Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
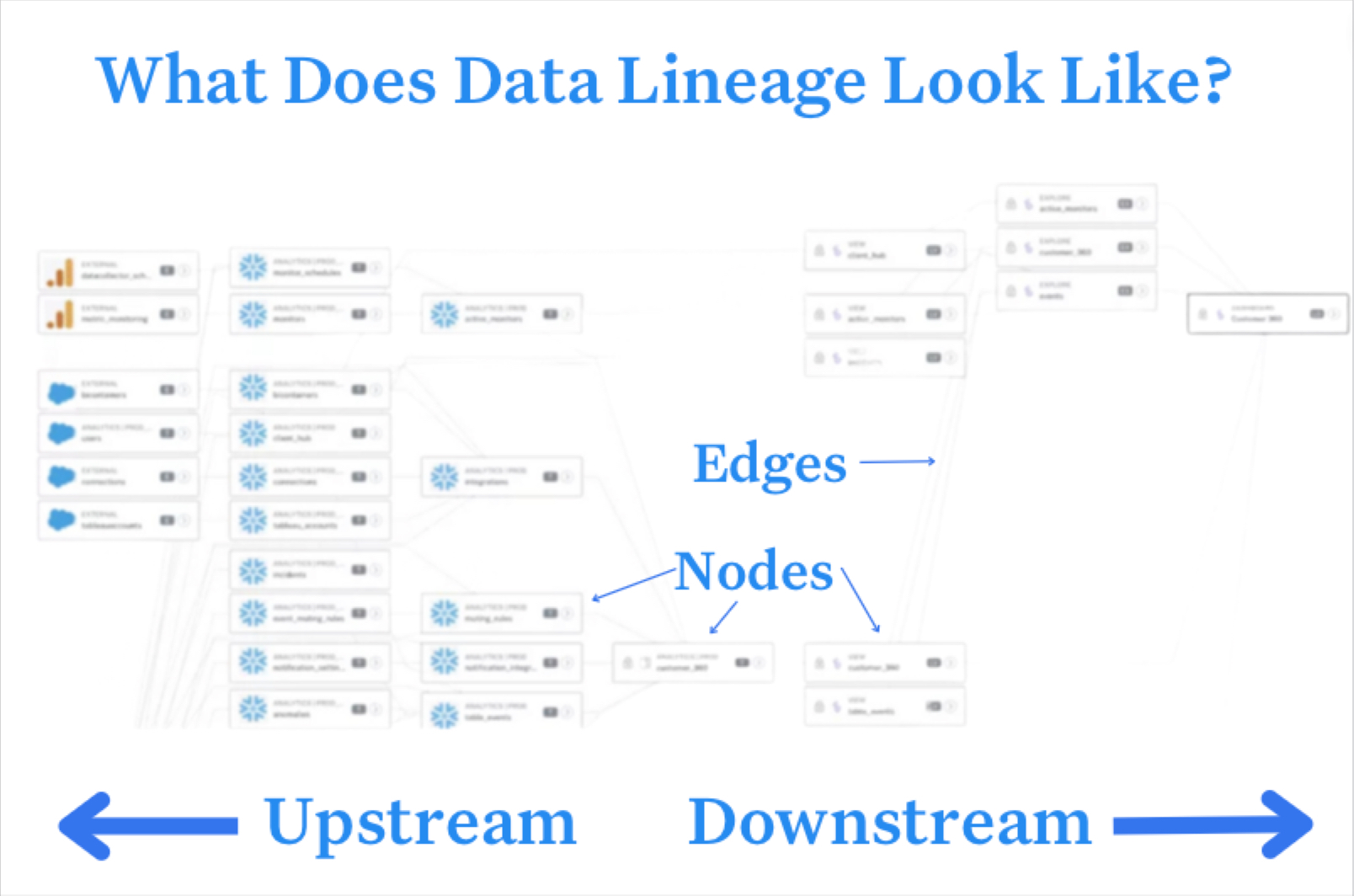
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Barr’s Top 5 Articles of 2023


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
This last year has been one of the craziest we’ve seen in the data space in some time. From a renewed fire around topics like contracts and governance and the endless march of progress in infrastructure tooling to the all consuming shadow of generative AI, 2023’s trending topics have come fast and furious.
For anyone following the data observability space over the last year, I shared quite a few articles on the hot-button topics that got me excited — from operationalizing data quality, to platform infrastructure, and — no surprise here — lots and lots of AI.
As we round out the year, here are 5 articles from 2023 that I think are worth a second look! Catch up on what you missed or double-click on some of my favorite topics.
1. The Next Big Crisis for Data Teams

Data leaders have responded to plenty of existential crises over the years, from the renewed scrutiny of “data-driven organizations” to operationalizing pipelines for practitioners.
But as the data landscape has shifted away from making our data as big as possible and toward delivering as much value as possible, one glaringly obvious issue rose to the surface…
Data leaders just aren’t close enough to the business.
Understanding and ruthlessly prioritizing the business needs of our stakeholders is paramount to facilitating data product adoption, proving the value of our data teams, and securing new investments in our infrastructures.
In this article, we discuss everything from asynchronous feedback loops to the semantic layer in an effort to help data teams inch closer to the business stakeholders they’re serving.
Check out all the juicy insights here.
2. The Moat for Enterprise AI is RAG + Fine-Tuning
Gone are the days of slapping together an API model for a “Chat-GPT but in the product” kind of novelty tool. The endless onslaught of useless AI features that were pumped out over the last 12 months made one thing very clear: for any Gen AI tool to be successful, it needs to solve a real problem.
Useful enterprise-ready AI doesn’t exist without clean, reliable context data to deliver differentiated value to consumers. Retrieval augmented generation (RAG) and fine-tuning enable data teams to leverage clean and curated business and customer data into their AI data products to provide tailored solutions to business problems.
In contrast to the undifferentiated AI widgets of 2023, GenAI tools that are enhanced by fine-tuning and RAG especially have the power to provide efficiency benefits where stakeholders can actually see real value. Just make sure you know where that data is coming from with a strong lineage solution and that you’ve validated the quality of your curated data with a robust data observability solution before it reaches production.
3. How to Build a 5-Layer Data Stack
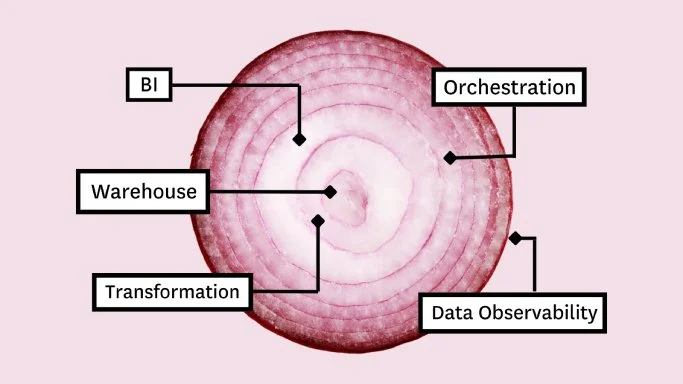
The most costly mistake data teams make when building their data stack?
Overcomplicating things.
Both data teams starting out and those moving from on-prem to the cloud have a plethora of “layers” to build nowadays. Instead of thinking about the problem in terms of “how many tools and layers can can I squeeze into this stack,” you should ask yourself this…
“How can I create a data platform that adds genuine value for stakeholders, while avoiding excessive complexity and unjustifiable expenses?”
In this article is a list of what I think are the 5 must-have layers every data leader needs to get the most value from their data stack.
– Storage / compute (warehouse / lake / lakehouse)
– Transformation
– Business intelligence
– Data observability / quality
– Orchestration
Read the full article.
4. 5 Generative AI Use Cases Companies Can Implement Today
Being tasked with implementing GenAI into your product roadmap? You’re not alone.
Tech giants like Google, Microsoft, and Amazon have already saturated the market with GenAI features, and everyone else is scrambling to catch up.
For this piece, we spoke with dozens of data and AI leaders at companies like OpenAI, Whatnot, and Vimeo to learn how they’re putting this technology to use today — from expediting knowledge work to democratizing data — and what it takes for a data team to implement gen AI at scale.
Special shout out to Yaniv Markovski for taking the time to chat for this piece!
It’s too much to cover in a summary, so check out the link below for all the secrets!
5. Data Ticket Takers or Decision Makers

I have yet to meet a data team that has more capacity than they do stakeholder demand. As highlighted in “The Next Big Crisis for Data Teams” the nature of data leadership demands ruthless prioritization.
Some data leaders will fall into the trap of focusing their time and resources based on who is loudest or which domains are making the most requests. The problem here is that — contrary to popular idioms — the customer doesn’t always know best.
IMO, there are two different types of data teams in this world: those who are reactive and those who are proactive.
Data ticket takers are told what the key metrics are by their consumers, they’re asked to develop reports tracking thos metrics, and then teams are built to create and maintain those dashboards.
Data decision makers on the other hand view dashboard creation and maintenance as a necessary bar to clear, but not the end-all-be-all of their value generating activities.
Now does that mean you put your foot down and every request and declare that your team is calling the shots from now on? Definitely not. Rob Parker, former senior director of data and analytics at Gitlab, said it well. “…we try to think about our customer’s customer. We’ve been able to move away from being the typical order taker into being a trusted business partner in the journey of building scalable and reliable solutions for the business.”
Wondering about data quality in the new year? Drop us a line below to chat with one of our data observability experts.
Our promise: we will show you the product.
Read more posts.