead to a lack of visibility and collaboration, particularly when it comes to understanding data lineage. In fact, one data leader I spoke with at a food delivery startup noted that what was clearly missing from her in-house data catalog was a “single pane of glass.” If she had a single source of truth that could provide insight into how her team’s tables were being leveraged by other parts of the business, ensuring compliance would be easy.
On top of these tactical considerations, spending engineering time and resources building a multi-million dollar data catalog just doesn’t make sense for the vast majority of companies.
Third-party
Since their founding in 2012, Alation has largely paved the way for the rise of the automated data catalog. Now, there are a whole host of ML-powered data catalogs on the market, including Collibra, Informatica, and others, many with pay-for-play workflow and repository-oriented compliance management integrations. Some cloud providers, like Google, AWS, and Azure, also offer data governance tooling integration at an additional cost.
In my conversations with data leaders, one downside of these solutions came up time and again: usability. While nearly all of these tools have strong collaboration features, one Data Engineering VP I spoke with specifically called out his third-party catalog’s unintuitive UI.
If data tools aren’t easy to use, how can we expect users to understand or even care whether they’re compliant?
Open source
In 2017, Lyft became an industry leader by open sourcing their data discovery and metadata engine, Amundsen, named after the famed Antarctic explorer. Other open source tools, such as Apache Atlas, Magda and CKAN, provide similar functionalities, and all three make it easy for development-savvy teams to fork an instance of the software and get started.
While some of these tools allow teams to tag metadata within to control user access, this is an intensive and often manual process that most teams just don’t have the time to tackle. In fact, a product manager at a leading transportation company shared that his team specifically chose not to use an open source data catalog because they didn’t have off-the-shelf support for all the data sources and data management tooling in their stack, making data governance extra challenging. In short, open source solutions just weren’t comprehensive enough.
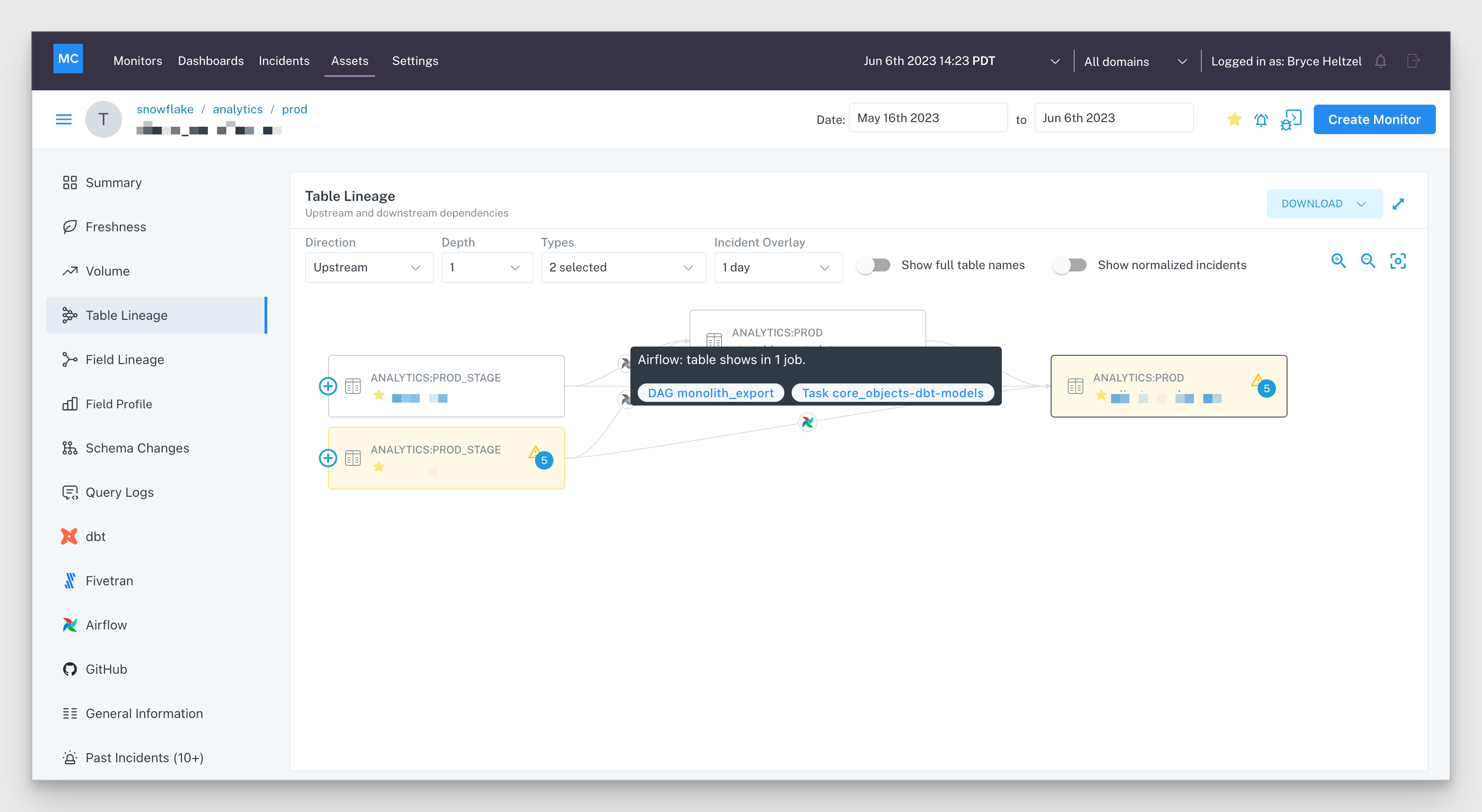
Still, there’s something critical to compliance that even the most advanced catalog can’t account for: data downtime.
The missing link: data downtime
Recently, I developed a simple metric for a customer that helps measure data downtime, in other words, periods of time when your data is partial, erroneous, missing, or otherwise inaccurate. When applied to data governance, data downtime gives you a holistic picture of your organization’s data reliability. Without data reliability to power full discoverability, it’s impossible to know whether or not your data is fully compliant and usable.
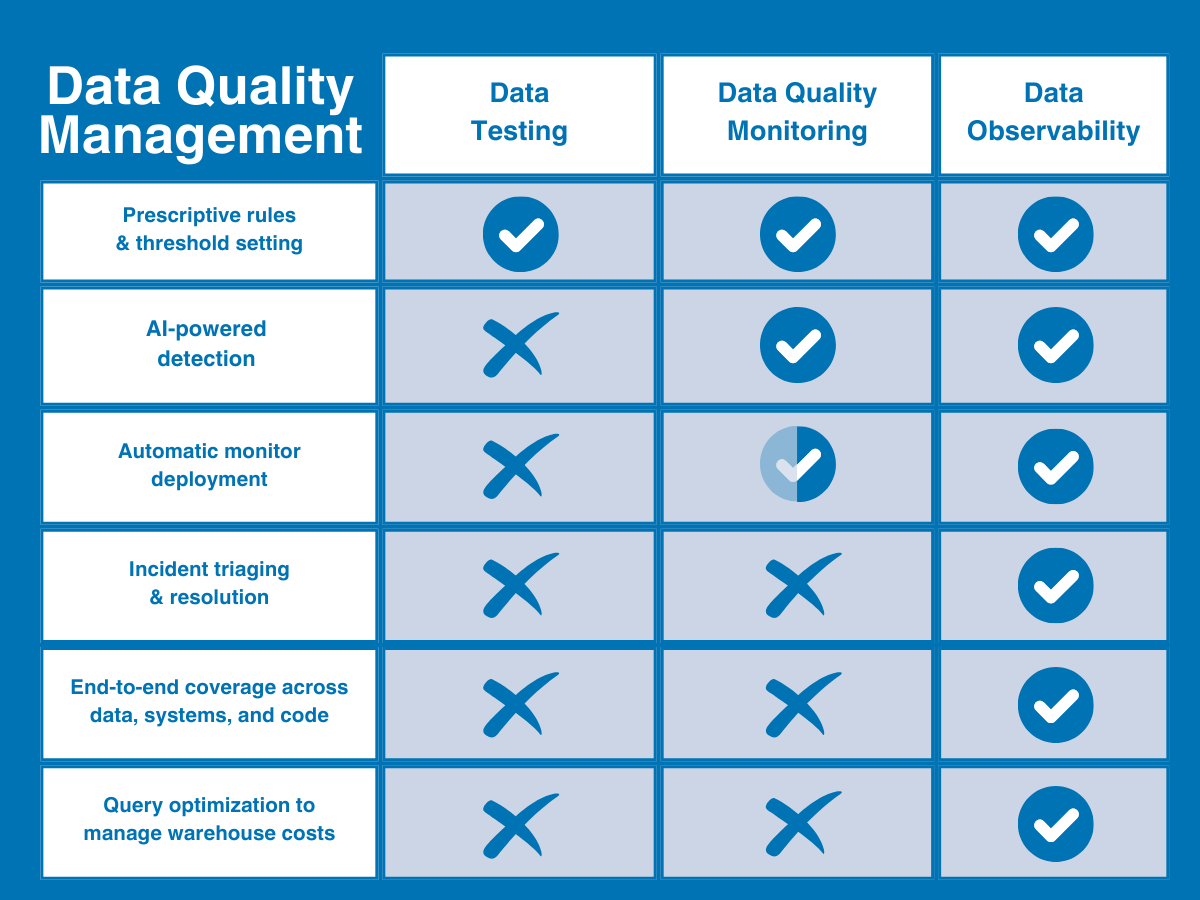
Data catalogs solve some, but not all, of your data governance problems. To start, mitigating governance gaps is a monumental undertaking, and it’s impossible to prioritize these without a full understanding of which data assets are actually being accessed by your company. Data reliability fills this gap and allows you to unlock your data ecosystem’s full potential.
Additionally, without real-time lineage, it’s impossible to know how PII or other regulated data sprawls. Think about it for a second: even if you’re using the fanciest data catalog on the market, your governance is only as good as your knowledge about where that data goes. If your pipelines aren’t reliable, neither is your data catalog.
Owing to their complementary features, data catalogs and data reliability solutions work hand-in-hand to provide an engineering approach to data governance, no matter the acronyms you need to meet.
Personally, I’m excited for what the next wave of data catalogs have in store. And trust me: it’s more than just data.
If you want to learn more, reach out to Barr Moses. Or book a time to speak with us below.
Our promise: we will show you the product.
Read more posts.