Product demo.
Product demo.  What is data observability?
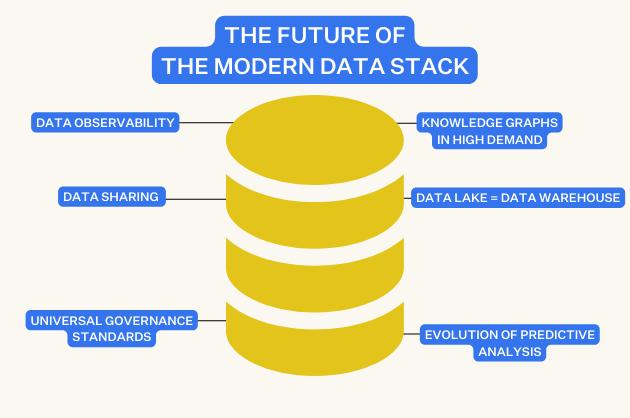
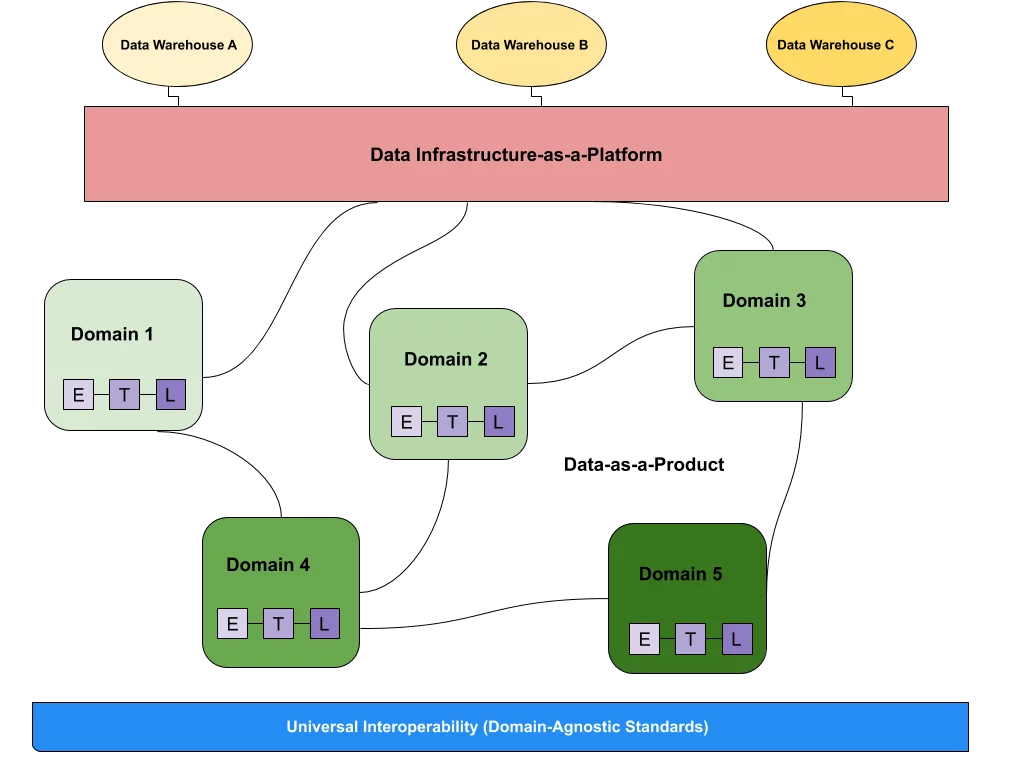
What is data observability?  What is a data mesh--and how not to mesh it up
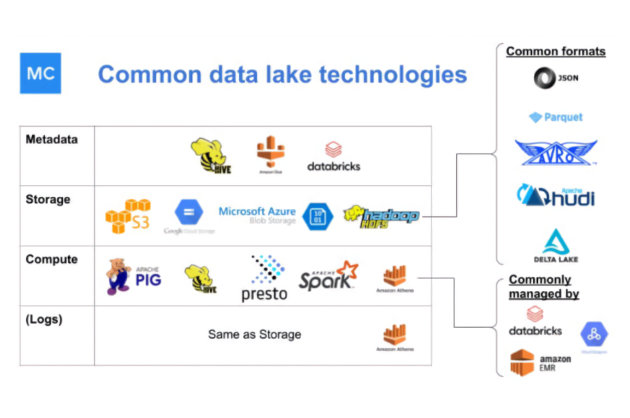
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Is The Self Service Data Platform A Lie? Data Engineers Debate


Francisco Alberini
Francisco is a product manager at Monte Carlo.

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Data self-service, the ability for stakeholders in the organization to answer their own business questions with data, is a top initiative for nearly every data leader I’ve spoken to this year.
It’s so foundational to creating a data-driven organization, that most of the questions surrounding it focus on the “when” rather than the “why.”
That’s why we were surprised to hear it became such a passionate debate at our New York IMPACT event, which included some of the area’s top data leaders working on some of the most complex challenges facing our industry today.
When we asked a member of our panel what they were struggling with the most, a data engineering leader at a multi-billion dollar company with a modern stack said:
“I am drowning in ad-hoc questions from the business.”
They weren’t alone! Everyone in the room started scribbling notes–clearly the panel had struck a nerve.

So we posed the question, “is self-service a lie?” It immediately divided the room and evoked strong opinions.
Even on our three-person panel, we were deadlocked with one person agreeing, one disagreeing, and one rejecting the premise of the question entirely.
This is an important question with real ramifications as self-service is at the core of two of the hottest trends in data: the data mesh and the decentralization of the data team.
In this post, we will showcase both sides, and leave it to you, dear reader, to determine what makes the most sense for your organization.
Let’s start by hearing from the prosecution.
Self-Serve Is A Lie

The argument goes something like this.
The number of questions that people can come up with is truly infinite. The very nature of data, and really the scientific method in general if you want to get grandiose (we do), is the minute you present the answer to one question, it sparks another.
And for those who have spent any time working on a data team, you know the inevitable way the business operates is that an executive needs an answer to a very particular question now–and you are the path of least resistance.
Of course, the inevitable emergence of the data question fire drill is not entirely the fault of our data consuming colleagues. Let’s be honest with ourselves. Data engineers have a love / hate relationship with being a data wrangler.
For example, one customer told me, “10% of my job is answering questions about our data and I hate that part of my job” while another one said they really enjoyed being the go-to source for data decisions.

It’s a matter of perspective and degrees. No one really enjoys being interrupted and being asked a million questions or treated like a data catalog.
On the other hand, deep down, do we sometimes love being the smartest person in the room? Do we take some professional pride in being the go-to star who can swoop in to put out fires and save the day? Does that stunt some of the natural inclinations from data consumers toward self-service?
Well, it’s complicated.
But, perhaps the most compelling argument regarding self-service as one of data’s biggest lies is the potential for it blowing up in your face.
Everyone who has worked in data has had that moment where they thought they gave a consumer enough context to empower them to complete their project, only to then have that person do something completely unexpected and egregious with the data (with the best of intentions, of course).
So instead of spending 20 minutes directly holding their hand, you pointed them in the self-serve direction and now you’re working late re-doing their work.
For example, my colleague worked at a company with a CEO that was very involved with the data, which was a tremendous benefit. As they grew from a 50 to a 500 person company, the CEO by necessity was pulled in many different directions and couldn’t be as close to the data as they used to be.
When the CEO (admirably!) went to do a bunch of analysis directly and pull data for board slides, they hadn’t realized the data they once knew well had changed. The slides ended up pretty far from reality and had to be redone just hours before the board meeting.
This type of story is common and can happen with even the most benign and standardized data. For example, NPS survey data could have a batch of data that accidentally double surveyed the same people or had the wrong time window due to one large historical load into a table creating wrong timestamps. Or they could simply be using an older, deprecated table.
Self-Serve Is The Truth

Now it’s time to hear from the defense. The argument goes something like…
If perfect is the bar you need to clear, then you will never start any data initiative.
And just like your marketing attribution formula will never be perfect, neither will your self-service mechanisms. And despite this realization, you still need to make the effort, otherwise you’ll have larger problems on your hands.
If you don’t at least try to implement a self-service motion, you will need to start initiatives from scratch every time you lose a data engineer with that particular bit of tribal knowledge. That can’t scale.
Besides, it’s not just the destination that has value, but the journey itself. Along the self-service path are the pitstops of data documentation, literacy, discovery, and quality. All incredibly important to an organization in their own right.
We’ve also seen that centralized data teams are far from perfect. Often it’s the domain analysts who are closest to the data who can be the most effective and wring the most value from it.
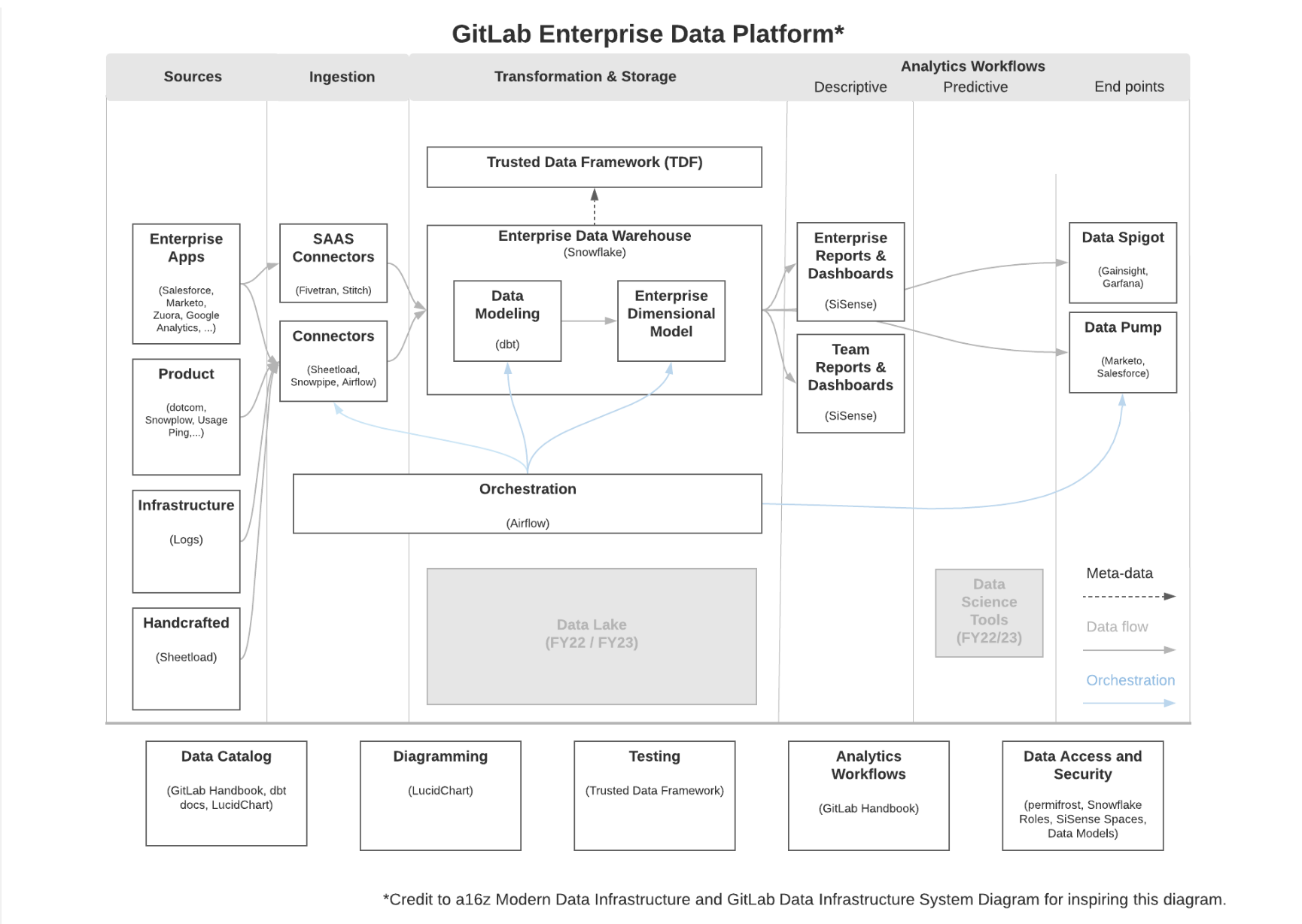
Finally, if there was ever a time to invest in self-service it would be today with all the tools available across the modern data stack.
The cloud data warehouses and lakes make data access easier than ever while tools, like data observability platforms, that automatically collect and surface up-to-date lineage and metadata provide more context than ever before. Tools such as dbt and ThoughtSpot truly democratize data so the less technically skilled stakeholders can model and query data without the use of code respectively.
Not only is self-service possible, but it’s an absolutely necessary exercise for the organization to agree to common standards, definitions, and metrics so they can actually become data driven.
Verdict: Iterate and let the business help you help them

With self-service, as with many things in data, it’s about the definitions you create and where you draw the line.
In fact, it’s rarely the case that self-service needs to be defined as every person in the company being able to answer every question they can think up without having to involve anyone in data engineering. If that’s the case, where do you draw the line between those that need a higher-level of self-service or direct data access from those that don’t?
The consensus that emerged on the panel was data analysts are going to form the bedrock of your self-service and data democratization efforts. It’s important they are or become fluent in writing SQL. They need to be both equipped and empowered to answer the questions they field as they sit closest to the business.
Unfortunately, there is often a wide gap between the engineering and analyst teams. Ironically, self-service initiatives can actually exacerbate that distance and so careful forethought needs to be given to the process of ensuring data producers and engineers are still communicating and staying close to their customers.
One popular strategy for bridging this chasm is to leverage analytics engineers to serve as the layer between your messy, behind-the-scenes production database and the data consumer facing data warehouse or instance where the cleanest, most documented data lives for wider exploration.
Another solution is to train data consumers to leverage what is typically an unused goldmine of information about a company’s data: Slack. A quick Slack search for a table name before asking a question can save tons of time.
We also recommend your self-service platform and customer base start small. On the platform side that could mean certifying tables for self-service or leveraging a data product framework.
On the customer base side, just like self-service doesn’t require everyone at the company writing SQL queries, it also doesn’t mean everyone across the data team needs the same level of service.
As former UCLA basketball coach John Wooden said, “Fairness is giving all people the treatment they earn and deserve. It doesn’t mean treating everyone alike.” In other words, there are going to be some domains that are more mature and require more self-service capabilities than others. Start with one team, make them deliriously happy, and scale from there.
Finally, another self-service approach worth considering is to flip the traditional paradigm on its head and start with your data consumers first. Work with them to understand their needs, write a data contract, create data SLAs and deliver the data pre-modeled.
Ultimately, if we MUST preside as the judge in this courtroom, we’ll declare that self-service is a worthwhile endeavor and an obtainable goal for most data teams.
But, we’ll also concede it’s a good idea to understand that reality will dictate those last minute ad-hoc requests will never be eliminated and it’s better to have a process to accommodate them than force everything into a self-serve world.
What do you think?
Interested in how Monte Carlo can help you scale self-service initiatives with better data quality? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.