Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Pioneering Data Observability: Data, Code, Infrastructure, & AI


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Molly Vorwerck
Molly is Head of Content & Communications @ Monte Carlo.
When we launched the data observability category in 2019, the term was something we could barely pronounce.
Four years later, the category has squarely established itself as a core layer of the modern data stack. Data Observability is a G2 category, recognized by Gartner, Forrester, and more, and most importantly, widely adopted by hundreds of companies, including some of the world’s most advanced data organizations.
In fact, the CTO of a fast growing company told me recently: “This is the secular trend given how the world is changing. Data observability was going to happen sooner or later and there’s nothing anyone can do to stop it.”
While I still can’t always pronounce it (ESL, anyone?), data observability has become a must have for modern data teams, and I couldn’t be prouder of how far this movement has come – and where we’re going.
So, what’s in store for the future of data reliability? To understand where we’re going, it helps to first take a step back and assess how far we’ve come.
Where we started
In the mid-2010s, data teams began migrating to the cloud and adopting data storage and compute technologies – Redshift, Snowflake, Databricks, GCP, oh my! – to meet the growing demand for analytics. The cloud made data faster to process, easier to transform and far more accessible.
As data became more ubiquitous, pipelines grew more complex, new personas entered the scene to manage this chaos (hello, data engineers), and the number of possible use cases exploded.
The upside? More informed decision making, more data use cases, and smarter software.
The downside? The basics – like data quality – were neglected and took a back seat to shinier parts of this modern data stack.
In a past life, I saw firsthand the implications of bad data. 5 a.m. pings from our CFO when “the data looks wrong.” Sticky notes on my computer monitor from stakeholders when dashboards failed to update. Frustrated customers scratching their heads because our product was fed inaccurate data.
Data observability was born from this pain – what we referred to as data downtime – and offered a tangible solution. Inspired by application observability and site reliability engineering, data observability monitors and alerts organizations to data incidents before they impact the business. Data observability offered an automated, process-driven alternative to achieving data reliability that cut costs, drove growth, and substantially reduced 5 a.m. fire drills.
Historically, the strongest data observability approaches incorporate three main stages: detection, resolution, and prevention.
- Detection: Data observability detects anomalies and other issues in your data and alerts the appropriate owners on the data team before stakeholders find out.
- Resolution: Simultaneously, data observability platforms give teams the tools to resolve the issue, including field-level lineage, automated root cause analysis and impact analysis, information about past incidents affecting that asset, related query logs and dbt models, affected reports, and more.
- Prevention: Finally, data observability also provides mechanisms to prevent data issues from happening in the first place, like placing circuit breaking in pipelines and creating visibility around the impact code changes would make on data, among other proactive measures of preventing bad data from entering your pipelines in the first place.
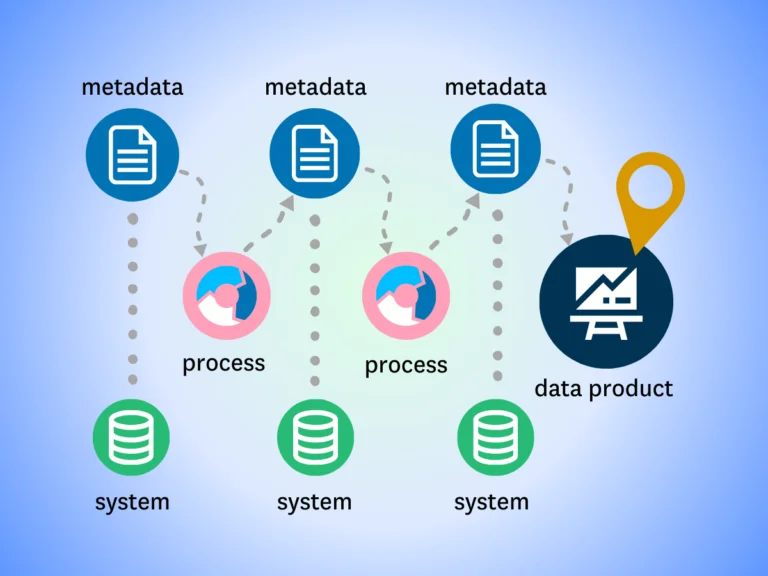
In the beginning, data observability focused exclusively on detecting, resolving, and preventing data issues by leveraging both metadata and the data itself to piece together a picture of data health. By monitoring and alerting to issues in data from ingestion to consumption, teams could detect changes in upstream tables that weren’t anticipated, which caused downstream sources to break or become unreliable.
Extending Detection and Resolution Beyond Data
However, like any industry, the data space evolved, impacting the way teams need to think about incident detection and resolution, and data observability more broadly. This evolution is owing to a few exciting trends: the rise of data products and, as a result, the ongoing migration of data teams closer to or directly into the Engineering org.
As data teams increase their scope in the organization and data use cases grow, the data team is more impactful to the bottomline than ever before. Now, everyone across the business leverages data every day to drive insights, power digital services, and train ML models. In fact, we’ve gone beyond simply treating data like a product. In 2023, data IS a product.
Hundreds of customers later, including teams at Pepsi, Gusto, MasterClass, and Vimeo, and what we’ve discovered is that we need to look beyond just the data to achieve data reliability. Unreliable data doesn’t live in a silo… it’s impacted by all three ingredients of the data ecosystem: data + code + infrastructure.
This broader vision reflects how our friends in software engineering tackle detection and resolution, too. Application observability starts with infrastructure but analyzes way more than that to detect and resolve software downtime; root cause analysis takes into account code, infrastructure, services, network and plenty of other factors. For software engineers, reliability isn’t achieved in a vacuum – it’s often impacted by multiple factors, frequently acting in tandem or compounding on one another.
In data, the scenario is often the same and it’s time we start treating it that way.
Let’s walk through a hypothetical example from the data world.
Imagine you have a dashboard showing stale results. You might first look at your data, in this case, perhaps an upstream table ingested from Google describing your ad campaigns. Did someone change a campaign name, breaking a hardcoded data pipeline? Or perhaps you’re getting nulls instead of user UUIDs in your click events table? No dice, so what’s next?
You look at the code. Maybe your analytics engineer made a change to your SQL that filters out the most recent data? They had good intentions, but perhaps it had unintended consequences? You take a peek into your dbt repo. Nope – all good there.
Finally, you look at your infrastructure. You quickly click over to your Airflow UI – maybe you’re running Airflow on a small instance and it ran out of memory (shouldn’t have loaded those rows into memory!!), causing the downstream freshness issue. Eureka – you’ve found it!
Experience teaches us that all three factors contribute meaningfully to data downtime. So no matter where you look first, you are in for a long, tedious process of making educated guesses and eliminating them one by one. Oh, and did we mention it requires access to and proficiency in the 8 different tools that make up your data stack?
Now, imagine you could quickly correlate the symptom you’re seeing (stale dashboard…) with all the changes that have happened to the data, to code and to infrastructure. Oh, and you don’t need a PHD in statistics or 10 years experience in the company knowing every single column in the data warehouse. It’s all at your fingertips – an end-to-end understanding of how data, code and infrastructure worked together to result in a broken dashboard. Think about all the time and resources you could have saved and stakeholder frustration you could have avoided, not to mention the early morning wakeup call.

To truly realize the potential of data observability and achieve reliable data, teams need to take a three-tiered approach that weaves together a comprehensive picture of the data, code, and infrastructure impacting data health.
What we’ve also come to realize is that achieving data reliability is not just about turning on a tool. It’s about creating a new discipline on the team – an operational mindset if you will. Teams need to introduce processes around monitoring data systems, responding to incidents and iteratively getting better over time.
Organizational structures, processes, and technologies must evolve to accomplish those goals. Think: dashboards that define and monitor the reliability of data products based on the upstream tables powering them that can be easily shared across the org for transparency, collaboration and accountability. And domains that segment data and pipelines based on use case and owners for targeted triaging and incident resolution.
Reliable Data and the Future of AI
Betting on large language models (LLMs) as the future of [insert industry here] is almost cliché at this point, but the impact on the data industry is different.
Current generative AI use cases in data and engineering are focused almost exclusively on scaling productivity, like GitHub Co-Pilot, Snowflake Document AI, and Databricks LakehouseIQ. In many ways, we don’t know what the future of Generative AI will hold but we do know that data teams will play a big part in its success.
There’s an exciting opportunity for LLMs to help with data quality, but the even more powerful thesis is that data quality and reliability can help LLMs. In fact, I’d argue LLMs serving production use cases cannot exist without a solid foundation: having lots of high quality, reliable, trusted data.
By and large, the vast majority of generative AI applications today are hosted in the cloud and surfaced with an API. To support them, you need a robust, cloud-based data stack to reliably store, transform, train, and serve the data powering them.
Echoing this sentiment, during Snowflake’s Q1 2023 earnings call, Frank Slootman, CEO of Snowflake, argued that “generative AI is powered by data. That’s how models train and become progressively more interesting and relevant… You cannot just indiscriminately let these [LLMs] loose on data that people don’t understand in terms of its quality and its definition and its lineage.”
We’ve already seen the implications of unreliable model training. Just last year, Equifax, the global credit giant, shared that an ML model trained on bad data caused them to send lenders incorrect credit scores for millions of consumers. And not long before that, Unity Technologies reported a revenue loss of $110M due to bad ads data fueling its targeting algorithms. In the coming years, this will inevitably become an even bigger problem unless we prioritize trust.
As we witness the rise of AI applications for the enterprise in the coming years, data observability will emerge as a critical capability to support LLMs and all other AI use cases.
As Databricks co-founders Matei Zaharia, Patrick Wendell, Reynold Xin and Ali Ghodsi suggest: “Enterprise applications also have little tolerance for hallucinations or incorrect responses… In every stage of the machine learning lifecycle, the data and models must be jointly curated in order to build the best applications. This is even more important for generative models, where quality and safety depend so much on good training data.”
I couldn’t agree more. First step to better, more impactful AI? Good, reliable data – and lots of it. We’re excited to continue partnering with our customers on what this future looks like.
Join us, won’t you?
Learn how leading data teams at JetBlue, Vimeo, Affirm, and more companies are pioneering the next phase of Data Observability with Monte Carlo and achieving end-to-end data reliability.
Request a demo today.
Our promise: we will show you the product.
Read more posts.