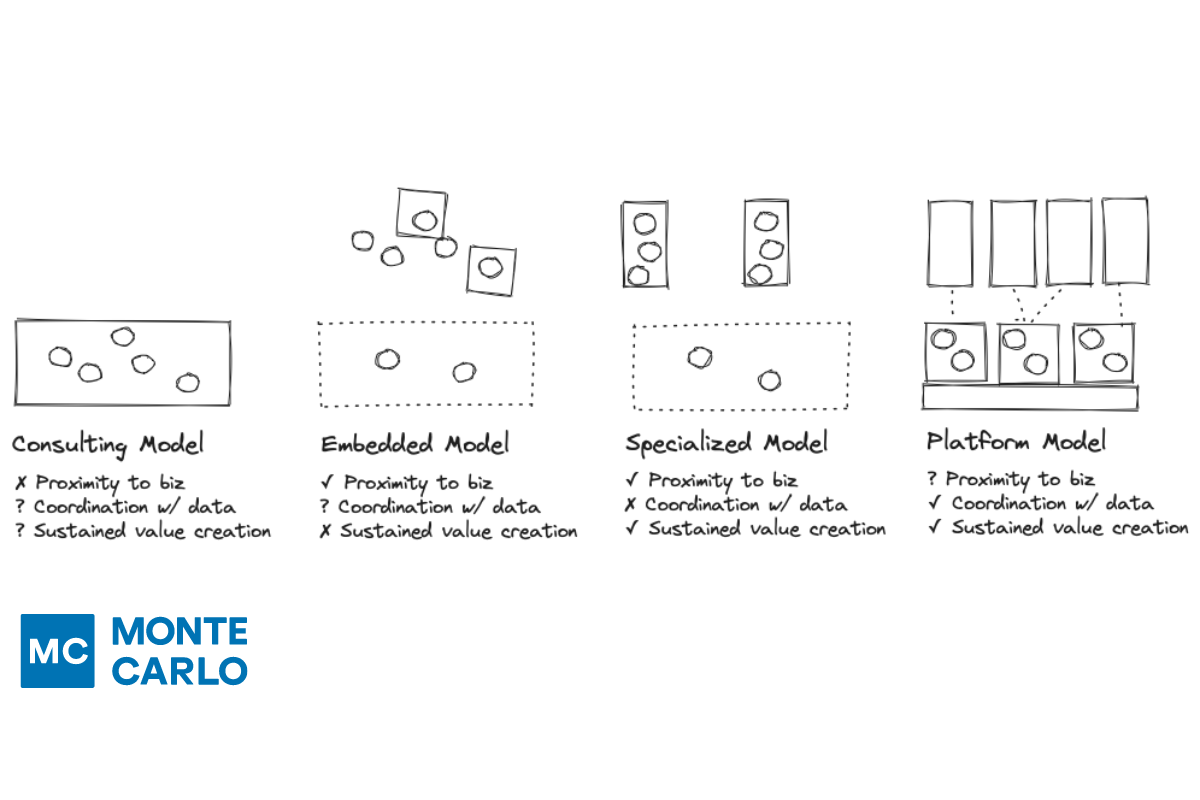
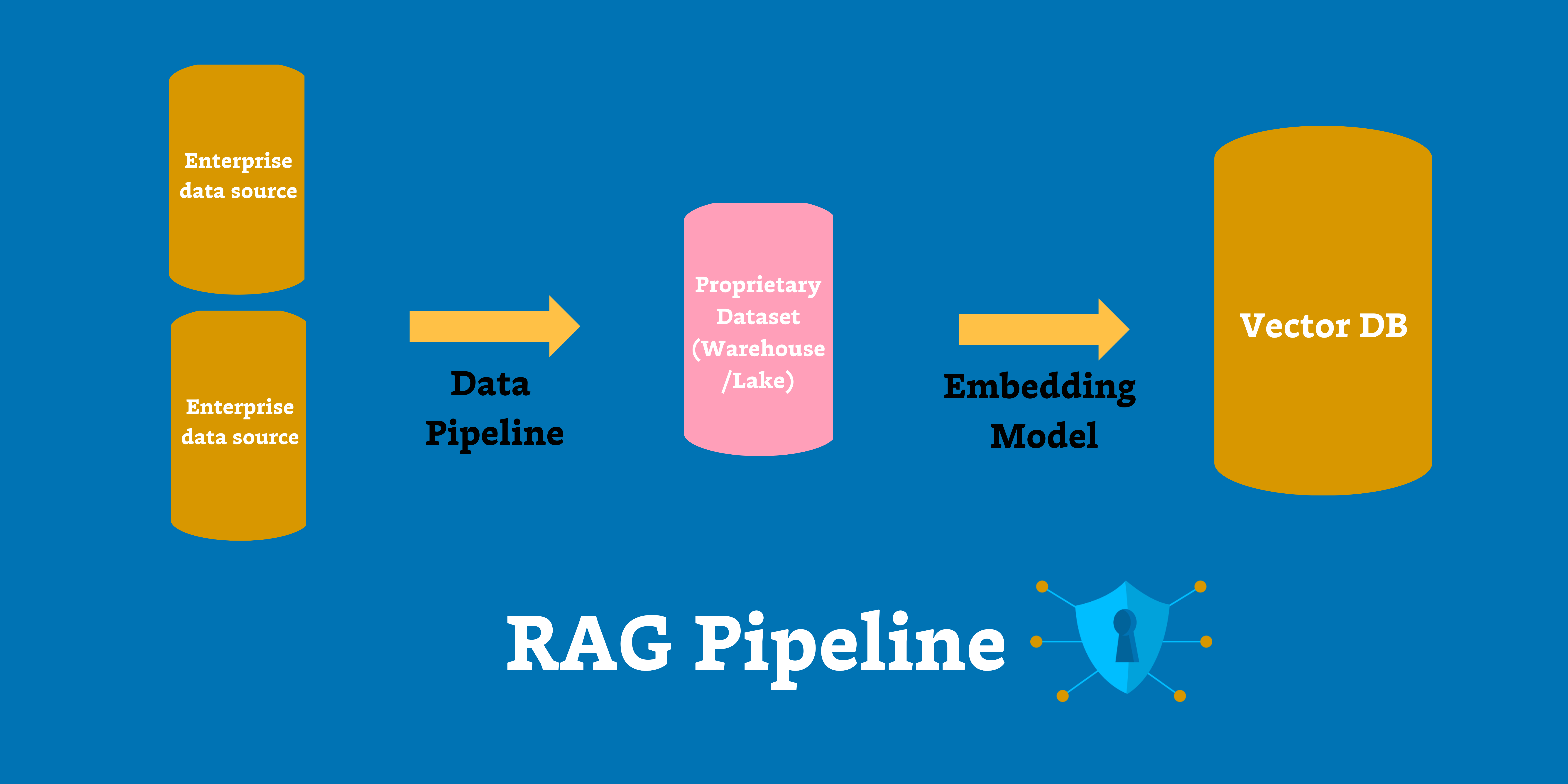
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 4 GenAI Opportunities from Real Data Teams


Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
The funny thing about hype is that it’s always at its apex when information is at its lowest. And GenAI is no different.
A lot of organizations want to talk about AI, but it’s tough to find teams that are actually leveraging it in a meaningful way. (Although, we did create the above image using DALL-E, and I think you could say it’s pretty meaningful.) But, when you find a data leader who’s on the real AI journey first-hand (no, not Midjourney), it’s natural to have a few questions.
That’s why I sat down with Dustin Shoup, Principal Data Engineer at PayNearMe; Mike Carpenter, Senior Manager of Data Strategy and Analytics at Mission Lane; and Dana Neufeld, Data Product Manager at Fundbox during our recent Data Quality Day to understand their strategies for operationalizing generative AI use cases—and how data quality is impacting the process.
Interested? Let’s dive in.
Table of Contents
1. Your internal knowledge base is a greenfield for AI
For many organizations, the knowledge base is a central focus point for increasing product value and adoption. The wealth of knowledge stored in their Confluence or Jira instance is like a treasure chest just waiting to be unlocked. And now GenAI offers even more opportunities to do just that—with organizations like Atlassian already offering early examples of this use case.
Now the PayNearMe team is working in the same direction as they leverage GenAI to maximize the value of their extensive knowledge base to their customers. “At PayNearMe, we’re doing a lot of GenAI on our auxiliary business [rather than the core data flow business],” says Dustin.
And the first step for Dustin’s team? Getting their data quality in order.
“We’re working on our infrastructure and getting the right tooling in place, making sure we have the right data quality under the hood,” said Dustin.
“Data quality is key to what we’re doing, and the data quality is already there in the documentation, in Confluence, etc. So, we’re pointing GenAI in that direction, and doing a lot of beta testing…When we know what’s going in, we can better understand what’s coming out.”
2. Self-service is still relevant—and even more so
For Mission Lane, the name of the generative AI game is interoperability. In a world where free money is a thing of the past, data teams are doing everything they can to drive more stakeholder value at scale—and demonstrate that commitment to the executive team.
For the last few years, self-service architecture has been the gold-standard for accelerating value. Building a self-service culture meant cost-efficiency, enabling business users and practitioners to leverage existing processes to discover new data, create pipelines, and surface insights. And now GenAI is offering new fuel for the self-service fire.
As the Mission Lane data team has continued to invest in their dbt semantic layer, they’ve recognized an opportunity to leverage Snowflake’s Co-Pilot to create a self-service insight engine.
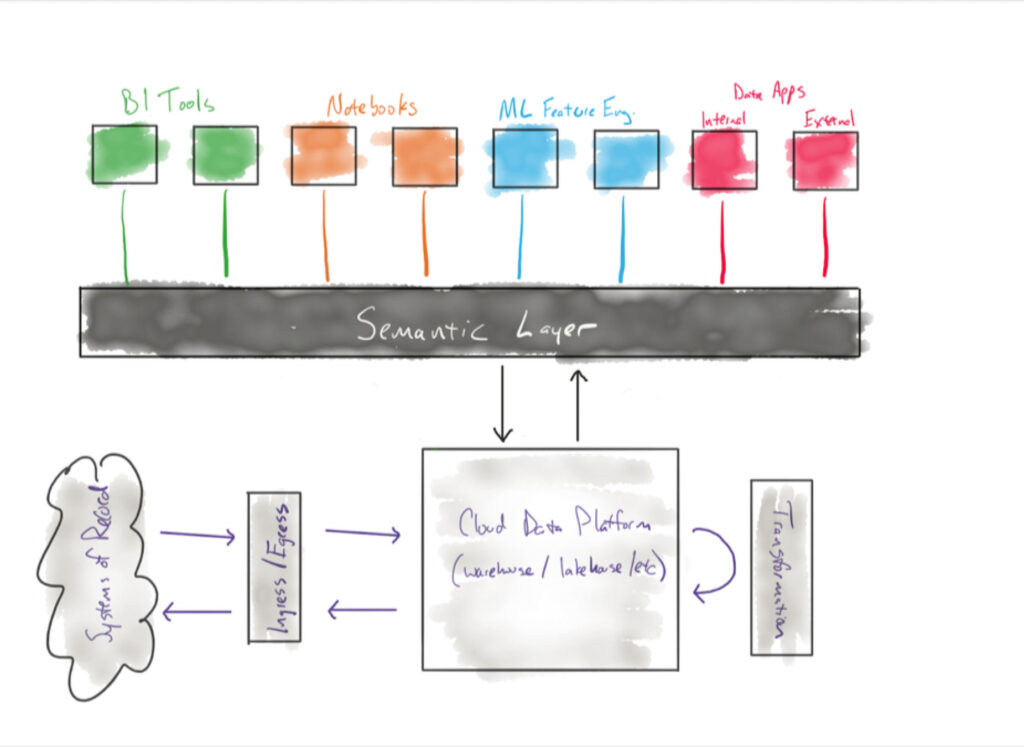
“If we can quantify the quality of our data that’s used in these semantic models and define these semantic definitions, then we can start enabling our non-technical users to query from that using Co-Pilot,” says Mike. “That creates the culture of self-service we’re trying to get to.”
Integrating their semantic layer with Co-Pilot will enable data consumers downstream to surface insights on their own– as long as everyone is clear on the definitions up front.
“When you’re thinking about the semantic layer, a lot of it is about conversation,” says Mike. “The coding aspect is relatively straightforward for a lot of metrics in the dbt semantic layer.” He believes that potential problems arise when there are varying definitions across the organization. “The confusion comes from a lack of communication upfront and defining things incorrectly, and then you end up in the same place you were before.”
The semantic layer can help a business work toward shared goals, but that means establishing common definitions and validating the quality of that data up-front. No understanding and no data quality means no self-service.
While the application of semantic layer as a source for GenAI use cases is purely theoretical at this point, it’s one Mike’s team is exploring intentionally with the hope of launching a proof of concept solution in the coming months as more Snowflake features become generally available.
Watch this space!
3. Data asset optimization is the need of the hour
Imagine if you could ask ChatGPT a question like, “What data assets should I optimize based on daily usage?” Or “What are my top three most expensive data products based on compute costs?”
Dustin, Mike, and Dana agree there’s a significant opportunity to leverage GenAI to optimize internal resources and compute costs.
“The Snowflake budget is a big chunk for many teams,” says Dustin. “Maybe we could run the output of a Snowflake query, plug it into GenAI, and see if the value is there. Do we need to put in engineering time to reduce costs? We can ask the [LLM] some questions, and it can help identify root cause flows that can be reduced.”
Mike agrees. “[We can ask:] what’s the most expensive thing impacting us right now?” This type of GenAI use case not only increases the efficiency of a data team, but it helps to prove the ROI of your data team as well.
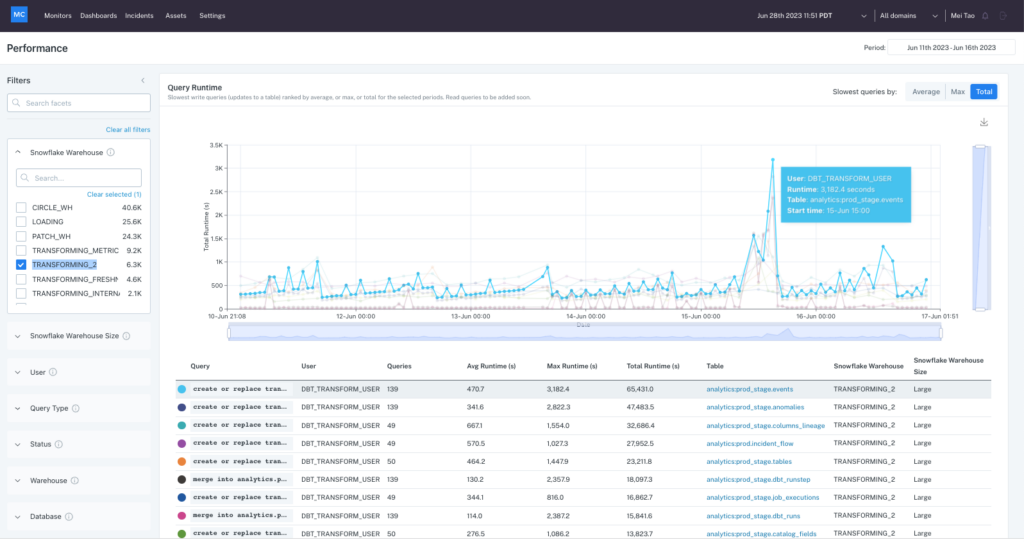
Monte Carlo is already hard at work to develop these types of features for organizations. Monte Carlo’s recently released feature, Performance, allows users to easily filter queries related to specific DAGs, users, dbt models, warehouses, or datasets. Users can then drill down to spot anomalies and determine how query performance was impacted by changes in code, data, and warehouse configuration.
4. The biggest takeaway? Reliable AI needs reliable data.
Unsurprisingly, at the heart of our GenAI discussion was the centrality of data quality. And each of these teams leverage data observability from Monte Carlo to give their teams a comprehensive look into the health of their data across pipelines—including those pipelines feeding GenAI use cases.
“Monte Carlo helps us a ton with visibility into data quality for our users and developers,” says Dana. “We use dbt and insight testing for our developers, and it’s way easier to spot quality issues in the code. Now, we’re looking into integrating Monte Carlo and dbt to gain access to documentation and give better access to our users – through lineage, documentation within the code, etc.”

But it’s not enough for your data team to know that your data is good. Your stakeholders need to know it too—and why it matters.
“The most challenging thing when it comes to data quality is getting buy-in from the senior leadership level,” says Mike. “Data is very important, but data quality is not necessarily emphasized as a way to quantify the value of your data at any given time.”
Dustin says it’s essential to communicate your definition of data quality to understand if it’s shared across the org. “We know what we know, and then we talk with our stakeholders… [We’re trying to find out] if we need a special metric for a stakeholder’s area of the business, or if they can use mine.”
The key to solving these challenges?
“Have a good conversation with upstream and downstream people in the organization,” recommends Dustin.
Data trust requires context. Communication is key to developing a shared understanding of the data, its quality, and the value its driving. “If you don’t have that data understanding between all the players, then data quality has a fuzzy definition. You can’t do much from there. You have to be on the same page from the start.”
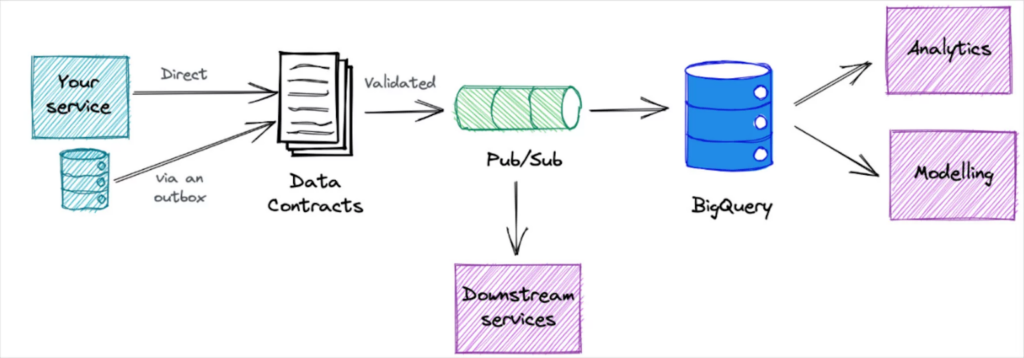
Data contracts are one solution Dustin recommends that can help teams set and maintain standards as they scale.
But whether you leverage data contracts, workflow management processes, or just a clear directive, the key to operationalizing data quality is getting closer to the business—and helping the business get closer to the data.
GenAI is the arena. Data observability is the cost of admission.
The GenAI revolution is underway. But is your data ready?
In a recent Informatica survey of 600 data leaders, 45% said they’ve already implemented some form of GenAI, while 42% of the data leaders surveyed still cited data quality as their number one obstacle.
The key to reliable AI is reliable data. And the key to reliable data is end-to-end data observability.
The time to detect and resolve bad data is before it impacts downstream consumers. And that goes double for data that’s leveraged into AI models. Leveraging a tool like Monte Carlo gives data teams at-a-glance visibility into the health of their data from ingestion right down to consumption, so data teams always know what’s gone bad, who it’s impacting, and how to resolve it.
As Dustin says,“Snowflake monitors the things we know, and Monte Carlo monitors the things we don’t.”
Because building valuable AI is hard work—but managing your data quality shouldn’t be.
To learn more about how Monte Carlo’s data observability can bring high-quality data to your GenAI initiative, talk to our team.
Our promise: we will show you the product.
Read more posts.