Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Catalogs Are Dead; Long Live Data Discovery

Barr Moses
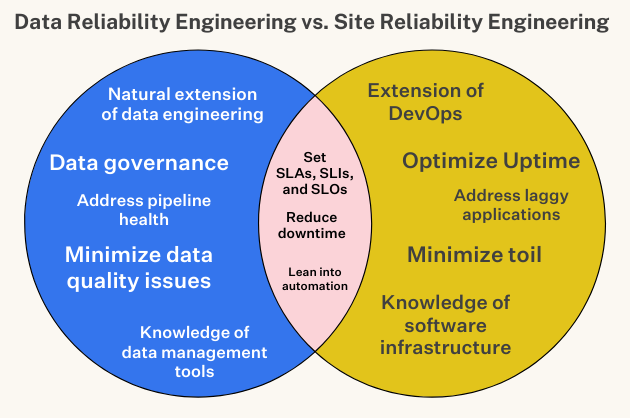
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Debashis Saha
Debashis Saha is a VP of Engineering at AppZen. Previously, he served as a VP of Data Platform Engineering at Intuit and eBay.
As companies increasingly leverage data to power digital products, drive decision making, and fuel innovation, understanding the health and reliability of these most critical assets is fundamental. For decades, organizations have relied on data catalogs to power data governance. But is that enough?
Debashis Saha, VP, Engineering at AppZen, formerly at eBay and Intuit, and Barr Moses, CEO and Co-founder of Monte Carlo, discuss why data catalogs aren’t meeting the needs of the modern data stack, and how a new approach – data discovery – is needed to better facilitate metadata management and data reliability.
Interested in learning more about Monte Carlo’s approach to data catalogs and metadata management? Request a demo.
It’s no secret: knowing where your data lives and who has access to it is fundamental to understanding its impact on your business. In fact, when it comes to building a successful data platform, it’s critical that your data is both organized and centralized, while also easily discoverable.
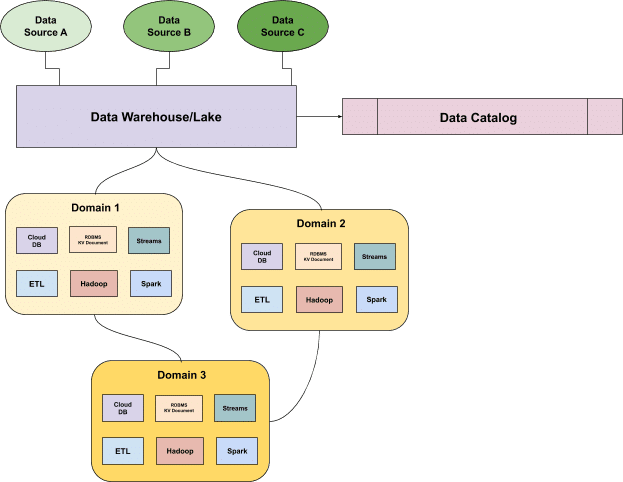
Analogous to a physical library catalog, a data catalog serves as an inventory of metadata and gives users the information necessary to evaluate data accessibility, health, and location. In our age of self-service business intelligence, data catalogs have also emerged as a powerful tool for data management and data governance.
Not surprisingly, for most data leaders, one of their first imperatives is to build a data catalog.
At the bare minimum, a data catalog should answer:
- Where should I look for my data?
- Does this data matter?
- What does this data represent?
- Is this data relevant and important?
- How can I use this data?
Still, as data operations mature and data pipelines become increasingly complex, traditional data catalogs often fall short of meeting these requirements.
Here’s why some of the best data engineering teams are innovating their approach to metadata management – and what they’re doing instead:
Where data catalogs fall short
While data catalogs have the ability to document data, the fundamental challenge of allowing users to “discover” and glean meaningful, real-time insights about the health of your data has largely remained unsolved.
Data catalogs as we know them are unable to keep pace with this new reality for three primary reasons: (1) lack of automation, (2) inability to scale with the growth and diversity of your data stack, and (3) their undistributed format.
Increased need for automation
Traditional data catalogs and governance methodologies typically rely on data teams to do the heavy lifting of manual data entry, holding them responsible for updating the catalog as data assets evolve. This approach is not only time-intensive, but requires significant manual toil that could otherwise be automated, freeing time up for data engineers and analysts to focus on projects that actually move the needle.
As a data professional, understanding the state of your data is a constant battle and speaks to the need for greater, more customized automation. Perhaps this scenario rings a bell:
Before stakeholder meetings, do you often find yourself frantically pinging Slack channels to figure out what data sets feed a specific report or model you are using – and why on earth the data stopped arriving last week? To cope with this, do you and your team huddle together in a room and start whiteboarding all of the various connections upstream and downstream for a specific key report?
I’ll spare you the gory details, but it probably looked something like this:

If this hits home, you’re not alone. Many companies that need to solve this dependency jigsaw puzzle embark on a multi-year process to manually map out all their data assets. Some are able to dedicate resources to build short-term hacks or even in-house tools that allow them to search and explore their data. Even if it gets you to the end goal, this poses a heavy burden on the data organization, costing your data engineering team time and money that could have been spent on other things, like product development or actually using the data.
Ability to scale as data changes
Data catalogs work well when data is structured, but in 2020, that’s not always the case. As machine-generated data increases and companies invest in ML initiatives, unstructured data is becoming more and more common, accounting for over 90 percent of all new data produced.
Typically stored in data lakes, unstructured data does not have a predefined model and must go through multiple transformations to be usable and useful. Unstructured data is very dynamic, with its shape, source, and meaning changing all the time as it goes through various phases of processing, including transformation, modeling, and aggregation. What we do with this unstructured data (i.e., transform, model, aggregate, and visualize it), makes it much more difficult to catalog in its “desired state.”
On top of this, rather than simply describing the data that consumers access and use, there’s a growing need to also understand the data based on its intention and purpose. How a producer of data might describe an asset would be very different from how a consumer of this data understands its function, and even between one consumer of data to another there might be a vast difference in terms of understanding the meaning ascribed to the data.
For instance, a data set pulled from Salesforce has a completely different meaning to a data engineer than it would to someone on the sales team. While the engineer would understand what “DW_7_V3” means, the sales team would be scratching their heads, trying to determine if said data set correlated to their “Revenue Forecasts 2021” dashboard in Salesforce. And the list goes on.
Static data descriptions are limited by nature. In 2021, we must accept and adapt to these new and evolving dynamics to truly understand the data.
Data is distributed; catalogs are not
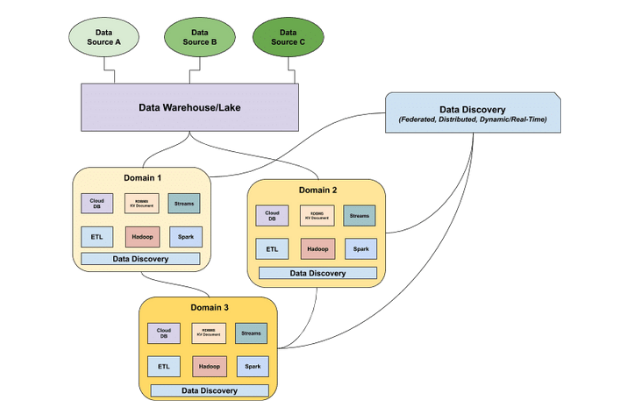
Despite the distribution of the modern data architecture (see: the data mesh) and the move towards embracing semi-structured and unstructured data as the norm, most data catalogs still treat data like a one-dimensional entity. As data is aggregated and transformed, it flows through different elements of the data stack, making it nearly impossible to document.
Nowadays, data tends to be self-describing, containing both the data and the metadata that describes the format and meaning of that data in a single package.
Since traditional data catalogs are not distributed, it’s near to impossible to use as a central source of truth about your data. This problem will only grow as data becomes more accessible to a wider variety of users, from BI analysts to operations teams, and the pipelines powering ML, operations, and analytics become increasingly complex.
A modern data catalog needs to federate the meaning of data across these domains. Data teams need to be able to understand how these data domains relate to each other and what aspects of the aggregate view are important. They need a centralized way to answer these distributed questions as a whole – in other words, a distributed, federated data catalog.
Investing in the right approach to building a data catalog from the outset will allow you to build a better data platform that helps your team democratize and easily explore data, allowing you to keep tabs on important data assets and harness their full potential.
Data Catalog 2.0 = Data Discovery
Data catalogs work well when you have rigid models, but as data pipelines grow increasingly complex and unstructured data becomes the golden standard, our understanding of this data (what it does, who uses it, how it’s used, etc.) does not reflect reality.
We believe that next generation catalogs will have the capabilities to learn, understand, and infer the data, enabling users to leverage its insights in a self-service manner. But how do we get there?
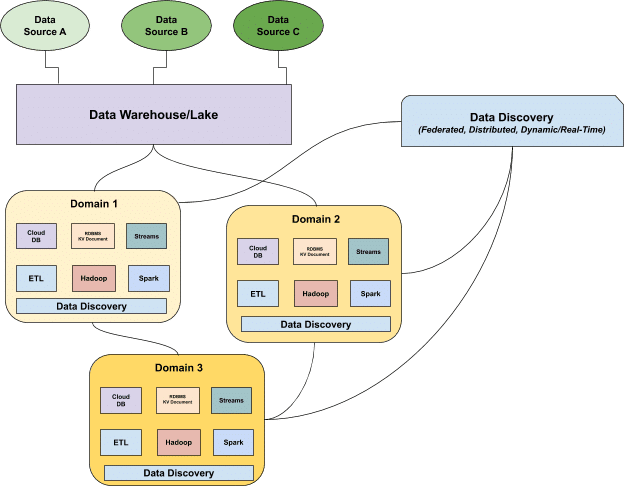
In addition to cataloging data, metadata and data management strategies must also incorporate data discovery, a new approach to understanding the health of your distributed data assets in real-time. Borrowing from the distributed domain-oriented architecture proposed by Zhamak Deghani and Thoughtworks’ data mesh model, data discovery posits that different data owners are held accountable for their data as products, as well as for facilitating communication between distributed data across different locations. Once data has been served to and transformed by a given domain, the domain data owners can leverage the data for their operational or analytic needs.
Data discovery replaces the need for a data catalog by providing a domain-specific, dynamic understanding of your data based on how it’s being ingested, stored, aggregated, and used by a set of specific consumers. As with a data catalog, governance standards and tooling are federated across these domains (allowing for greater accessibility and interoperability), but unlike a data catalog, data discovery surfaces a real-time understanding of the data’s current state as opposed to it’s ideal or “cataloged” state.
Data discovery can answer these questions not just for the data’s ideal state but for the current state of the data across each domain:
- What data set is most recent? Which data sets can be deprecated?
- When was the last time this table was updated?
- What is the meaning of a given field in my domain?
- Who has access to this data? When was the last time this data was used? By who?
- What are the upstream and downstream dependencies of this data?
- Is this production-quality data?
- What data matters for my domain’s business requirements?
- What are my assumptions about this data, and are they being met?
We believe that the next generation data catalog, in other words, data discovery, will have the following features:
Self-service discovery and automation
Data teams should be able to easily leverage their data catalog without a dedicated support team. Self-service, automation, and workflow orchestration for your data tooling removes silos between stages of the data pipeline, and in the process, making it easier to understand and access data. Greater accessibility naturally leads to increased data adoption, reducing the load for your data engineering team.
Scalability as data evolves
As companies ingest more and more data and unstructured data becomes the norm, the ability to scale to meet these demands will be critical for the success of your data initiatives. Data discovery leverages machine learning to gain a bird’s eye view of your data assets as they scale, ensuring that your understanding adapts as your data evolves. This way, data consumers are set up to make more intelligent and informed decisions instead of relying on outdated documentation (aka data about data that becomes stale, how meta!) or worse – gut-based decision making.
Data Lineage for distributed discovery
Data discovery relies heavily on automated table and field-level lineage to map upstream and downstream dependencies between data assets. Data lineage helps surface the right information at the right time (a core functionality of data discovery) and draw connections between data assets so you can better troubleshoot when data pipelines do break, which is becoming an increasingly common problem as the modern data stack evolves to accommodate more complex use cases.
Data reliability to ensure the gold standard of data — at all times
The truth is — in one way or another — your team is probably already investing in data discovery. Whether it’s through manual work your team is doing to verify data, custom validation rules your engineers are writing, or simply the cost of decisions made based on broken data or silent errors that went unnoticed. Modern data teams have started leveraging automated approaches to ensuring highly trustworthy data at every stage of the pipeline, from data quality monitoring to more robust, end-to-end data observability platforms that monitor and alert for issues in your data pipelines. Such solutions notify you when data breaks so you can identify the root cause quickly for fast resolution and prevent future downtime.
Data discovery empowers data teams to trust that their assumptions about data match reality, enabling dynamic discovery and a high degree of reliability across your data infrastructure, regardless of domain.
What’s next for data catalogs?
If bad data is worse than no data, a data catalog without data discovery is worse than not having a data catalog at all. To achieve truly discoverable data, it’s important that your data is not just “cataloged,” but also accurate, clean, and fully observable for ingestion to consumption – in other words: reliable.
A strong approach to data discovery relies on automated and scalable data management, which works with the newly distributed nature of data systems. Therefore, to truly enable data discovery in an organization, we need to rethink how we are approaching the data catalog.
Only by understanding your data, the state of your data, and how it’s being used – at all stages of its lifecycle, across domains – can we even begin to trust it.
Interested in seeing how data discovery and data observability can help your organization? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.