Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Observability: Reliability In The AI Era

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
When we introduced the concept of data observability four years ago, it resonated with organizations that had unlocked new value…and new problems thanks to the modern data stack.
Now, four years later, we are seeing organizations grapple with the tremendous potential…and tremendous challenges posed by generative AI.
The answer today is the same as it was then: improve data product reliability by getting full context and visibility into your data systems. However, the systems and processes are evolving in this new AI era and so data observability must evolve with them, too.
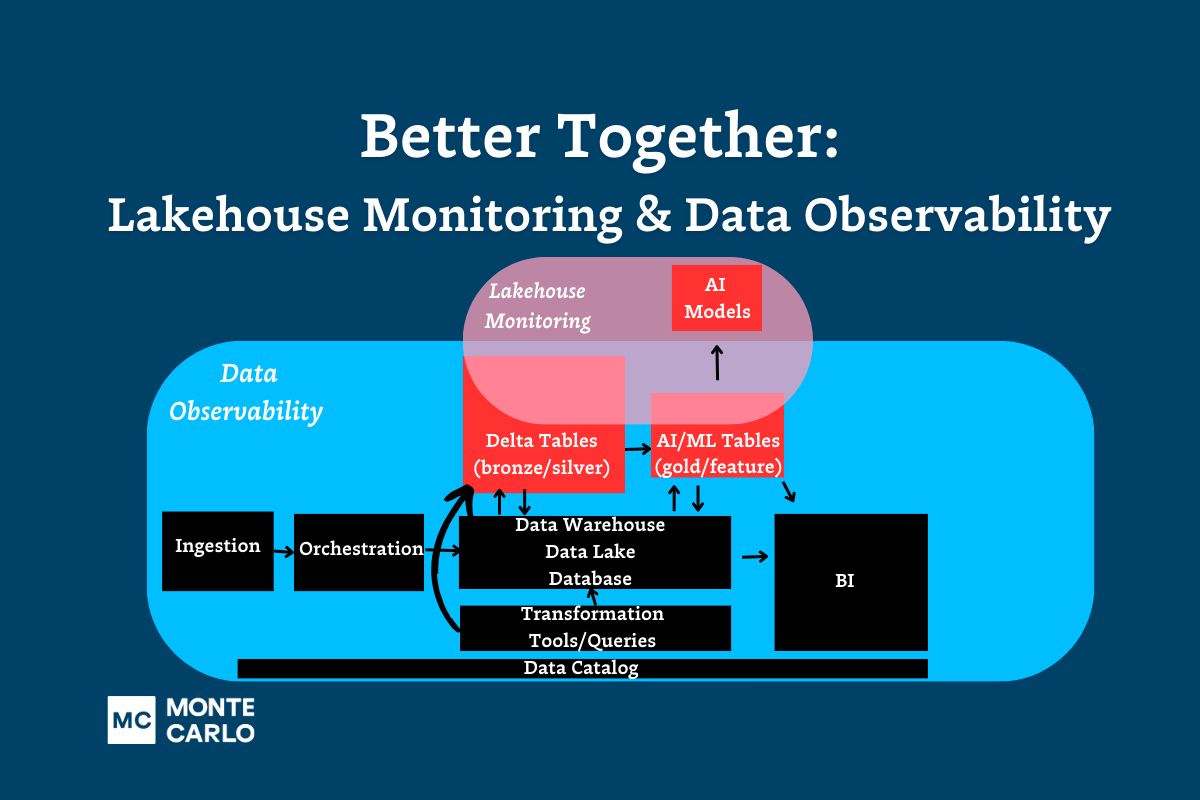
Perhaps the best way to think about it is to consider AI another data product and data observability as the living, breathing system that monitors ALL of your data products. The need for reliability and visibility into what is a very black box is just as critical for building trust in LLMs as it was in building trust for analytics and ML.
For GenAI in particular, this means data observability must prioritize resolution, pipeline efficiency, and streaming/vector infrastructures. Let’s take a closer look at what that means.
Table of Contents
Going beyond anomalies
Software engineers have long since gotten a handle on application downtime, thanks in part to observability solutions like New Relic and Datadog (who by the way just reported a stunning quarter).
Data teams, on the other hand, recently reported that data downtime nearly doubled year over year and that each hour was getting more expensive.

For modern software applications, reliability preceded adoption and value generation. No one would use a mobile banking or navigation app that crashed every 4 hours.
Data products–analytical, ML and AI applications–need to become just as reliable as those applications to truly become enmeshed within critical business operations. How?
Well, when you dig deeper into the data downtime survey, a trend starts to emerge: the average time-to-resolution (once detected) for an incident rose from 9 to 15 hours.
In our experience, most data teams (perhaps influenced by the common practice of data testing) start the conversation around detection. While early detection is critically important, teams vastly underestimate the significance of making incident triage and resolution efficient. Just imagine jumping around between dozens of tools trying to hopelessly figure out how an anomaly came to be or whether it even matters. That typically ends up with fatigued teams that ignore alerts and suffer from data downtime. We spent a lot of time at Monte Carlo making sure this doesn’t happen to our customers.
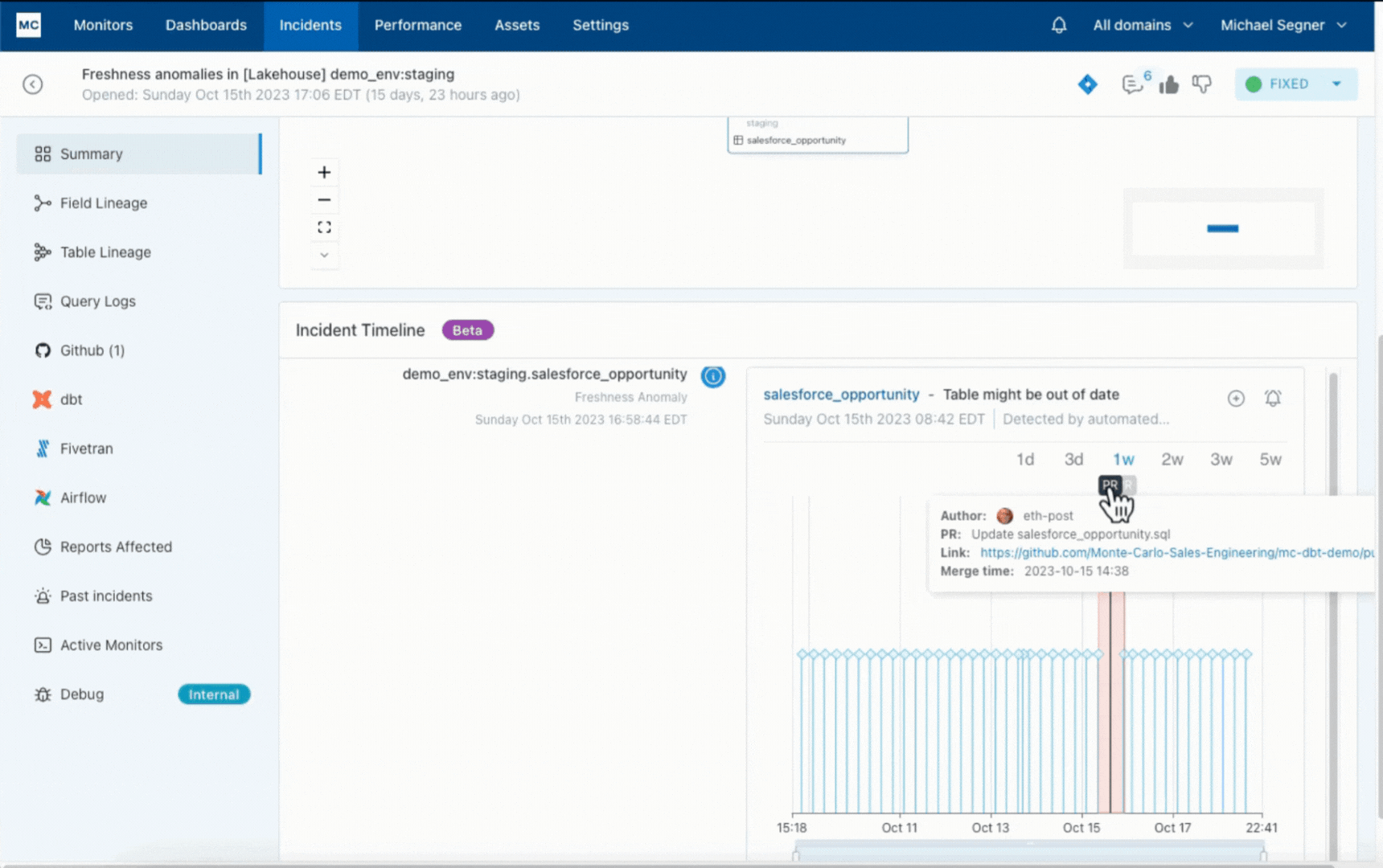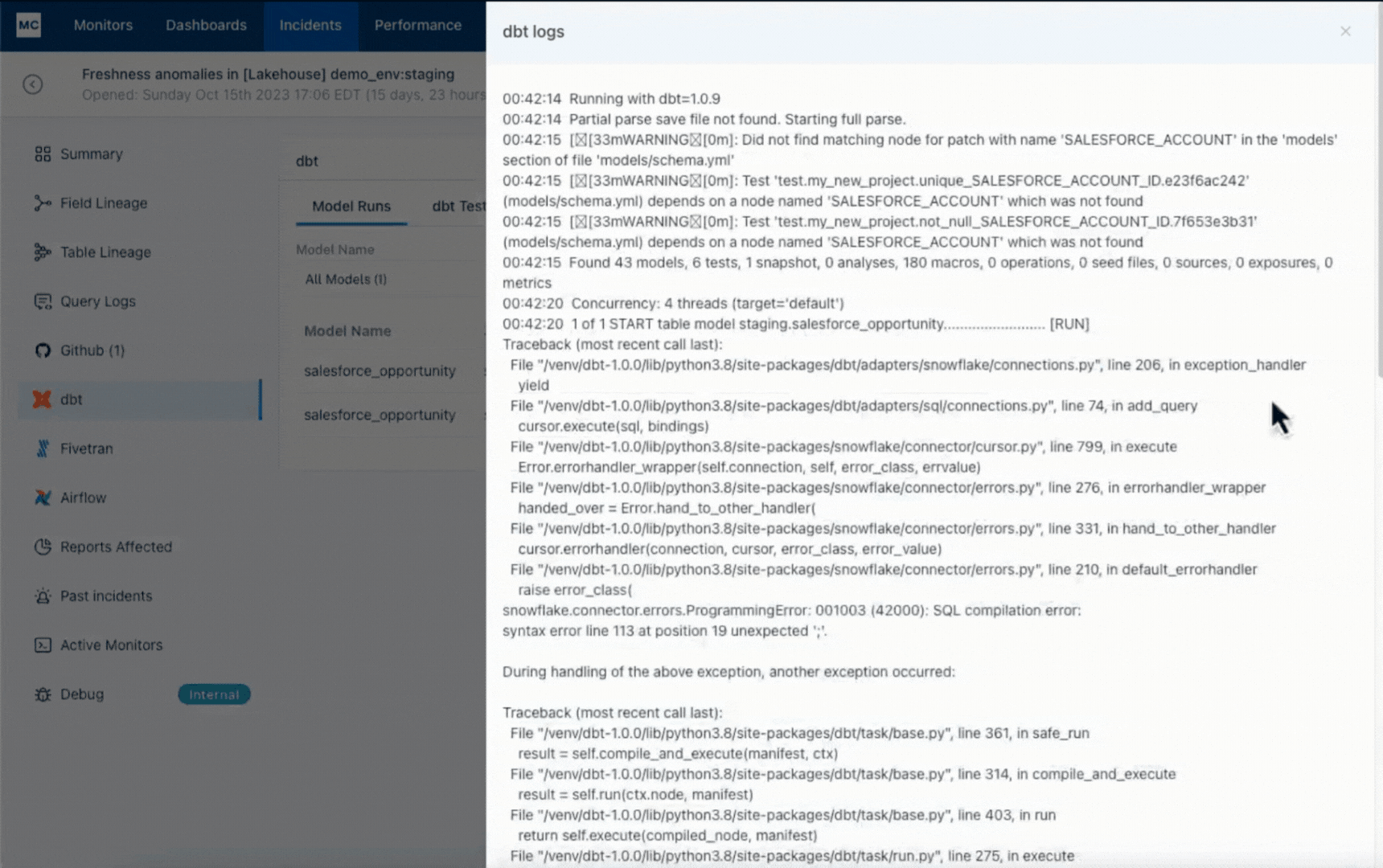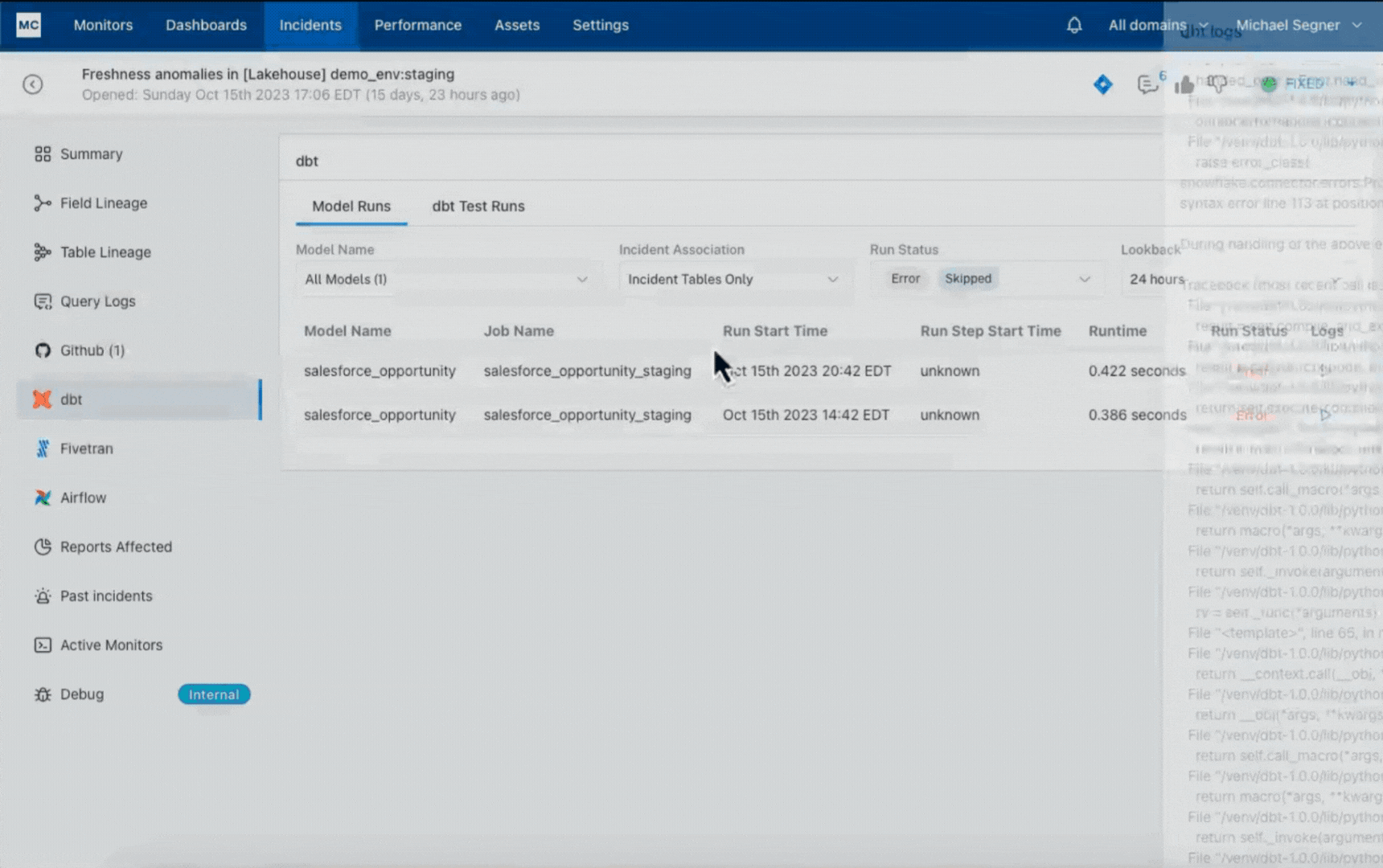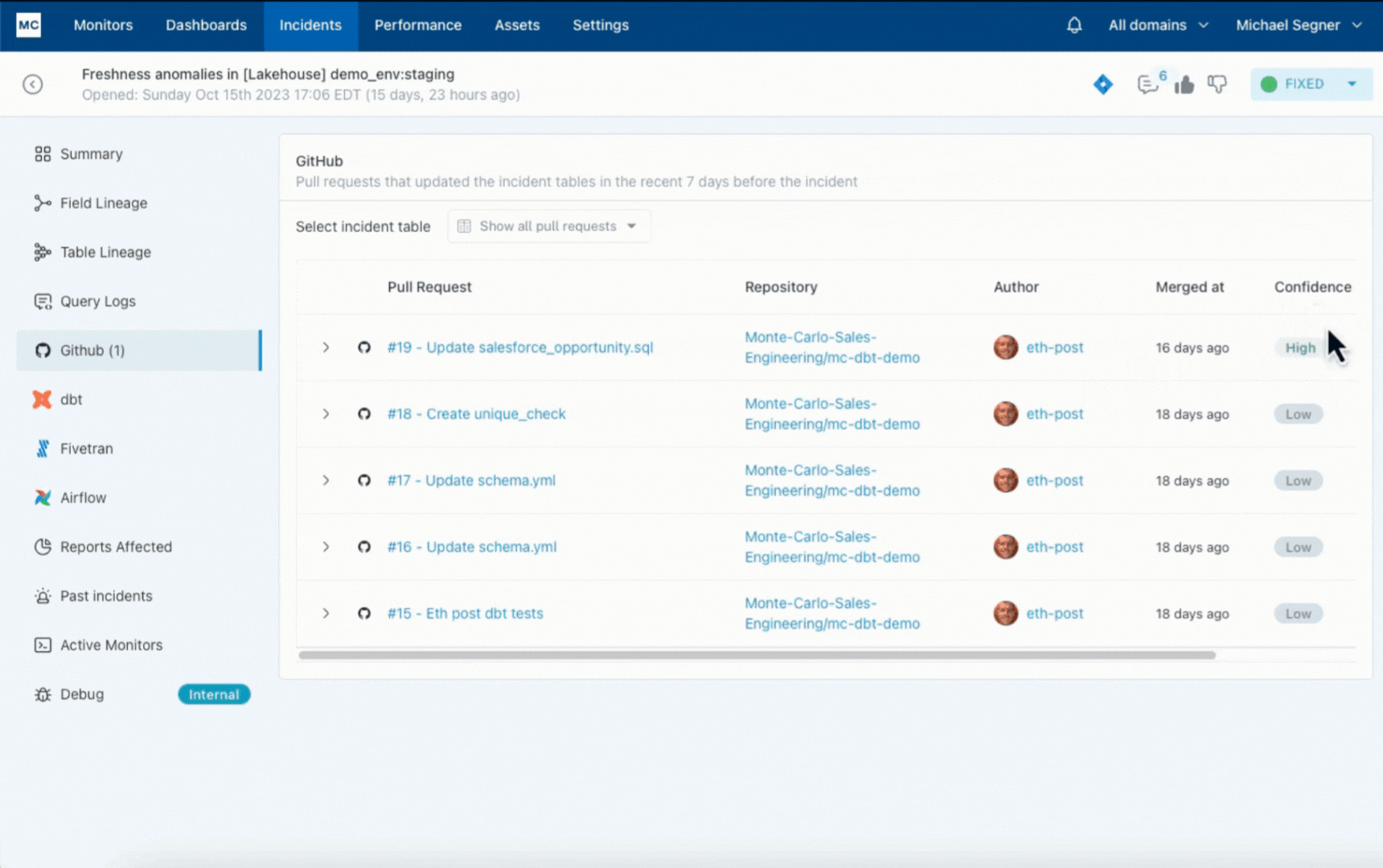
Data observability is characterized by the ability to accelerate root cause analysis across data, system, and code and to proactively set data health SLAs across the organization, domain, and data product levels.
The need for speed (and efficiency)
Data engineers are going to be building more pipelines faster (thanks Gen AI!) and tech debt is going to be accumulating right alongside it. That means degraded query, DAG, and dbt model performance.
Slow running data pipelines cost more, are less reliable, and deliver poor data consumer experience. That won’t cut it in the AI era when data is needed as soon as possible. Especially not when the economy is forcing everyone to take a judicious approach with expense.
That means pipelines need to be optimized and monitored for performance. Data observability has to cater for it.
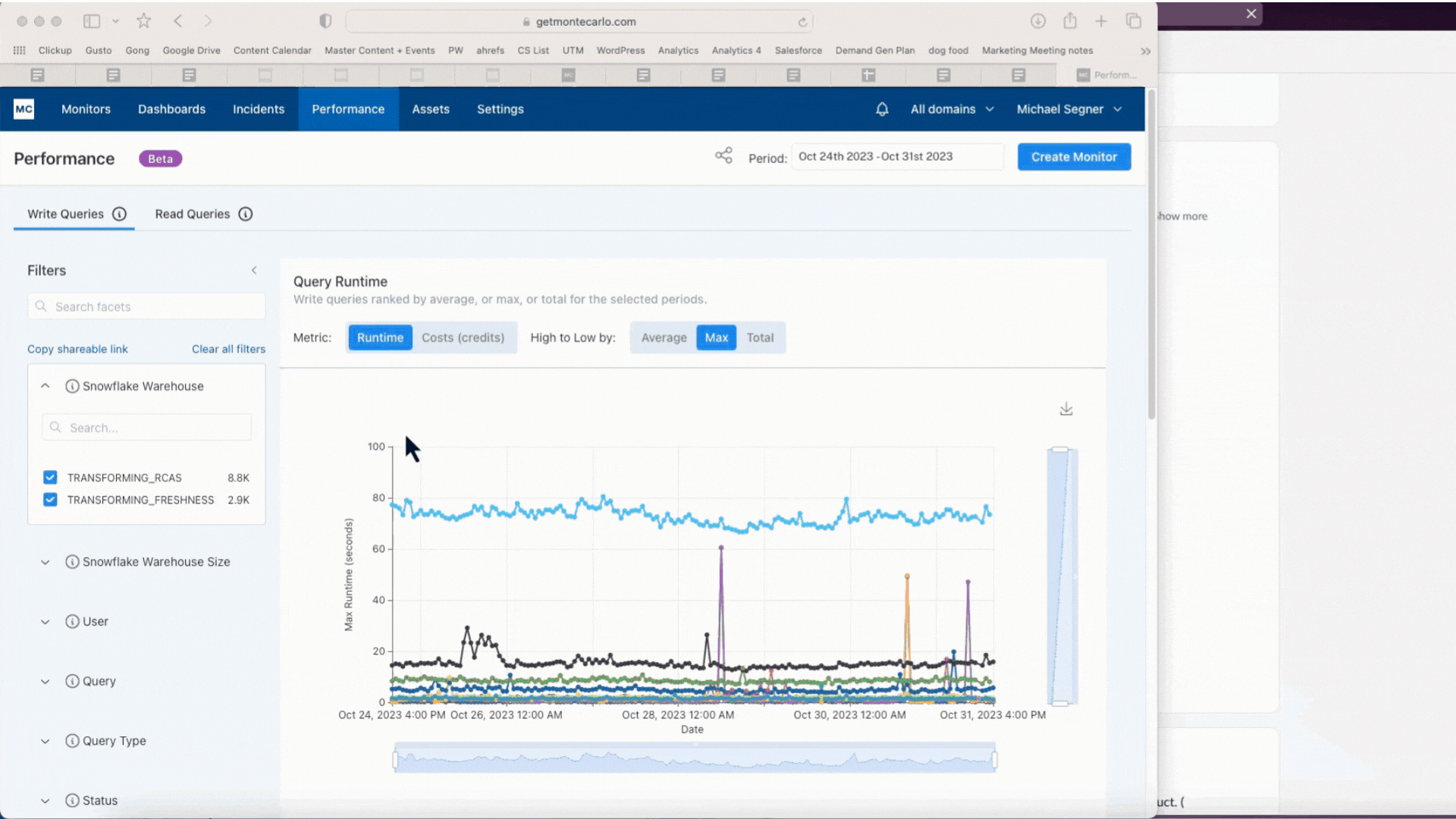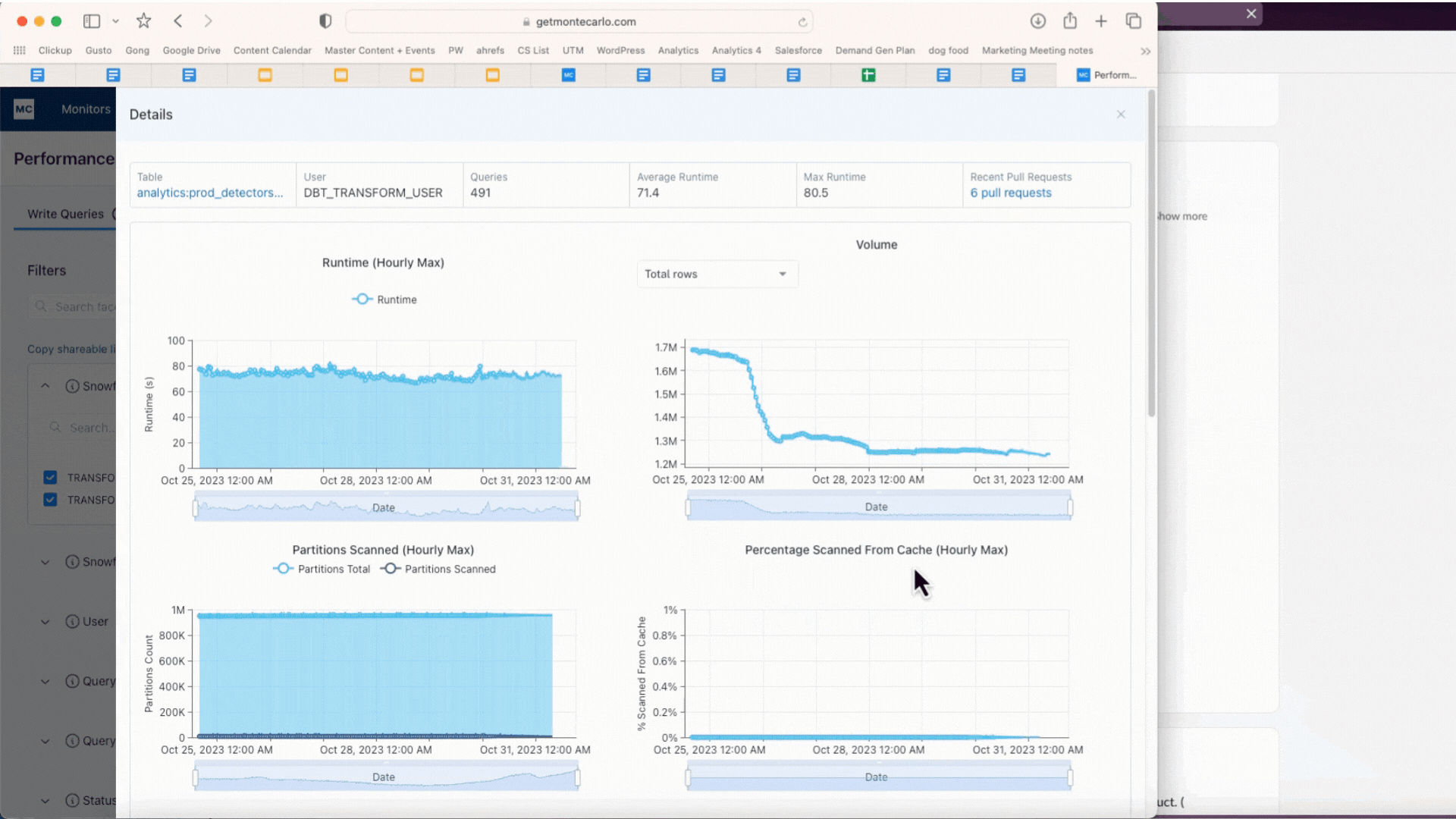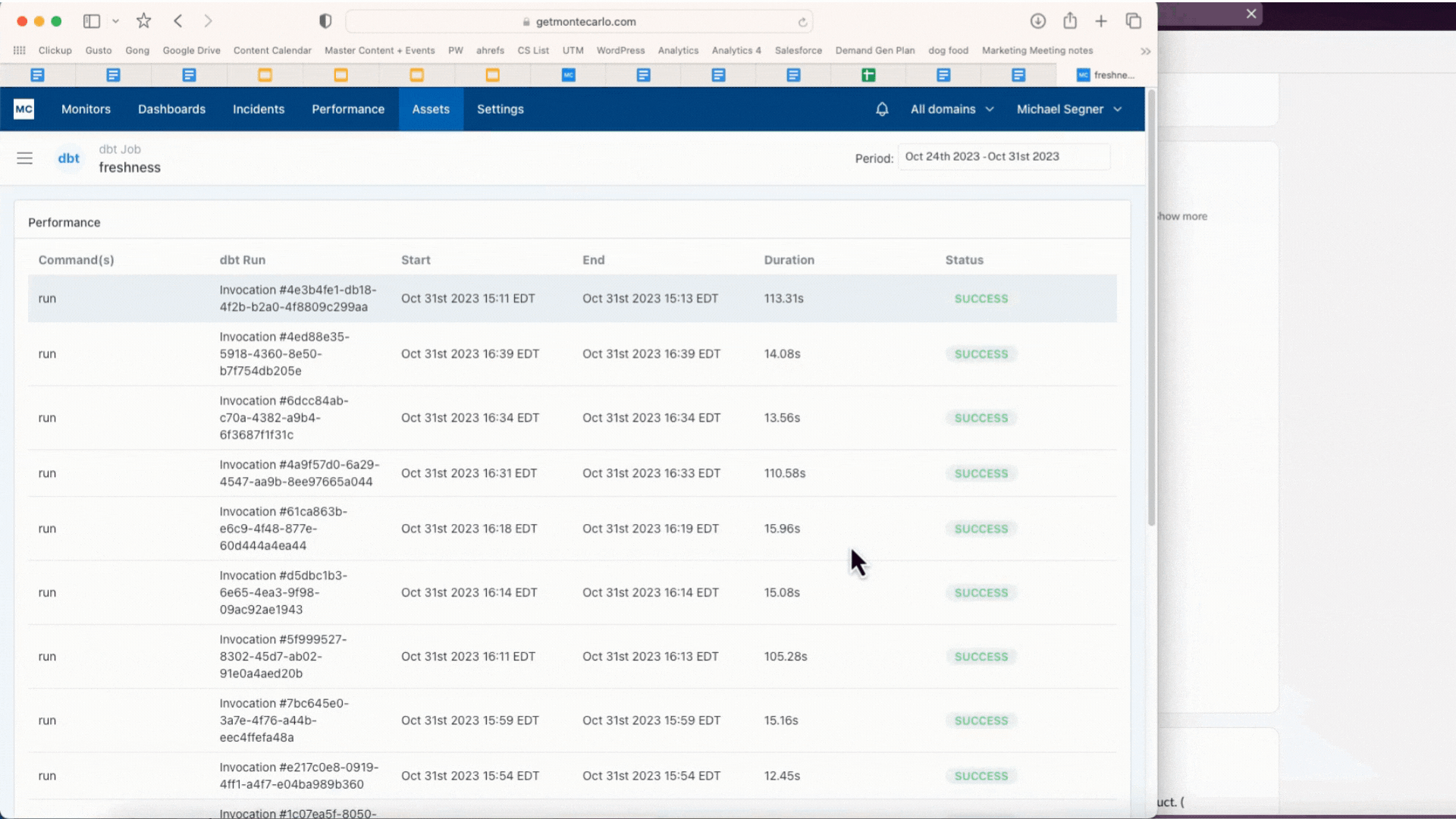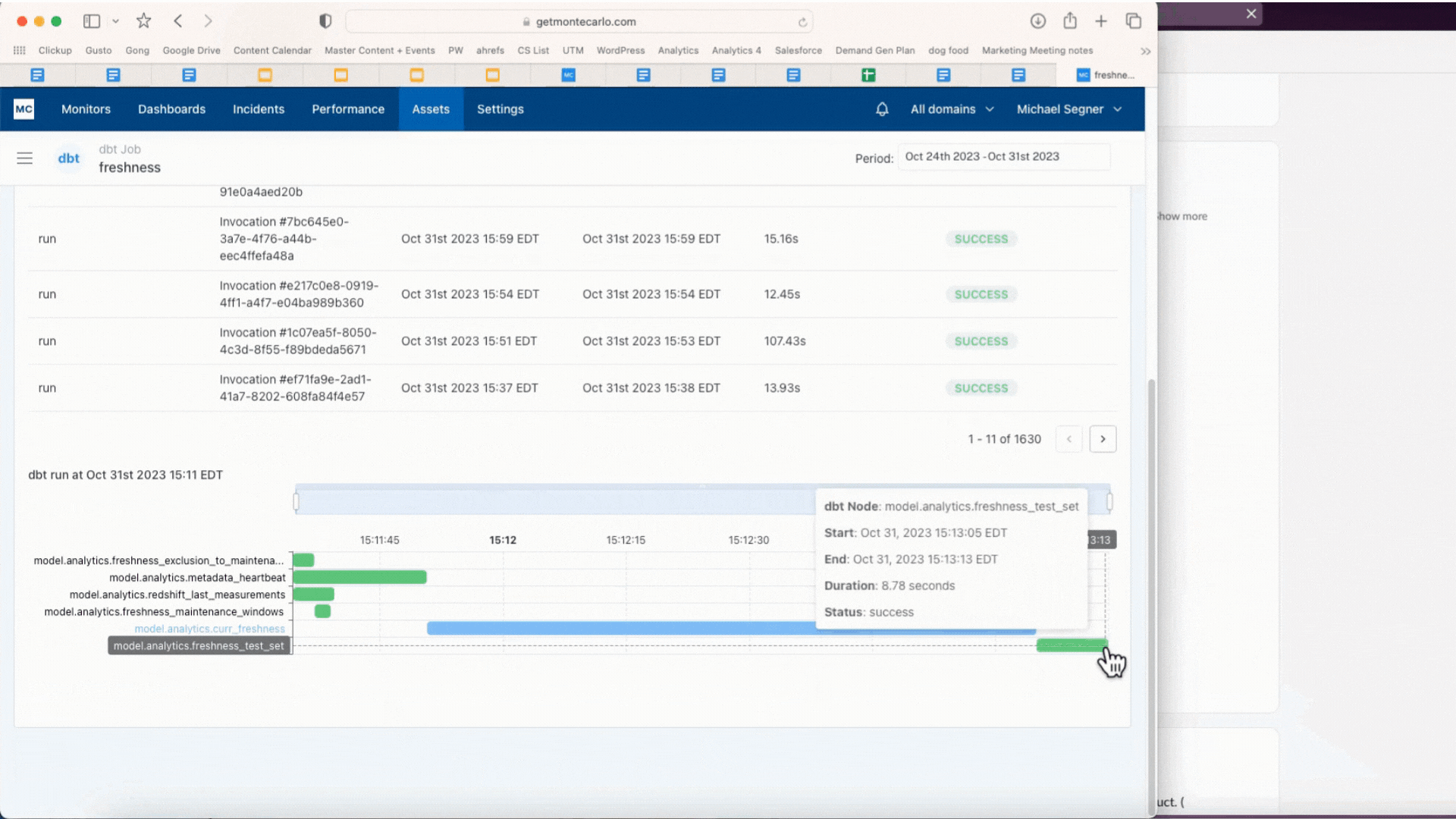
We built Performance to help. It allows users to set alerts for queries that run too long or burn too many credits. Users can then drill down to understand how changes to the code, DAG, partitioning, warehouse configuration and other factors may have contributed to the issue, helping optimize the pipeline. It also delivers rich and powerful analytics to help identify the least performant and most costly bottlenecks in any environment or dbt/Airflow DAG.
Observing the GenAI data stack
This will shock no one who has been in the data engineering or machine learning space for the last few years, but LLMs perform better in areas where the data is well-defined, structured, and accurate.
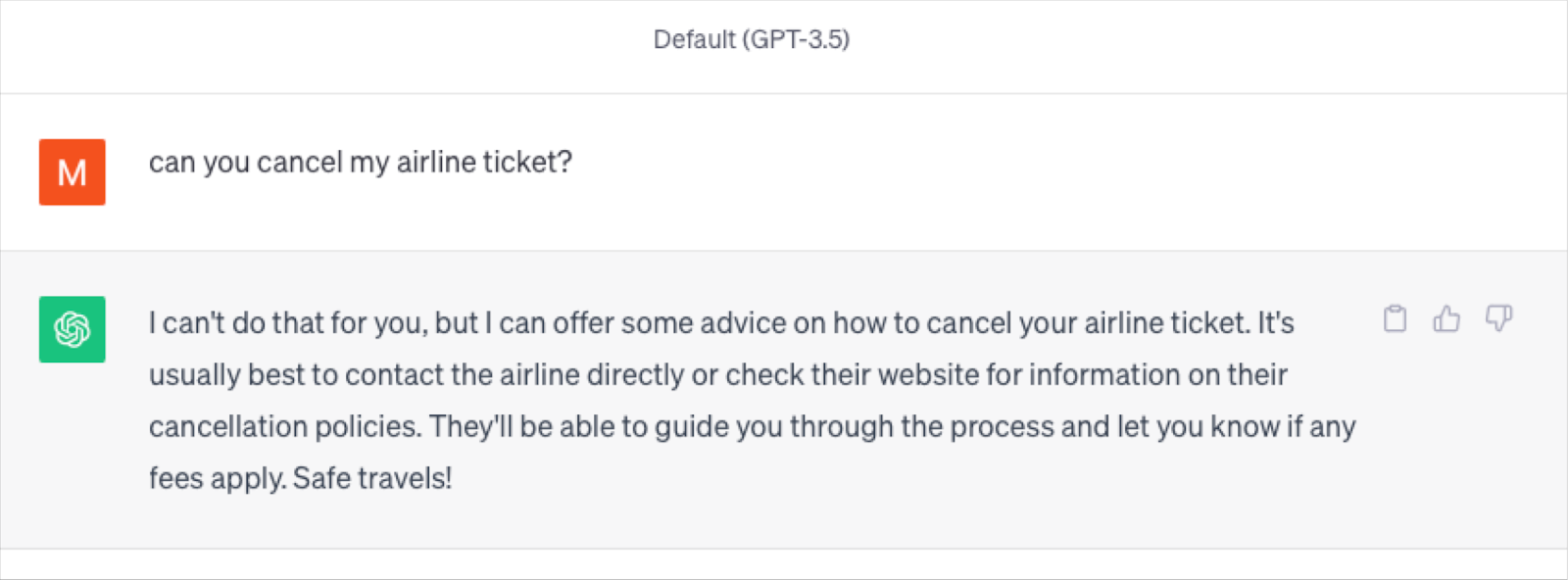
Not to mention, there are few enterprise problems to be solved that don’t require at least some context of the enterprise. This is typically proprietary data – whether it is user ids, transaction history, shipping times or unstructured data from internal documents, images and videos. These are typically held in a data warehouse/lakehouse. I can’t tell a Gen AI chatbot to cancel my order if it doesn’t have any idea of who I am, my past interactions, or the company cancellation policy.
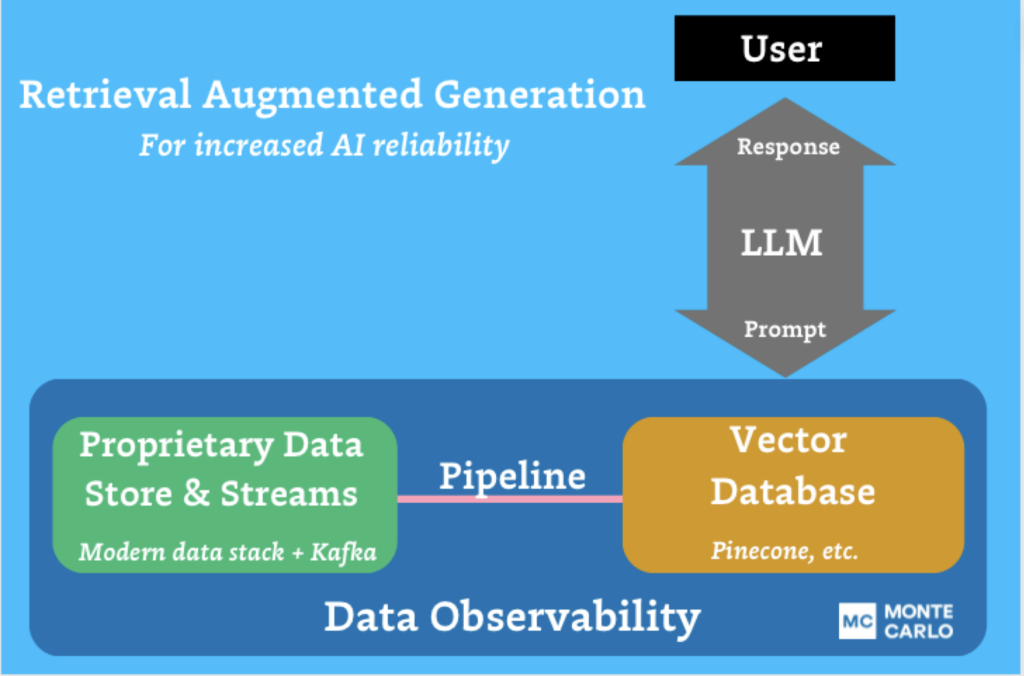
To solve these challenges, organizations are typically turning to RAG or pre-training/fine tuning approaches, both of which require smart and reliable data pipelines. In an (oversimplified) nutshell, RAG involves providing the LLM additional context through a database (oftentimes a vector database…) that is regularly ingesting data from a pipeline, while fine tuning or pre-training involves tailoring how the LLM performs on specific or specialized types of requests by providing it a training corpus of similar data points.
Data observability needs to help data teams deliver reliability and trust in this emerging stack. Monte Carlo is leading the way by helping to observe the pipelines used in RAG/fine tuning. To fully realize our vision of end to end coverage of the stack data teams use, we were excited to announce upcoming direct support for vector databases like Pinecone. This will ensure that data teams can operate reliable RAG architectures. We were also proud to announce that, by the end of the year, Monte Carlo will integrate with Apache Kafka through Confluent Cloud. This will enable data teams to ensure that the historically difficult to monitor real-time data feeding their AI and ML models is both accurate and reliable for business use cases.
In the era of AI, data engineering is more important than ever
Data engineering has never been a slowly evolving field. If we started talking to you ten years ago about Spark clusters you would have politely nodded your head and then crossed the street.
To paraphrase a Greek data engineer philosopher, the only constant is change. To this we would add, the only constants in data engineering are the eternal requirements for more. More data, more reliability, and more speed (but at less cost please and thank you).
Gen AI will be no different, and we see data observability as an essential bridge to this future that is suddenly here.
Want to learn more? Chat with our team.
Our promise: we will show you the product.
Read more posts.