Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monte Carlo’s Newest Feature Optimizes Data Product Performance and Cost

Mei Tao
Product at Monte Carlo

Michael Segner
Michael writes about data engineering, data quality, and data teams.
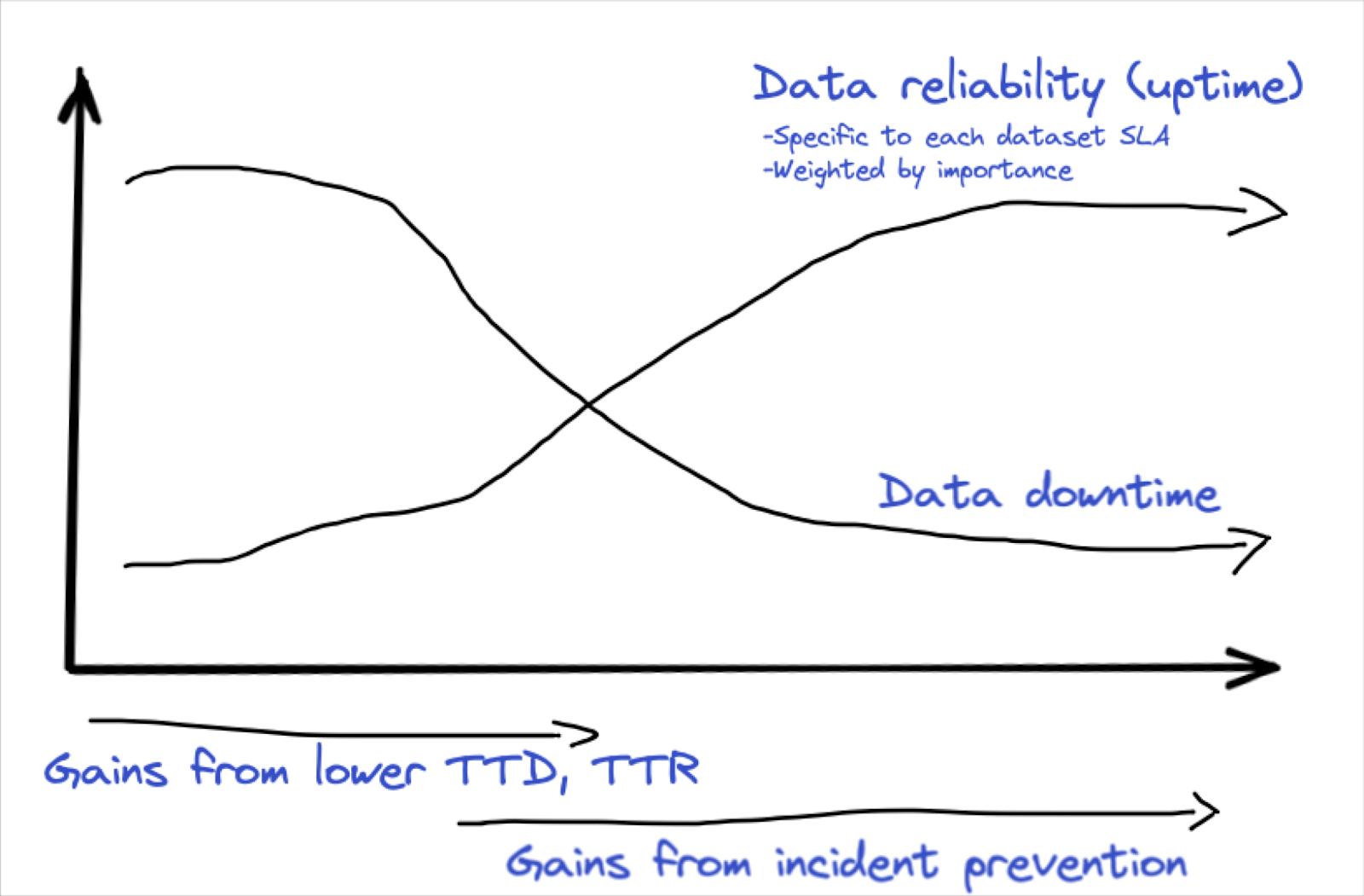
Slow running data pipelines cost data teams time, money, and goodwill. They utilize excess compute, cause data quality issues, and create a poor user experience for data consumers that must wait in exasperation for data to return, dashboards to load, and AI models to update.
While it’s not difficult to identify long-running queries, it is much more challenging to identify the queries that are unnecessarily long and determine the root cause. Understanding which queries are part of, or are dependent on, different components of a data pipeline can be like putting together a jigsaw puzzle while blindfolded.
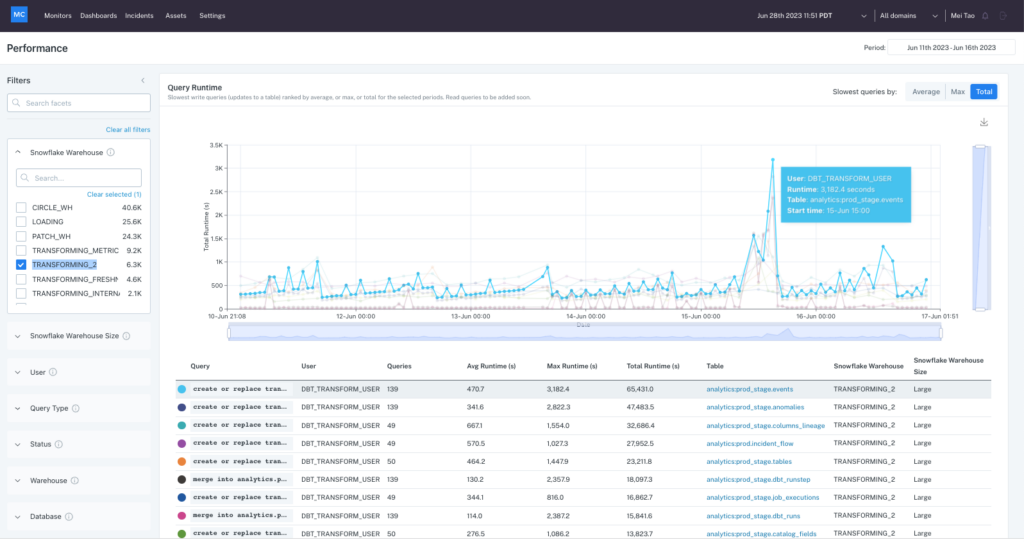
Performance, the newest release in Monte Carlo’s data observability platform, solves these issues by allowing users to easily filter queries related to specific DAGs, users, dbt models, warehouses, or datasets. Users can then drill down to spot anomalies and determine how performance was impacted by changes in code, data, and warehouse configuration.
Performance has received rave reviews from more than a dozen beta customers. One ecommerce company was able to investigate and improve their poor performing dbt models, while a personal care product company used Performance to detect and disable a query taking up a disproportionate amount of compute within a BigQuery slot.
Proactively optimize your most important data products
Let’s say you want to make sure the “metrics” Airflow DAG completes on time every morning so your most critical dashboards are populated with fresh data when your users come online.
You can hop into Performance to analyze the longest-running queries for that DAG and determine if the root cause is related to increases in data volume, changes in the queries, warehouse queuing time, and other factors of performance.
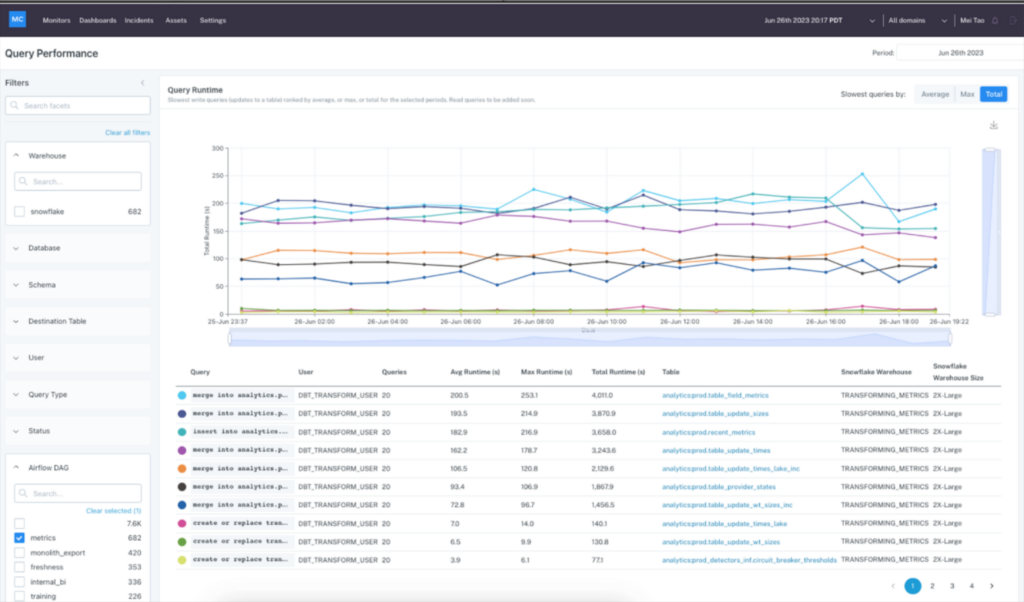
You can explore the data in multiple views, allowing you to understand how slow and costly queries impact bottlenecks in your Airflow or dbt DAGs.
Quickly investigate and troubleshoot known performance issues
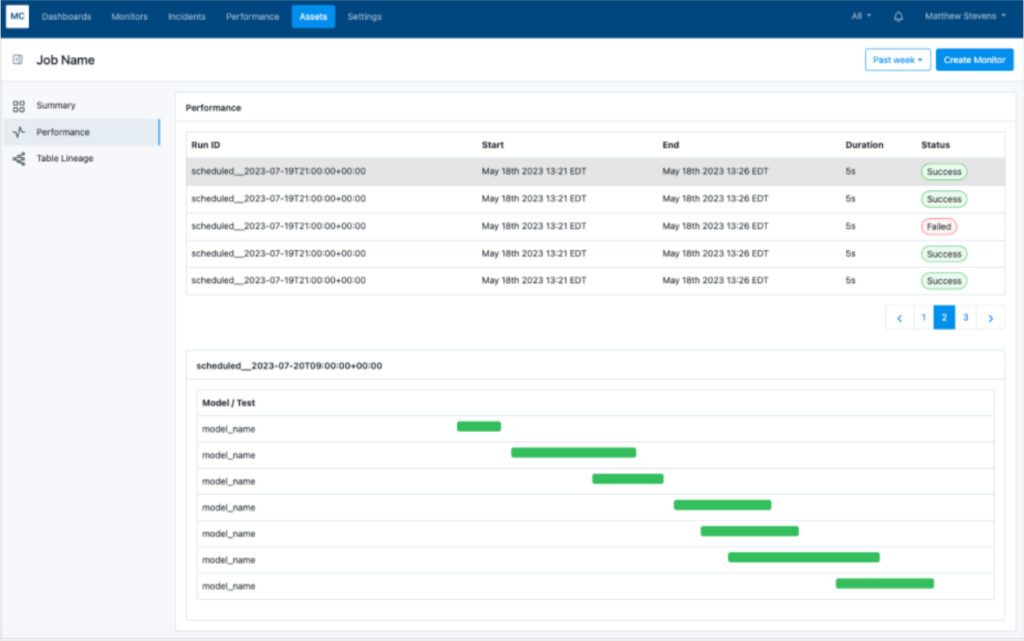
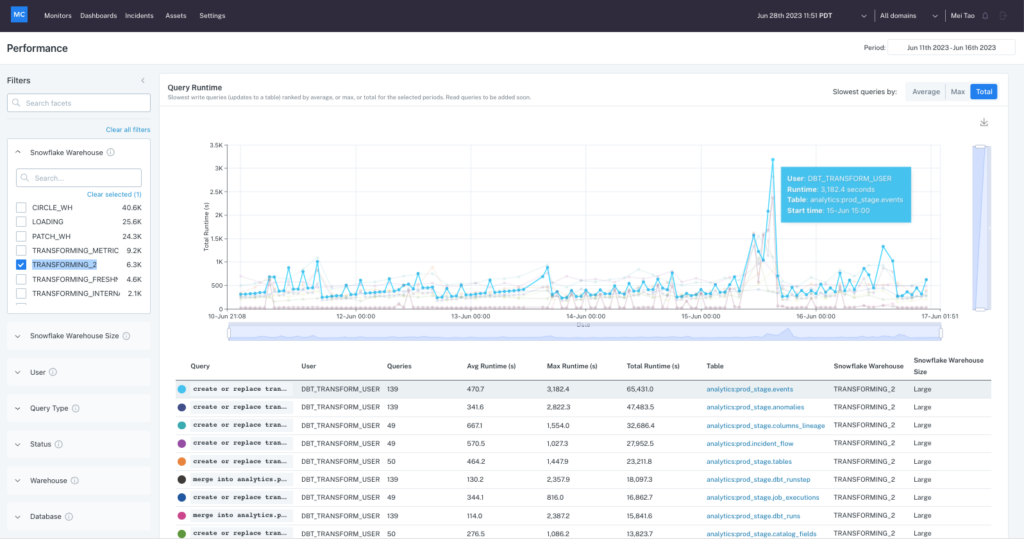
Performance also helps teams quickly get to the root of known performance issues. For example, let’s say a resource monitor has alerted the team that the Snowflake data warehouse, “TRANSFORMING_METRX,” has exceeded its threshold. This could drive unwanted costs.
Now it’s time to figure out why. You can view all the query runtimes for that warehouse during the time period when the alert was triggered.
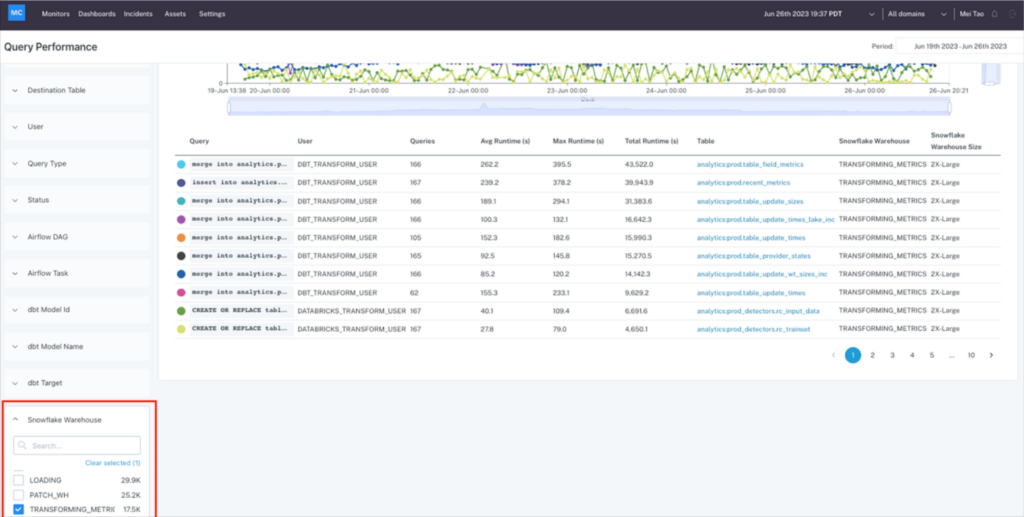
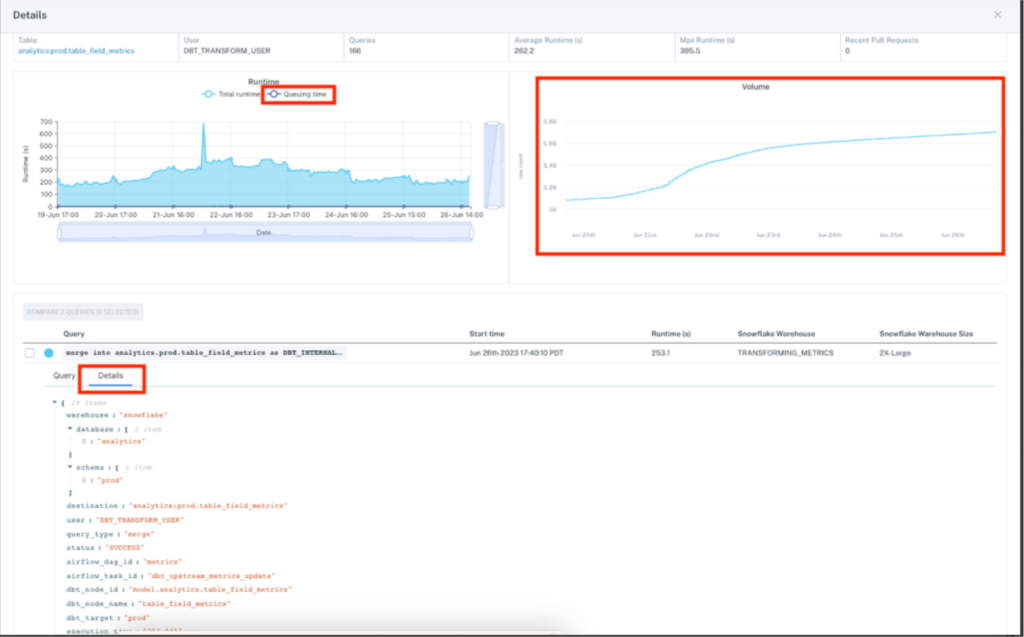
Then drill into the top queries to determine how a variety of data, code and infrastructure factors interplayed to create the issue. Query samples and metadata are at your fingertips to further drill into metrics that may have affected individual runs like cache performance or partitioning.
Performance and reliability all within one powerful data observability platform
Performance adds another way for data teams to leverage Monte Carlo’s data observability platform to proactively reduce data downtime and enhance data reliability.
“A dashboard that runs too slowly has a direct impact on the quality–and therefore perceived reliability–of that dashboard,” said Lior Gavish, co-founder and chief technology officer, Monte Carlo. “Performance will also provide significant value to our customers that care about optimizing performance and costs in this economic climate – and beyond.”
Currently, the performance dashboard is available to all Monte Carlo customers utilizing Snowflake, BigQuery, or Redshift as their data platform. Additional integrations, alerting, and root cause analysis functionality is planned. To see the new dashboard or the entire data observability platform in action, request a demo. You can schedule a time with us filling out the form below.
Our promise: we will show you the product.
Read more posts.