Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Contracts – Everything You Need to Know

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Most people in business are familiar with the concept of Service Level Agreements (SLAs), sometimes called Service Contracts. These written agreements outline the particulars of what a customer expects from a service provider, as well as what might happen if the service provider doesn’t meet those expectations.
Data contracts, often employed in a federated architecture, serve a similar purpose. Except, instead of referring to services, a data contract is an agreement between a service provider and data consumers. It refers to the management and intended usage of data between different organizations, or sometimes within a single company.
The aim? To ensure reliable and high-quality data that can be trusted by all parties involved.
But what is a data contract, and what does it look like?
Despite an intimidating name, data contracts aren’t as complicated as they first seem. And they can be incredibly helpful for improving accountability across data assets. Below, besides exploring what a data contract is, we’ll look at why they’re necessary, when to use them, and how to go about implementing them.
Table of Contents
- Why are data contracts required?
- What’s in a data contract?
- Who is responsible for data contracts?
- When should data contracts be implemented?
- What’s next for data contracts?
- Frequently Asked Questions
Why are data contracts required?
First things first, let’s think about why we need data contracts.
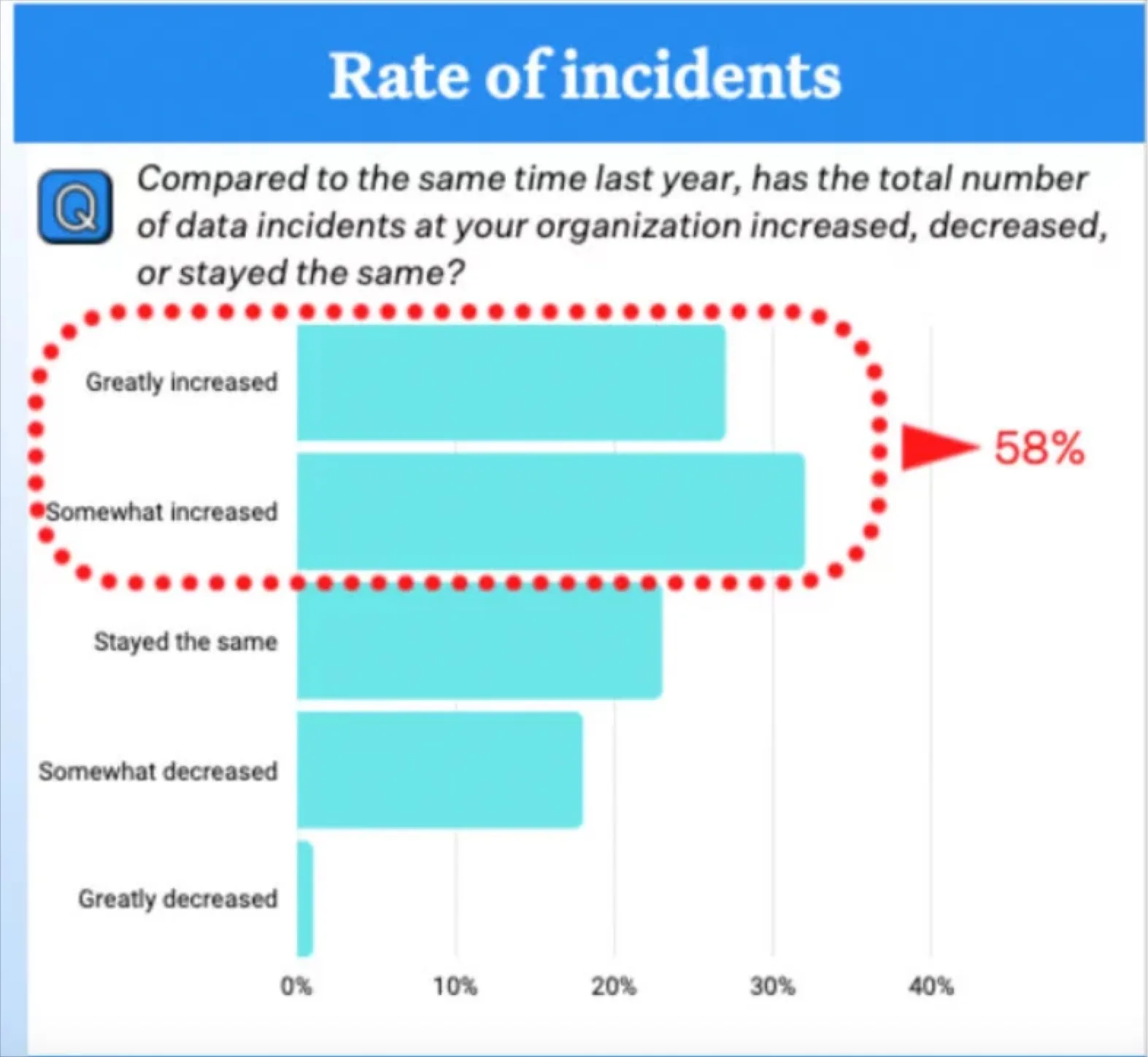
Data teams find themselves reliant on systems and services, often internal, that emit production data that lands the data in the data warehouse and becomes part of different downstream processes. However, the software engineers in charge of these systems are not tasked with maintaining and are often unaware of these data dependencies. So when they make an update to their service that results in a schema change, these tightly coupled data systems crash.
Another equally important use case is downstream data quality issues. These arise when the data being brought into the data warehouse isn’t in a format that is usable by data consumers. A data contract that enforces certain formats, constraints and semantic meanings can mitigate such instances.
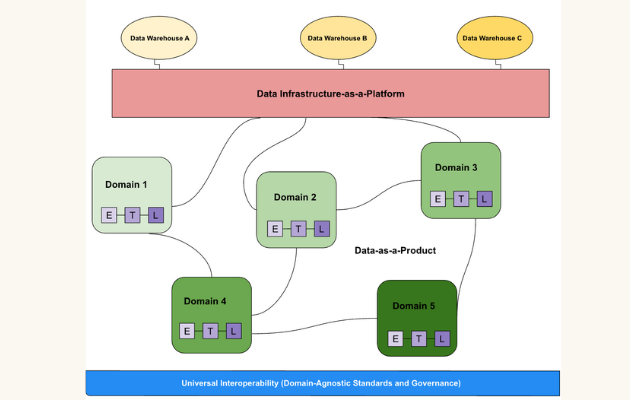
We know that organizations are dealing with more data than ever before, and responsibilities for that data are frequently distributed between domains; that’s one of the key principles of a data mesh approach.
The name can be a bit deceiving in this case – data contracts aren’t in-depth legal documents, but a process to help data producers and data consumers get on the same page.
The more widely distributed data becomes, the more important it is to have a solution in place that ensures transparency and builds trust between teams using data that isn’t their own.
What’s in a data contract?
For those who’ve never seen one, the idea of creating data contracts might be daunting. Fortunately, using them well is more about effective implementation than creating long and complex schemas. Once you’ve settled on an interchange format for a data contract, ensuring maximum readability, actually creating one can be as simple as a few lines of text.

For a closer look at an actual data contract template you can access the YAML file PayPal has open sourced on GitHub.
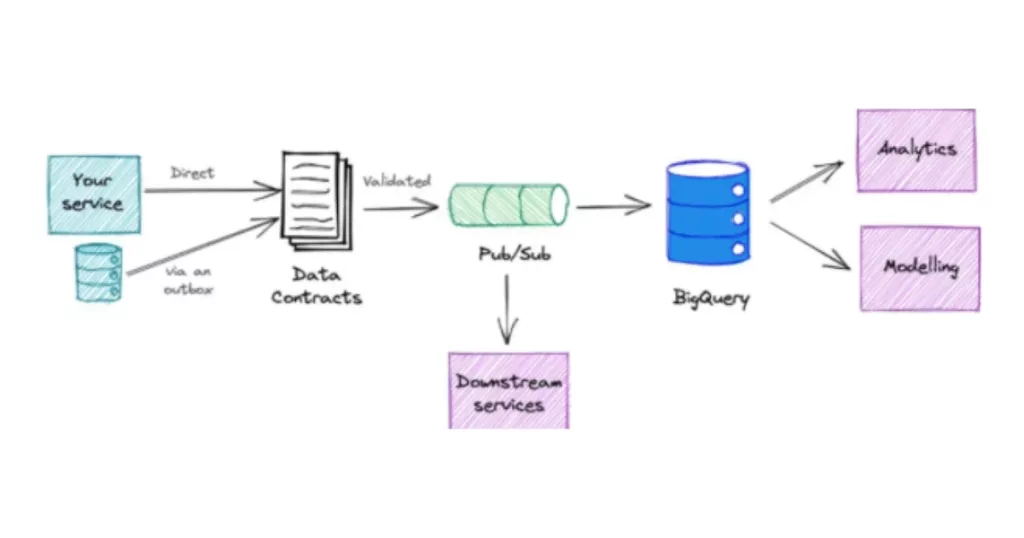
We won’t dive too deep into data contract architecture here, as we’ve covered that before; the article we just linked has some great insights from GoCardless’s Data Team Lead on how they implemented data contracts there.
We will, however, reiterate that data contracts might cover things like:
- What data is being extracted
- Ingestion type and frequency
- Details of data ownership/ingestion, whether individual or team
- Levels of data access required
- Information relating to security and governance (e.g. anonymization)
- How it impacts any system(s) that ingestion might impact
Because data contracts can differ substantially based on the type of data they refer to, as well as the type of organization they’re being used in, we haven’t yet seen a significant degree of standardization when it comes to data contract formats and content. A set of best practices may yet, however, emerge in the future, like we’ve seen with the OpenAPI Specification.
Who is responsible for data contracts?
Although they won’t necessarily be the ones implementing them, the decision to run with data contracts lies with data leaders. It’s worth pointing out, however, that they require input and buy-in from all stakeholders involved with the consumption of data.
Data consumers tend to be the most motivated participants as data contracts clearly make their lives easier. Data producers such as software engineers may need some convincing to show them how data contracts can benefit the organization and improve data quality without too much additional effort.
To this end, it can be worth pointing out data contracts are typically fairly evergreen and don’t need much ongoing maintenance. Aside from occasional version control tweaks and updates to contact details etc., they shouldn’t create a significant burden once they’re up and running.
When should data contracts be implemented?
You might assume that the answer to the question of when to implement data contracts would be “the sooner the better.” But let’s say that you’re still working on getting organizational buy-in for a data mesh approach. Adding data contracts into the mix might complicate matters, and comes with a risk of stakeholders being overwhelmed.
It could be worth making sure you have all your ducks in a row – stable and reliable data pipelines that are working smoothly – before delving into data contracts. On the other hand, in the article we linked above, GoCardless’s Andrew Jones suggests “if your team is pursuing any type of data meshy initiative, it’s an ideal time to ensure data contracts are a part of it.”
Of course, questions like “when should data contracts be implemented?” and “how long does it take to implement data contracts?” tend to have similar answers: in both cases, “it depends.” Jones goes on to say that:
“As of this writing, we are 6 months into our initial implementation and excited by the momentum and progress. Roughly 30 different data contracts have been deployed which are now powering about 60% of asynchronous inter-service communication events.”
In other words, this is not (nor does it have to be) an overnight process. And, when you do start, you can keep things simple. Once you’re armed with the knowledge you’ve collected from team members and other stakeholders, you can begin to roll out data contracts.
What’s next for data contracts?
Historically, data management within an organization has often been the responsibility of a dedicated team. Or, in some cases, the remit of just one plucky (and possibly overworked) data scientist. In such situations, data contracts weren’t really necessary to maintain order.
As organizations move towards a data mesh approach – domain-driven architecture, self-serve data platforms, and federated governance – that’s no longer the case. When data is viewed as a product, with different teams and sub-teams contributing to its upkeep, mechanisms to keep everything coupled and running smoothly are much more important.
The data contract is still a relatively new idea. They’re an early attempt at improving the maintenance of data pipelines, and the issues that come from breaking down a monolith, so we’ll probably see further iterations and other approaches emerge in the future.
For the moment, however, they might just be the best solution at our disposal for preventing data quality issues arising from unexpected schema changes.
+++
We highly encourage you to follow Andrew on LinkedIn and check out his website.
Thinking about data contracts also means thinking about how reliable your data is. To talk about data observability within your organization, schedule a time to talk with us below!
Our promise: we will show you the product.
Frequently Asked Questions
What are data contracts?
A data contract defines and enforces the schema and meaning of the data being produced by a service so that it can be reliably leveraged and understood by data consumers.
Despite what the name may suggest, data contracts are not the product of hard fought negotiations between data producers (typically software engineers who are responsible for the software or service emitting data) and data consumers (typically data engineers or data scientists tasked with handling and gleaning insights from data).
A data contract is a type of interface that operates in a similar transparent and versionable manner to how an API enables the reliable exchange of information between applications. While most data contract architectures are built for data operations within an organization, they can also be used as part of an external data sharing initiative.
The actual data contract itself is typically written in a templated interactive data language (IDL) such as Apache Avro or JSON. There is also a mechanism for decoupling the data architecture to avoid using production data or change data capture (CDC) events directly.
Why are data contracts important?
The most commonly cited use case for data contracts is to prevent cases where a software engineer updates a service in a way that breaks downstream data pipelines. For example, a code commit that changes how the data is output (the schema) in one micro-service, could break the data pipelines and/or other assets downstream. Having a solid contract in place and enforcing it could help prevent such cases.
Another equally important use case is downstream data quality issues. These arise when the data being brought into the data warehouse isn’t in a format that is usable by data consumers. A data contract that enforces certain formats, constraints and semantic meanings can mitigate such instances.
How do you use data contracts?
There are different data contract architectures and philosophies. One of the most effective implementations was built by Andrew Jones at GoCardless. The contract is in Jsonette, merged to Git by the data owner, dedicated BigQuery and PubSub resources are automatically deployed and populated with the requested data via a Kubernetes cluster and custom self-service infrastructure platform called Utopia.
Read more posts.