Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Reverse ETL and Data Observability: Solving Data’s “Last Mile” Problem


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Tejas Manohar
Tejas is the co-founder of Hightouch, a Reverse ETL solution, and former Tech Lead at Segment.
Modern data teams have all the right solutions in place to ensure that data is ingested, stored, transformed, and loaded into their data warehouse, but what happens at “the last mile?” In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use?
Here’s where Reverse ETL and Data Observability can help teams go the extra mile when it comes to trusting your data products.
It’s 9 a.m. – you’ve had your second cup of coffee, your favorite Spotify playlist is blaring in the background, and you’ve just refreshed your team’s “Marketing Analytics” dashboard for the third time this morning, just to be sure that the data checks out before your CMO’s weekly All Hands. Everything is (seemingly) right in the world.
Then, just as you are settling into your groove, you get the Slack ping heard around the world: “Why isn’t Salesforce updated with the latest numbers?”
If this situation sounds familiar, you’re not alone. In 2021, companies are betting big on data to drive decision making and power their digital products, yet up to 68 percent of that data frequently goes unused due to issues that happen after it is transformed in the warehouse.
All too often, there’s a disconnect between the numbers in your Looker or Tableau dashboards and what’s represented in your operational systems (i.e., your CMO’s Salesforce report), slowing down your stakeholders and eroding trust in data. We call this data’s “last mile problem” and it’s an all-too-common reality for modern businesses.
Fortunately, there’s a better way: Reverse ETL. In partnership with Data Observability, this new suite of data tools can help data teams unlock the potential of accessible, reliable data when it matters most.
What is Reverse ETL?
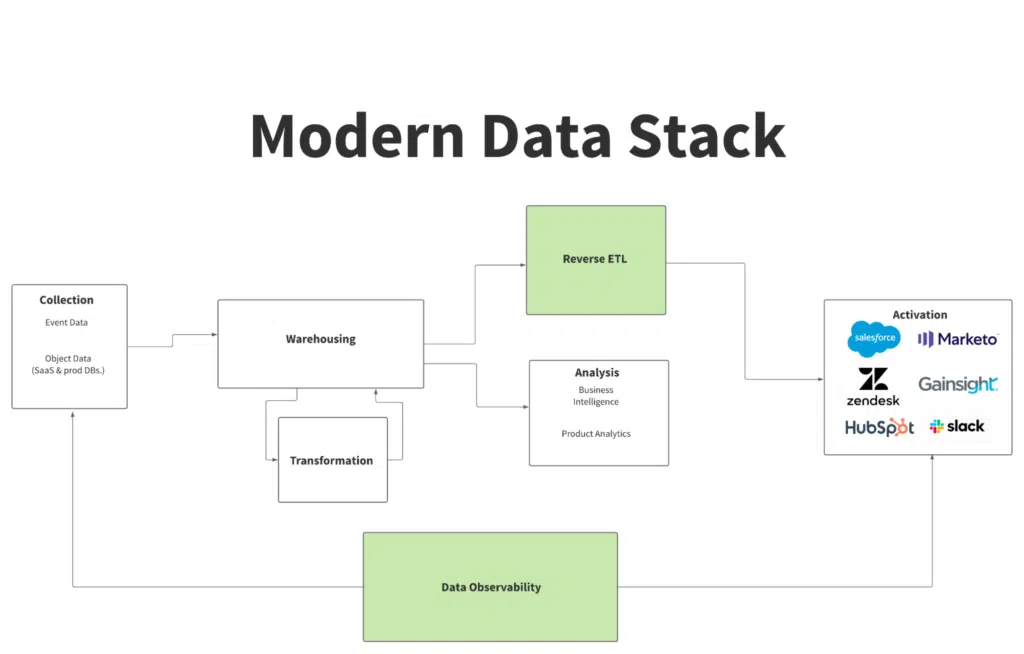
If traditional ETL and ELT solutions like Fivetran and Stitch enable companies to ingest data into their modern data warehouse for transformation and modeling, Reverse ETL does just the opposite: it enables companies to move transformed data from their cloud data warehouse out into operational business tools. It’s a new approach to making data actionable and solving the “last mile” problem in analytics by empowering business teams to access—and act on—transformed data directly in the SaaS tools they already use every day.
Reverse ETL pipelines can be custom-built, but like many data engineering challenges, they require significant resources to design, build, and maintain. Reverse ETL tools make it possible for teams with less data engineering resources to design and build pipelines using only SQL—no third-party APIs or custom scripts required.
Simultaneously, Reverse ETL reinforces the role of the data warehouse as a source of truth while still democratizing access to data by bringing it out of dashboards and reports and into the tools that sales, marketing, and customer success teams are already using.
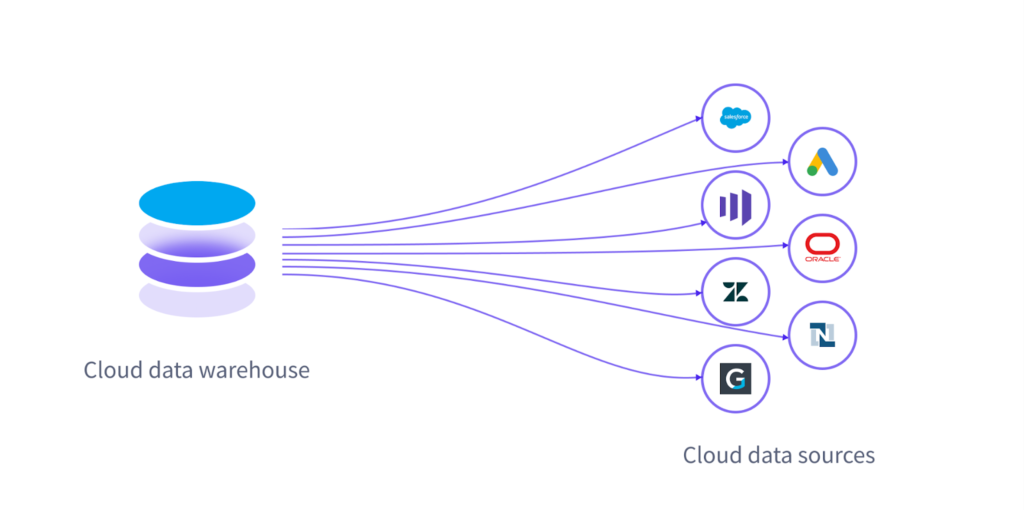
Reverse ETL powers operational analytics
By democratizing access to data and making data more accessible, Reverse ETL is powering a new paradigm known as operational analytics—the practice of feeding insights from data teams to business teams in their usual workflow so they can make more data-informed decisions. Reverse ETL “operationalizes” the same data that powers reports in a BI tool by ensuring it’s accessible and actionable in downstream SaaS tools.
Operations and analytics teams are increasingly leveraging this new approach to pipe transformed data from their cloud data warehouses into their CRMs (like Salesforce), marketing automation tools, advertising platforms, customer support and ticketing systems, and, of course, Slack. This makes the vast amounts of customer data being collected and stored in warehouses more accessible to analysts and business intelligence teams, while ensuring that data engineers cover their bases when it comes to delivering accessible, actionable data to their stakeholders.
Of course, as more and more data is being generated (and made actionable), this leads to one crucial question: can companies trust their data?
The risk of data downtime
Whenever companies increase their collection and use of data, the risk of data downtime—occasions when data is missing, inaccurate, or otherwise erroneous—increases as well. And broken pipelines, delayed ingestors, and downstream impacts all become more urgent when direct customer experiences are on the line. Consider the possible scenarios:
- If out-of-date data is powering customer support communications, teams risk sending irrelevant messages at sensitive moments in the customer lifecycle.
- If data powering your sales sequences (such as the completion of a free trial) is missing or delayed, then timely messages won’t be sent and opportunities may be missed
- If the pipeline sending customer data to your advertising platform breaks, ad spend can quickly veer off-track—leading to missed revenue or higher customer acquisition costs
Beyond the concrete business impact of poor data quality, internal teams may lose trust in data if downtime occurs regularly. For companies working to build a data-driven culture, this trust is a precious—but precarious—commodity.
This is exactly why companies investing in Reverse ETL shouldn’t skip the final layer in the modern data stack: Data Observability.
What is Data Observability?
Data Observability applies the principles of DevOps and application observability to data, using monitoring and alerting to detect data quality issues for the following pillars:

- Freshness: Is the data recent? When was the last time it was generated? What upstream data is included/omitted?
- Distribution: Is the data within accepted ranges? Is it properly formatted and complete?
- Volume: Has all the expected data arrived?
- Schema: What is the schema, and how has it changed? Who has made these changes and for what reasons?
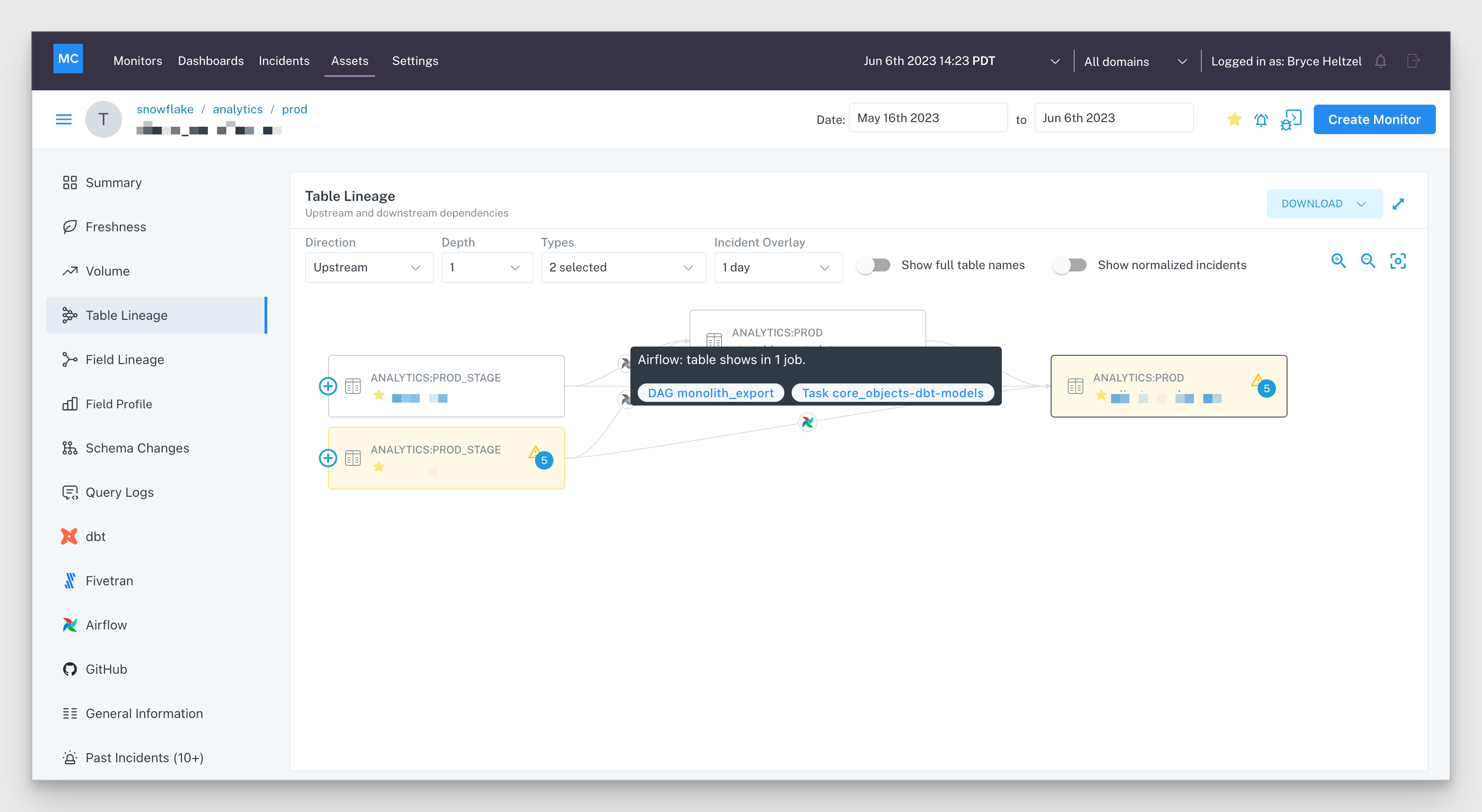
- Lineage: What are the upstream sources and downstream assets impacted by a given asset? Who are the people generating this data, and who is relying on it for decision-making?
Simply put, data observability helps data teams ensure that their pipelines and assets are accurate and trustworthy. Monitoring and alerting through data observability platforms help ensure that when incidents do occur, the responsible data team will be the first to know—and can intervene with business teams to prevent downstream impacts of unreliable data.
How Reverse ETL and Data Observability work together to deliver trustworthy data—and preserve data engineering resources
For overworked data engineering teams, Reverse ETL and Data Observability save valuable time and resources by democratizing data access—while ensuring reliability and providing visibility into how and when data is put to use.
Reverse ETL products provide developers with change logs and a live debugger to enhance visibility into operational data flows. Alongside Data Observability’s automated lineage and end-to-end monitoring of data assets and pipelines throughout the entire data lifecycle, both tools provide increased visibility and understanding of how data is accessed and interacted with throughout the organization.
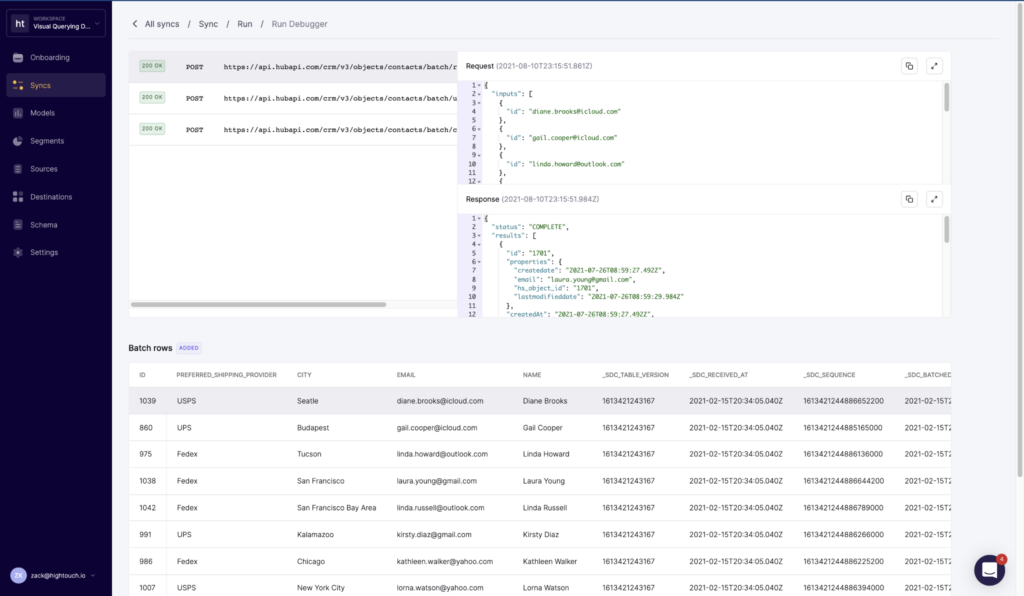
Your data tools shouldn’t be a black box, which is why leading Reverse ETL tools provide a live debugger for understanding the changes and API calls they make on your behalf. With Reverse ETL, business teams can access data directly in their preferred tools, acting on customer insights and events swiftly and designing workflows that automate data-driven processes. Reverse ETL tools act as the glue between data and business teams: data teams own the data models, and then business teams can use UIs like a point-and-click Audience Builder to define the data they need in their tools without needing to know SQL. This frees up data engineers from one-off tasks while enabling business teams to self-serve their data.
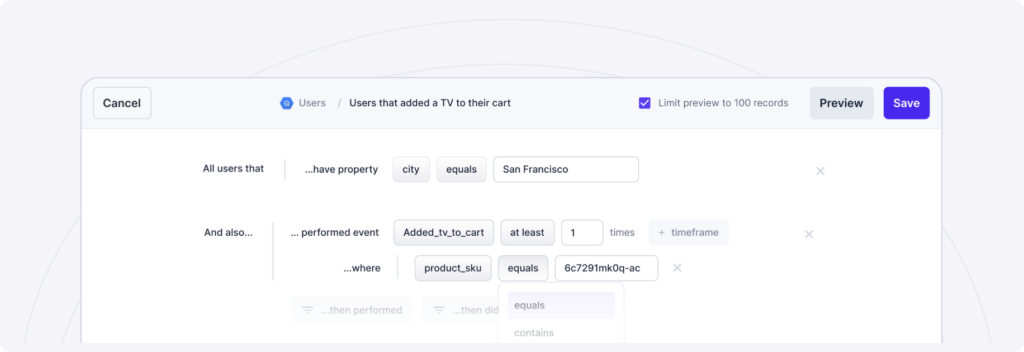
And with Data Observability, those same teams can trust that the data powering their customer experiences is reliable, accurate, and up-to-date. With automatic, end-to-end coverage of your entire stack, Data Observability supplements traditional testing by monitoring and alerting for issues with your data at each stage of the pipeline across five key pillars of data health: freshness, distribution, volume, schema, and lineage.
Modern Data Observability tools can even help you root cause data issues in real-time, before they affect business users in both BI dashboards and SaaS solutions further downstream by centralizing all contextual, historical, and statistical information about critical data assets in one unified platform.
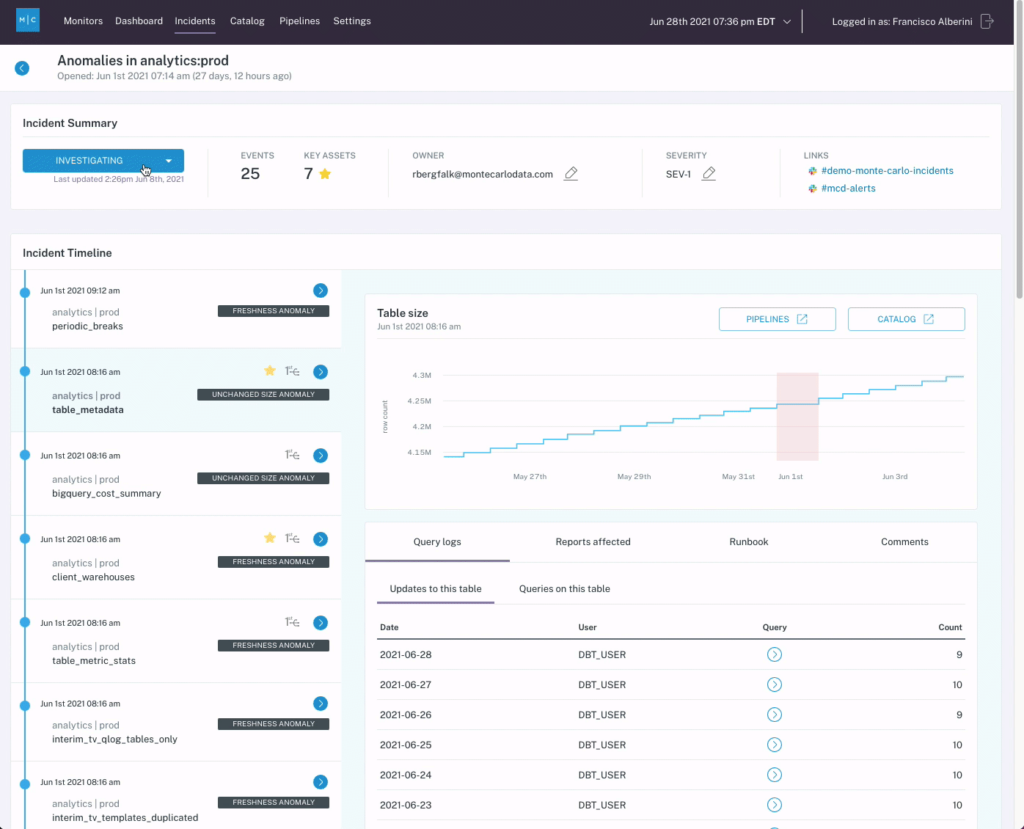
For instance, one common cause of data downtime is freshness – i.e. when data is unusually out-of-date. Such an incident can be a result of any number of causes, including a job stuck in a queue, a time out, a partner that did not deliver their dataset timely, an error, or an accidental scheduling change that removed jobs from your DAG.
By taking a historical snapshot of your data assets, data observability gives you the approach necessary to identify the “why?” behind broken data pipelines, even if the issue itself isn’t related to the data itself. Moreover, the lineage afforded by many data observability solutions gives cross-functional teams (i.e., data engineers, data analysts, analytics engineers, data scientists, etc.) the ability to collaborate to resolve data issues before they become a bigger problem for the business.
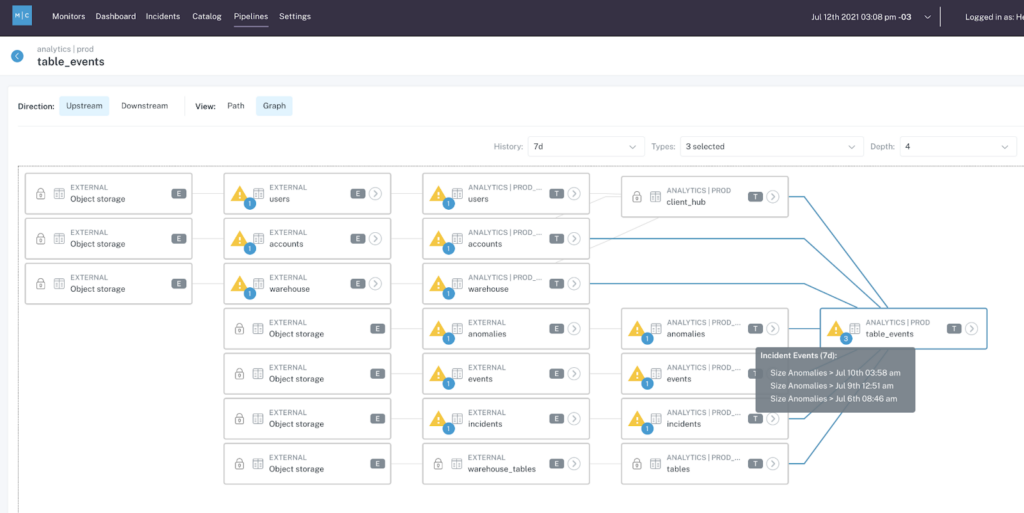
While neither Reverse ETL nor Data Observability can save you from all the early morning pings your stakeholders sling at you, taking a proactive, end-to-end approach to data access and trust can certainly help you navigate the “last mile” of the data journey — with or without the perfect playlist.
Curious how Reverse ETL and Data Observability can unlock the potential of your company’s data? Try out Hightouch directly for free, or schedule a demo with Monte Carlo today!
Our promise: we will show you the product.
Read more posts.