Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What in the World is Going on with Data Catalogs?


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Gordon Wong
Gordon Wong is a principal solutions architect and the former VP of Business Intelligence at HubSpot.
It seems like every time I refresh my Twitter feed, a new startup launches “the world’s greatest data catalog ever.” And that’s exciting!
If a company is able to build the next best catalog since sliced bread, the data world will surely breathe a collective sigh of relief. And don’t get me wrong: lots of innovation is happening here and clear advancements are being made. Integrations to support data engineers and software developers working directly in data governance reports and dashboards – check. Data science workbooks to foster greater collaboration – check. ML to support automatic data profiling – check.
But the reason why data catalogs are so top of mind right now isn’t because we’re happy with them. It’s because they’re having an identity crisis.
A data engineer or analyst walks into a bar…
Imagine you walk into your favorite bar. Let’s call it the Data Dive. There are posters of the local sports team, tiki torches (lit with electric flames, of course), and a sprawling dance floor.
You walk up to the bartender.
“What’ll it be?” She asks.
“Aperol spritz, please,” you say. It’s been awhile since you’ve had one (pre-pandemic, maybe?), but you remember it tasting great, particularly on hot days like today.
The bartender grabs a glass and puts it in front of you.
“Ingredients are behind the bar. Have at it.”
Sound familiar? Probably not, but in the context of data, maybe this approach to “self-service” will ring a bell.
Benn Stancil, co-founder and Chief Analytics Officer of Mode, wrote an article recently that waxed poetic about the challenges with self-service data tools.
According to Stancil, “The more questions people can theoretically self-serve, the fewer they can practically self-serve. As you add more options, self-serve tools stop looking like Mad Libs, and start looking like a blank document that requires people to write their own stories in their entirety. While that’s what analysts want, it’s not what everyone wants.”
While Stancil was talking about the “opinionated simplicity” of metric extraction vs. a one-size-fits-all approach to measuring data, we can apply this same lens to data catalogs. Too many options, too few opinions on what is actually required to make them successful.
As an example, he cites ELT providers as offering a limited, clear definition of what they can (and can’t) offer to data engineers: easy, fast data ingestion.
Now, in 2021, data catalogs are at a similar crossroads: try to be everything for everyone or do one to two things really, really well.
Choose your own adventure: data catalog edition
To paraphrase Jane Austen, “it is a truth universally acknowledged that a data engineer in good fortune, must be in need of a data catalog.”
In the past, I’ve written about how a data catalog falls short for three key reasons:
- Increased need for automation: Traditional data catalogs and data governance methodologies typically rely on data teams to do the heavy lifting of manual data entry, holding them responsible for updating the catalog as data assets evolve. This approach is not only time-intensive, but requires significant manual toil that could otherwise be automated, freeing time up for data engineers and analysts to focus on projects that actually move the needle.
- Ability to scale as data changes: Data catalogs work well when data is structured, but in 2021, that’s not always the case. As machine-generated data increases and companies invest in machine learning initiatives, unstructured data is becoming more and more common, accounting for over 90 percent of all new data produced.
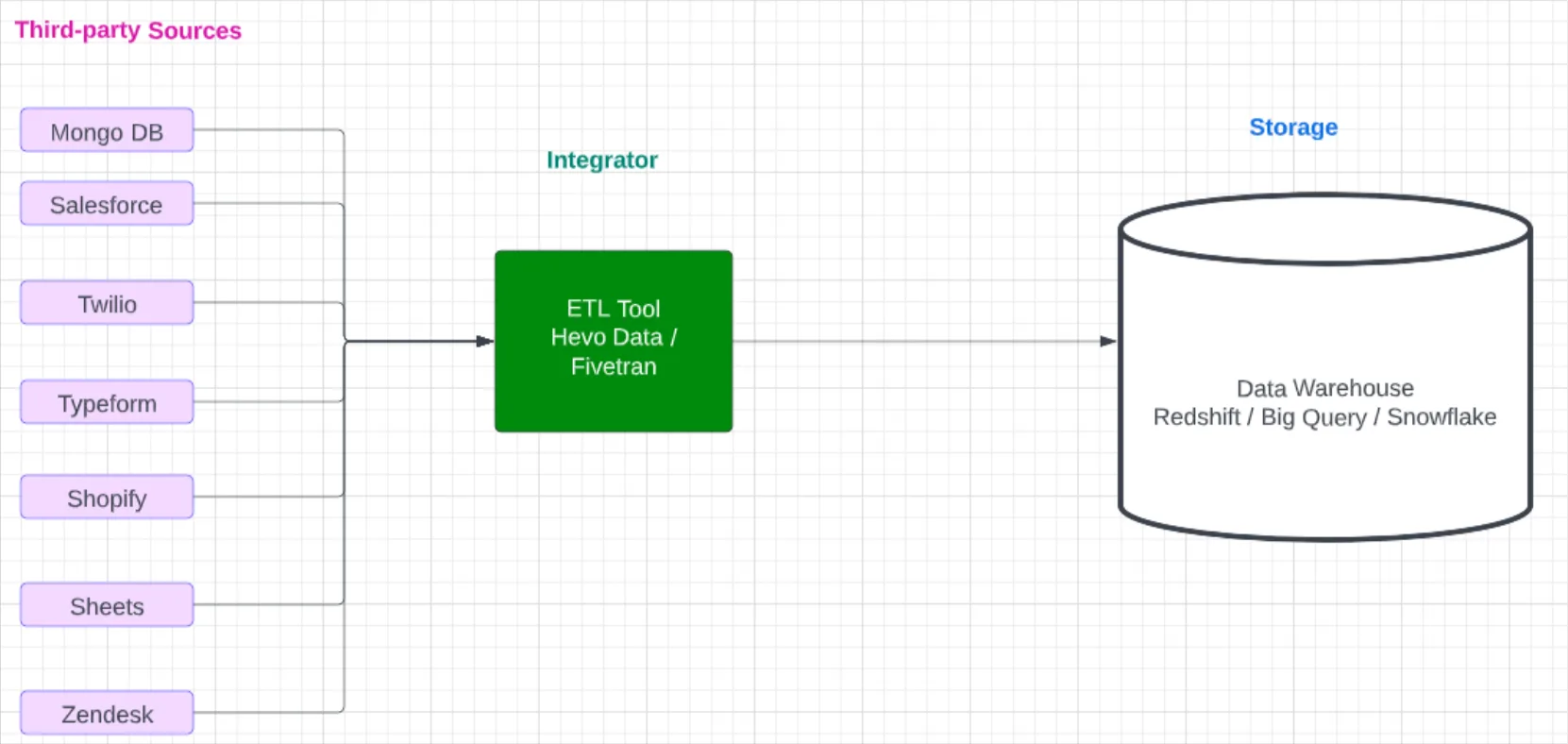
- Lack of a distributed architecture: Despite the distribution of the modern data architecture (see: the data mesh) and the move towards embracing semi-structured and unstructured data as the norm, most data catalogs still treat data like a one-dimensional entity. As data is aggregated and transformed, it flows through different elements of the data stack, making it nearly impossible to document.
And I shared why teams need to think more creatively about data catalogs by applying principles of data discovery. In a nutshell, data discovery refers to having a domain-specific, dynamic understanding of your data based on how it’s being ingested, stored, aggregated, and used by a set of specific consumers. Data discovery is core to our ability, as data practitioners, to make sense of what we’re working with and communicate this “sense” to our stakeholders.
So, what is the outcome of good data discovery? It varies depending on who you ask.
I encourage you to check all that apply:
- Data quality
- Data governance & compliance
- Collaboration
- Understanding
- Discussion
- Visualization
- Security
- Reliability
- Coverage
- Usability
- World peace
This list is overwhelming and confusing. This isn’t to say that a great data catalog can’t check multiple boxes. They can — and do. But if we don’t have a clear definition of our goals, how can we possibly track how we’re measuring up against them?
Here are some measurements we’ve seen used to track data catalog performance. Again, check all that apply:
- Data accuracy
- Data freshness
- Usage metrics
- Speed at which data is accessed
- Amount of data cataloged
But there’s something missing here: these metrics track “solution-based” outcomes, but will these actually tell you whether the data is useful? What about data reliability? Or if it’s trustworthy? This juncture is where data catalogs often get lost.
Modern data catalogs are all-too-frequently without a clear identity: in other words, a user story.
Can data catalogs find their way?
In a past life, one of our former colleagues spent two years building a data dictionary no one used. Why? When his team was done, the requirements were stale and the solution was no longer relevant.
Unfortunately, his experience is often the norm, not the exception. While product vision paves the way for any good solution, more powerful technologies developed and outcomes are had when we build to solve actual customer problems. And now, with data needs moving at the speed of light no matter where you look, this customer-first approach is more important than ever.
Data catalogs are incredibly important as they are a literal index of how we measure the world. But we don’t think they’ll actually be useful until they are designed with a purpose in mind.
But maybe that’s just us… regardless, we’re eager to see how the great data catalog identity crisis pans out.
Are you?
Do you know what in the world is going on with data catalogs? We’re all ears. Reach out to Barr Moses or Gordon Wong. Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.