Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Why You Need to Set SLAs for Your Data Pipelines


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
For today’s data engineering teams, the demand for real-time, accurate data has never been higher, yet data downtime is an all-too-common reality. So, how can we break this vicious cycle and achieve reliable data?
Just like our software engineering counterparts 20 years ago, data teams in the early 2020s are facing a significant challenge: reliability.
Companies are ingesting more and more operational and third-party data than ever before. Employees from across the business are interacting with data at all stages of its lifecycle, including those on non-data teams. And at the same time, data sources, pipelines, and workflows are growing increasingly complex.
While software engineers have addressed application downtime with specialized fields (like DevOps and Site Reliability Engineering), frameworks (like Service Level Agreements, Indicators, and Objectives), and plenty of acronyms (SRE, SLAs, SLIs, and SLOs, respectively), data teams have not treated data downtime with the diligence it deserves.
The time has come for data teams to do the same: prioritize, standardize, and measure data reliability. I envision that over the next decade, data quality or reliability engineering will grow into its own specialization, responsible for this critical business function.
Until then, let’s explore what data reliability SLAs are, why they matter, and how to create them.
What is an SLA?

Simply put, service-level agreements (SLAs) are a method many companies use to define and measure the level of service a given vendor, product, or internal team will deliver—as well as potential remedies if they fail to deliver.
For example, Slack’s customer-facing SLA promises 99.99% uptime every fiscal quarter, and no more than 10 hours of scheduled downtime, for customers on Plus plans and above. If they fall short, affected customers will receive service credits on their accounts for future use.
Customers use SLAs to ensure they’re getting what they paid for from a vendor: a robust, reliable product. And for many software teams, SLAs are developed for internal projects or users, not just end customers.
Why do SLAs matter?
Let’s use internal software engineering SLAs as an example. Why go through the process of codifying SLAs at all, if you don’t have a customer pressuring you to commit to certain thresholds in a contract? Why not just count on everyone to do their best and shoot for as close to 100% uptime as possible? Isn’t this just introducing unnecessary red tape?
Not at all. The very practice of defining, agreeing upon, and measuring key attributes of what constitutes reliable software can be both incredibly useful and set clear expectations for internal stakeholders.
SLAs can help engineering, product, and business teams align on what actually matters most about their applications and prioritize incoming requests. With SLAs, different software engineering teams and their stakeholders can be confident they’re speaking the same language, caring about the same metrics, and sharing a commitment to clearly documented expectations.
Setting those non-100%-uptime expectations also leaves space for growth. If zero risk of downtime will be tolerated, there is zero room for innovation. Plus, it’s just not feasible. Even with all the best practices in the world in place, systems will break occasionally. But with good SLAs, when something does go wrong, engineers will know exactly when and how to intervene.
Why data reliability SLAs matter

Similarly, it’s become a critical need for data teams and their data consumers to define, measure, and track the reliability of their data across its lifecycle.
Setting data reliability SLAs helps build trust and strengthen relationships between your data, your data team, and downstream consumers, whether that’s your customers or cross-functional teams at your company. Without these clearly defined metrics, consumers may make flawed assumptions or rely on anecdotal evidence about the reliability and trustworthiness of your data platform. In other words, data SLAs helps your organization be more “data-driven” about data.
SLAs also formalize and streamline communication, ensuring your team and your stakeholders are speaking the same language and referencing the same metrics. And since the process of defining SLAs helps your data team better understand the priorities of the business, they’ll be able to prioritize swiftly and speed up response times when incidents do occur.
How to create data reliability SLAs
Creating data reliability SLAs and sticking to them is an exercise in collaboration and specificity.
Let’s get some vocabulary straight first. Per Google’s service level agreements (SLAs) require clearly defined service level indicators (SLIs), quantitative measures of service quality, and agreed-upon service level objectives (SLOs), the target values or ranges of values that each indicator should meet. For example, many engineering teams measure availability as an indicator of site reliability, and set an objective to maintain availability at least 99%.
Usually, for data teams, the process of creating reliability SLAs follows three key steps: defining, measuring, and tracking.
Step 1: Defining data reliability with SLAs
The first step is to agree upon and clearly define what reliable data means to your organization.
I recommend beginning by setting a baseline. Start by conducting an inventory of your data, how it’s being used, and by whom. Assess the historical performance of your data to gain a baseline metric for reliability.
You’ll also want to get feedback from your data consumers on what “reliability” looks like to them. Even with a good understanding of data lineage, data engineers can often be removed from their colleagues’ day-to-day workflows and use cases. When creating reliability agreements with internal teams, it’s vital to understand how consumers actually interact with data, what data matters most, and which potential issues require the most stringent, immediate attention.
Additionally, you’ll want to make sure relevant stakeholders—all data leaders or business consumers with vested interests in reliability—have weighed in, and bought in, on the definitions of reliability you’re developing.
Once you understand (1) what data you’re working with, (2) how it’s used, and (3) who uses it, you’ll be able to set clear, actionable SLAs.
(If you’re still shaky on what these SLAs might look like, I highly recommend reading this Locally Optimistic series on setting data warehouse SLAs. Brooklyn Data Co.’s Scott Breitenother offers a very robust template for getting started, as well as practical advice for communicating SLAs with stakeholders).
Step 2: Measuring data reliability with SLIs
Once you have a thorough understanding and baseline in place, you can start to home in on the key metrics that will become your service-level indicators of reliability.
As a rule of thumb, data SLIs should represent the mutually agreed-to state of data you defined in step 1, provide boundaries of how data is used and not used, and specifically describe what data downtime looks like. This could include scenarios like missing, duplicative, or outdated data.
Your SLIs will depend on your specific use case, but here are a few metrics used to quantify data health:
- The number of data incidents for a particular data asset (N). Although this may be beyond your control, given that you likely rely on external data sources, it’s still an important driver of data downtime and usually worth measuring.
- Time-to-detection (TTD): When an issue arises, this metric quantifies how quickly your team is alerted. If you don’t have proper detection and alerting methods in place, this could be measured in weeks or even months. “Silent errors” made by bad data can result in costly decisions, with repercussions for both your company and your customers.
- Time-to-resolution (TTR): When your team is alerted to an issue, this measures how quickly you were able to resolve it.
Step 3: Tracking data reliability with SLOs
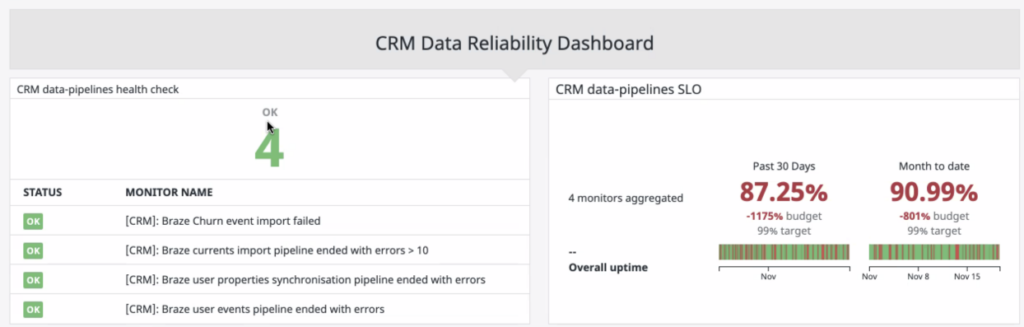
After you’ve identified the key indicators (SLIs) for data reliability, you can set objectives—that is, acceptable ranges of data downtime.
These SLOs should be realistic and based on your real-world circumstances. For example, if you decide to include TTD as a metric, but you don’t use any automated monitoring tools, your SLO should be a lower range than a mature organization with comprehensive data observability tooling.
Agreeing upon these ranges enables you to create a uniform framework that rates incidents by level of severity, and makes it simple to communicate and respond swiftly when issues arise.
Once you have these objectives set and incorporated into your SLAs, you can create a dashboard to track and report on progress. Some data teams create their own ad-hoc dashboards, while others use dedicated data observability tools.
Data reliability in practice
Setting SLAs, SLOs, and SLIs for data is only the first piece of the puzzle. When data incidents occur, we also need a way to triage and manage incidents before they become a massive headache for downstream consumers.
For this, we can again turn to our friends in DevOps for inspiration. Most engineering organizations allocate entire Site Reliability teams to identifying, resolving, and preventing downtime. In today’s modern data organization, data engineers often bear the brunt of the pain when pipelines break and dashboards turn wonky.
To make the incident resolution process easier and more seamless, we can take a page out of the SRE’s handbook to effectively communicate and triage data issues as they arise.
For example, let’s say one of your executive’s critical reports is surfacing stale data. From the outset, you’re not sure how this pipeline broke, but you need to communicate that it HAS broken and that your team is on the case. And as you’re resolving this issue, you need to consistently update not just your fellow data downtime sleuths but also your key stakeholders on the incident resolution process.
Here are some helpful emojis and their corresponding meanings for easy communication gleaned from some of the best data engineering teams:
And some icons to indicate the severity of incidents:

While what it takes to achieve reliable data is ultimately up to the needs of your business, having a great communications strategy in place will make it that much easier to execute on your SLAs.
Getting started
We’re excited to see how this specialized field of data reliability engineering develops. SLAs, SLIs, and SLOs are a good place to start: they provide a useful framework for measuring data downtime, and can help build a trusting, collaborative, data-driven culture across your entire organization.
Just like SREs ensure application uptime through automated support systems, data teams deserve their own specialized tooling. The best data platform won’t just measure data downtime, but will ultimately help prevent it in the first place through end-to-end data observability— making the highest standards of data reliability attainable for your team.
Interested in learning more about setting SLAs and achieving reliable data pipelines? Reach out to Barr and the rest of the Monte Carlo team!
Read more posts.