Product demo.
Product demo.  What is data observability?
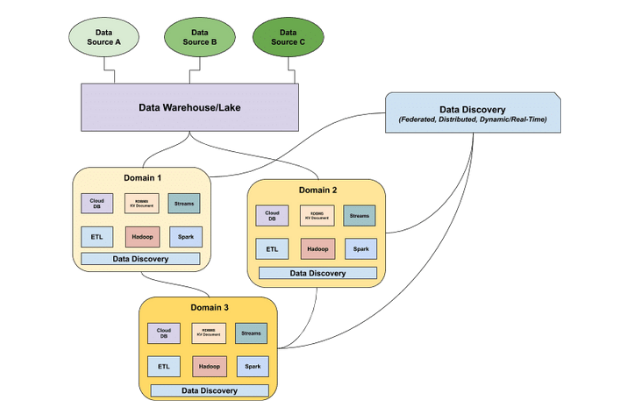
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 6 Tips For Better SQL Query Optimization

Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
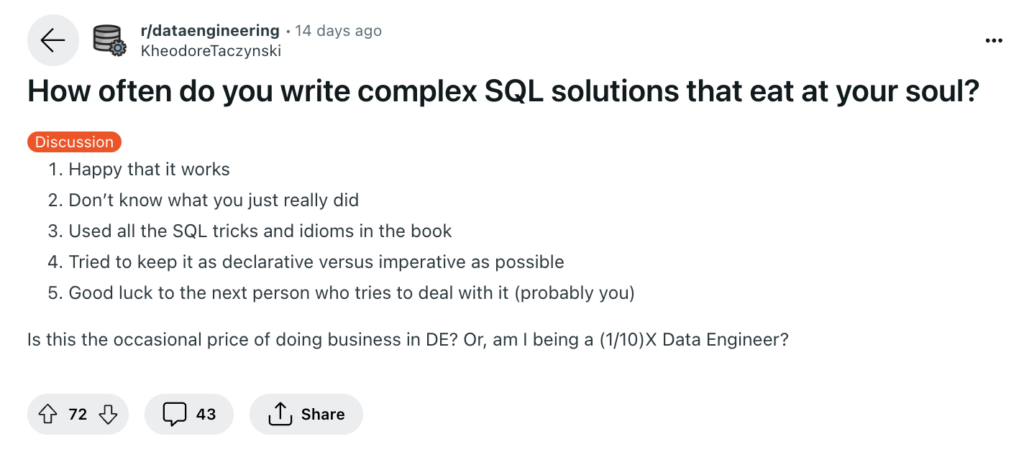
Knowing how to write effective SQL queries is an essential skill for many data-oriented roles. On one end of the spectrum, writing complex SQL queries can feel like a feat – even if it might feel like it’s “eating at your soul” during the process.
On the opposite side of the SQL spectrum is a strategy that’s potentially even more impressive – and useful – than long-winded, complex SQL strings:
SQL query optimization.
When your SQL queries are optimized, your compute resources are used more efficiently – and that leads to overall better performance and scalability in your database, while using less memory.
In short, more effective queries means better database resource management. And that means happier stakeholders downstream, especially on the finance teams.
In this article, we’ll cover seven best practices for optimizing SQL queries, and we’ll dive into how data observability can help teams monitor pipelines to maintain high-quality data as jobs run.
Table of Contents
What is SQL Query Optimization?
SQL query optimization refers to the process of ensuring your queries are running efficiently, resulting in reduced load times, less resource consumption, and higher performance of your database. Optimizing SQL queries also helps data teams identify and improve poor query performance.
The goal of SQL query optimization is improved database efficiency and performance, and that means minimizing the response time of your queries by best utilizing your system resources. At-a-glance, the goals of SQL query optimization are:
- Reduce response time
- Reduced CPU execution time
- Improved throughput
The more complex your queries, the more it can cost to run them. SQL query optimization ensures you have the lowest runtimes and the lowest costs, increasing your overall database efficiency.
Let’s dive into the seven best practices for improving SQL query optimization.
1. SQL Indexing
The first step is ensuring you’re using indexes effectively to map your tables. A SQL index is a data structure associated with a table or view that speeds up the retrieval of rows from the table based on the values in one or more columns. It’s kind of like a reference guide for your database that provides a way to locate rows that match the query criteria efficiently without scanning an entire table.
There are several types of indexes:
- Clustered index: Clustered indexes physically order the columns based on their actual values, so they’re only useful when the column values are in sequential or sorted order.
- Non-clustered index: Non-clustered indexes create two columns, one for the index and one for the value, typically used for mapping or glossary.
- Full-text index: Full-text indexes allow you to search through columns that are text-heavy.
- Unique index: A unique index ensures, you guessed it, that the values in the indexed columns across the table are unique.
- Covering index: A covering index is designed to “cover” a query by including all the columns needed to satisfy the query in the index.
- Filtered index: A filtered index is a non-clustered index with a WHERE clause, so it only includes a subset of rows in the table.
- Spatial index: Spatial indexes are specialized indexes used for spatial data.
- Columnstore index: Columnstore indexes organize data by columns, which can be beneficial for analytical queries.
Leveraging these types of indexes can help your data engineers, or any data team member querying the data with SQL, to locate the data in the tables more quickly. They essentially provide shortcuts. For example, an index would enable you to look for a match condition, rather than using a WHERE or JOIN clause.
When creating and managing indexes, you should be selective about the columns you choose to index, perform regular maintenance on your indexes, and avoid over-indexing to mitigate increased storage. In addition, it’s important to consider your clustered indexes carefully, taking into consideration access patterns and data distribution, and consider indexing tools and query execution plans to continue optimization.
2. Use SELECT Command to Filter
In order to optimize efficiency, try to refrain from using a SELECT*. Rather than viewing the fields you’re interested in, a SELECT* will mean you view all of the fields in a dataset – and that’s likely far too many.
Instead, select only the columns necessary to keep your models and reports clean.
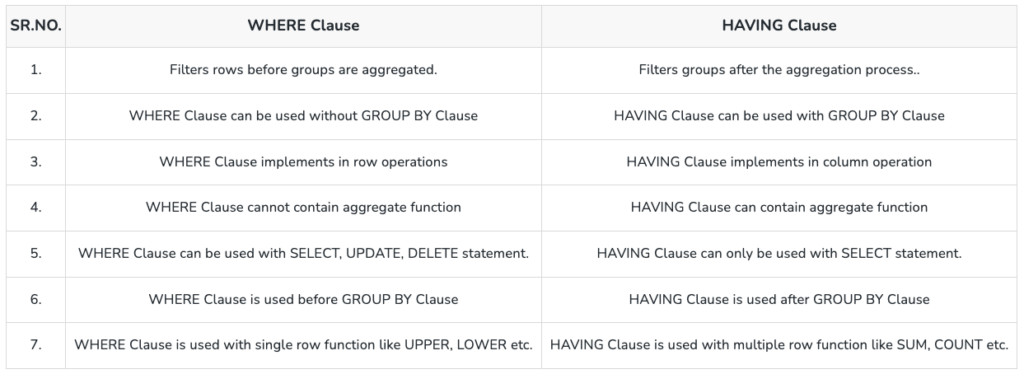
For example, consider a WHERE vs. HAVING clause. The WHERE clausing is used to filter to records from the table or used while joining more than one table before grouping or aggregating, and it can be used with SELECT DISTINCT, UPDATE, and DELETE statements. A HAVING clause is used to filter the records from the groups based on the given condition in the HAVING clause, and it’s applied after the grouping and aggregation of data.
By using SELECT DISTINCT and filtering with a WHERE clause, data stewards execute more efficient queries from the jump without viewing all the fields in the dataset.
3. Choose the Right Join Types
Choosing the right JOIN type is essential, and using the wrong type can slow down your dataset in a big way. There are several types of joins:
- Inner join: Inner joins return only the matching records from the two tables that you are joining.
- Outer join: Outer joins return matched and unmatched rows from both of the tables that you are joining. This is less common, so be sure you want to use this join!
- Left join: The query contains all values in the first table and only the matching tables in the second.
- Right join: The query contains all values from the second table and only the matching records from the first.
You also want to make sure you are joining two tables on a common field. If not, or you’re selecting a non-existent field, your query may run for much longer than intended – decreasing performance and increasing costs.
In addition, try to avoid using subqueries in your models or reporting. Common table expressions are a more strategic way to separate your code into smaller queries, meaning you can validate them as you go. In terms of performance, it’s just a more efficient way to optimize your query.
Here’s an example of a common table expression:
SELECT MAX(customer_signup) AS most_recent_signup FROM (SELECT customer_name, customer_phone, customer_signup FROM customer_details WHERE YEAR(customer_signup)=2023)
→
WITH
2023_signups AS (
SELECT
customer_name,
customer_phone,
customer_signup
FROM customer_details
WHERE YEAR(customer_signup)=2023
),
Most_recent_signup AS (
SELECT
MAX(customer_signup) AS most_recent_signup
FROM 2023_signups
)
SELECT most_recent_signup FROM Most_recent_signup4. Have Stored Procedures and Execution Plans
Stored procedures are routines that contain at least one or more SQL statements that execute a task or a set of tasks on a database server.
This can be useful for several reasons, including:
- Optimized performance
- Increased code reusability
- Enhanced security
- Improved code readability
In addition, an execution plan, or query plan, is a graphical (or XML or text) representation of different operations performance by the SQL query processor. There are three types of execution plans in the SQL server: estimated plan, actual plan, and cached plan.
Execution plans are generated when you execute any query, and they can be helpful in providing insights into the SQL server optimizer and query engine.
5. Database Design and Structure
One key way to design your database and structure is to focus on normalizing your tables. Put simply, normalizing is the process of organizing your data in a database, creating tables, and establishing relationships between the tables.
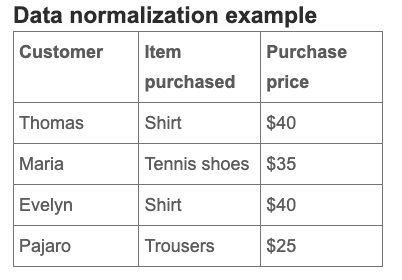
Normalizing the data would mean splitting the table above into two tables (one with customer information and the product they purchased and the other with each product and its price), and making additions or deletions to either table would not affect the other. Normalization helps to refine the data without adding duplicates.
On the other hand, data partitioning and sharing can also facilitate more manageable data maintenance. Partitioning means dividing data into smaller, manageable sections to provide quicker access and improved maintenance. Sharding extends this by distributing the sections across multiple servers or clusters, fostering scalability and fault tolerance.
Partitioning can help improve database performance by isolating data into smaller, manageable sections. So, when running queries, the database system can focus on specific partitions rather than scanning the entire dataset, leading to quicker data retrieval and processing.
When it comes to sharding, it’s important to be thoughtful. Data teams should design queries that minimize cross-shard communication or use caching to reduce latency, and leveraging optimized schemas, indexes, and execution plans to route queries effectively and maintain database performance.
6. Monitor SQL Query Optimization Performance
It’s essential to continue to monitor query performance over time and identify bottlenecks to reduce latency and unnecessary runtimes. CPU bottlenecks can be caused by inefficient code, high concurrency, memory leaks, or external factors such as network latency or disk I/O.
To identify bottlenecks faster, try SQL performance tuning tools like Performance Analyzer, Redgate SQL Monitor, dbForge, EverSQL, SolarWinds, and more.
In addition, it can be helpful to leverage query optimization hints, or instructions to the optimizer. Types of hints might be:
- Single-table: Single-table hints are specified on one table or view. INDEX and USE_NL are examples of single-table hints.
- Multi-table: Multi-table hints specify one or more tables or views. LEADING is an example of a multi-table hint. Note that USE_NL(table1 table2) is not considered a multi-table hint because it is a shortcut for USE_NL(table1) and USE_NL(table2).
- Query block: Query block hints operate on single query blocks. STAR_TRANSFORMATION and UNNEST are examples of query block hints.
Improve SQL Query Optimization with Data Observability
Altogether, SQL query optimization is essential for higher database performance. We’ve covered several best practices that can help optimize your SQL queries, including indexing, using the SELECT command to filter, choosing the right JOIN types, leveraging stored procedures and execution plans, designing and structuring your database effectively, and continuously monitoring query performance.
In addition, leveraging a tool like data observability is essential to monitoring the health of your data as you optimize your SQL queries. If jobs fail or anomalies occur anywhere throughout your pipeline, your data team needs to know fast, so they can identify the root cause, triage, and resolve it fast.
A data observability tool like Monte Carlo provides end-to-end data lineage, which can help to pinpoint the exact place where data discrepancies occur – reducing data downtime.
To learn more about how automated data observability can take your database performance to the next level, speak with our team.
Our promise: we will show you the product.
Read more posts.