Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monitoring for the dbt Semantic Layer and Beyond

Scott O'Leary
Scott O'Leary is a founding member of Monte Carlo's Sales team.

Mei Tao
Product at Monte Carlo
The dbt Semantic Layer is poised to take the spotlight at this year’s Coalesce conference. It’s a solution the data world has been eagerly anticipating as dbt Labs has teased its development since last year’s Coalesce conference.
For those that are unfamiliar, a semantic layer is the component of the modern data stack that defines and locks down the aggregated metrics that are important to business operations. This is important because to work toward shared goals, the business needs to have shared meaning, common definitions, and one source of truth.
While dbt is not the first to develop a semantic layer–Looker and LookML have seen success in this area–its position within the modern data stack makes it uniquely suited to address this challenge.
The semantic layer can (and has) worked when integrated with BI tools, but this doesn’t account for other users like data scientists, other use cases like data products, or even other domains that might have adopted alternative BI tools.
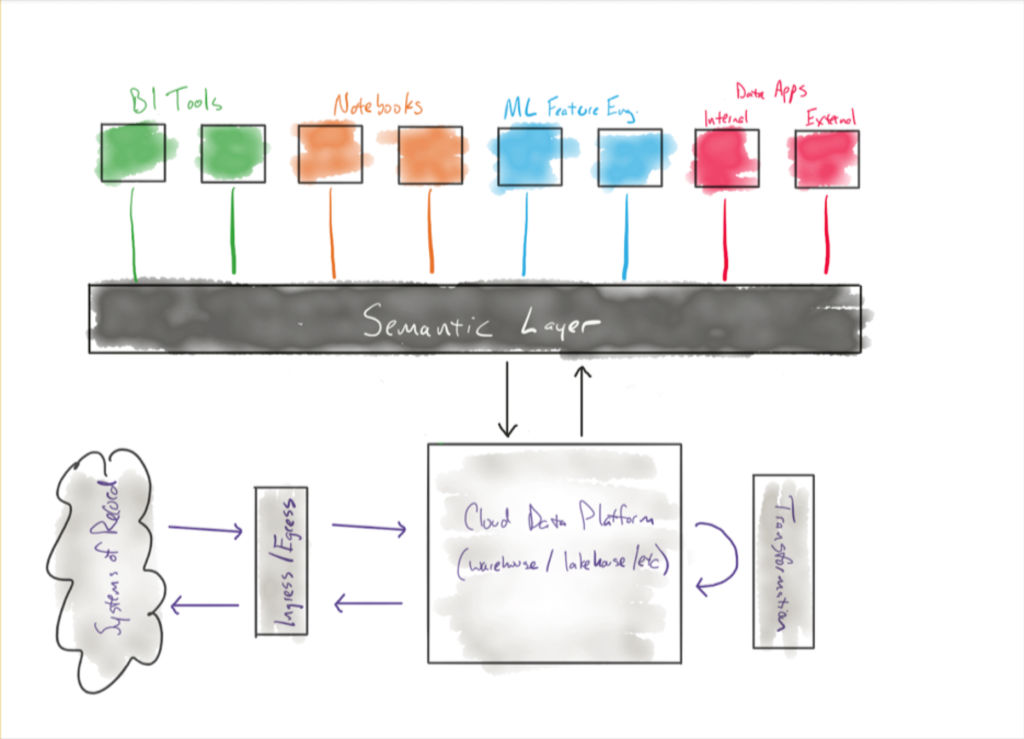
At a high level, rather than have multiple analytics engineers build similar dbt models across the company that are slightly different perspectives on the same metric, the dbt Semantic Layer defines metrics as a single object that can be incorporated into multiple models – and used consistently across BI reports, data products, and other data assets. In short, the dbt Semantic Layer serves as the single source of truth to define your most critical business metrics from which various teams can easily access and build.
We’re excited for the dbt Semantic Layer. via GIPHY
At the core, the metrics layer is trying to address a similar challenge present across all of data–how can we make sure it’s reliable and high-quality. That is something Monte Carlo has helped solve for data teams and our mutual dbt customers like JetBlue, HubSpot, Blend, and hundreds of others.
In this post, we’ll dive deeper into how we can help data teams with:
- Detecting anomalies for the dbt Semantic Layer
- Resolving anomalies for the dbt Semantic Layer
- Preventing anomalies for the dbt Semantic Layer
Specifically, we will highlight how features like monitors as code and our platform’s ability to ingest dbt errors and tests within a single interface, add a level of rigor befitting of this development.
Let’s get to it.
Detecting anomalies for the dbt Semantic Layer
Monte Carlo uses machine learning metadata monitors to automatically detect freshness, volume, or schema anomalies across every production table. Our direct integration with dbt shows each model that is associated with a particular table and also monitors and alerts for model errors as you can see below.

This ensures a baseline level of data quality not just across your most important tables defining metrics in the dbt Semantic Layer, but also the tables feeding those tables. This speeds up time to detection and accelerates root cause analysis (which we will get into in the next section).
Let’s leverage an example from a dbt blog that looks closer at how the metric for revenue might be calculated. This table would likely include dependencies from multiple tables with key fields like credit_card_amount, gift_card_amount, has_coupon_payment, etc. Monitoring the revenue table is good, monitoring all the tables that comprise it (like orders) is better.

With that baseline of coverage established automatically, we can now add a deeper level of coverage on the key table using what we call field health or dimension monitors.
These monitors look for anomalies within the distribution of data itself. Is the value of the field within a normal range? Are there anomalies within the number of NULLS or unique values?

But let’s say a single NULL in something as critical as a revenue table is an issue. Monte Carlo also enables you to create custom rules to augment the dbt tests your team may have already deployed (which you can also surface within the Monte Carlo interface for a consolidated view of all of your data quality incidents).
All of these monitors can be configured within the platform or deployed as monitors as code during the model development process. This is a big deal. The analytics engineer or data engineer can build the model and ship it to production along with a monitors as code YAML config file.
This makes these opt-in and custom monitors scalable, versionable, and deployable within the CI/CD workflow. Putting these two workflows together simplifies change management and helps create cohesion.
Resolving anomalies for the dbt Semantic Layer
Once you’re monitoring your core tables defining metrics in the dbt Semantic Layer, the next step is to quickly resolve any anomalies that may arise in those tables or those upstream of them.
This is where our dbt integration really shines with automated root cause analysis for failed model runs, test failures, query changes that may have contributed to the incident.
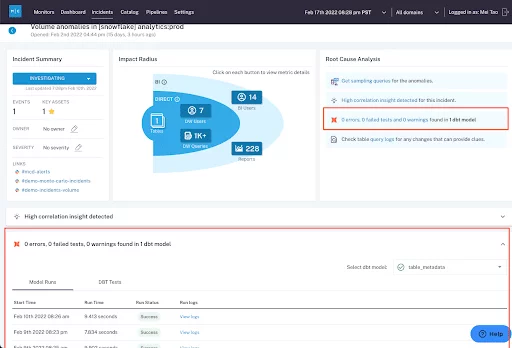
If you can find a query or dbt model was modified around the approximate time an anomaly in the associated table was introduced, it’s a promising sign you’ve found your root cause. This process can be expedited with data monitoring and log analysis across your stack.

End-to-end data lineage at the field level can also help data teams trace incidents at all layers of your data stack to the most upstream table allowing for quicker root cause analysis.
Preventing anomalies for the dbt Semantic Layer
Monte Carlo can also help data teams prevent anomalies from occurring in the dbt Semantic Layer in the first place. One mechanism from doing this is our Data Health Insights feature.
Monte Carlo can help analytical engineers govern and maintain their data platform by surfacing insights on unused tables and deteriorating queries from dbt models. This empowers the team to remove tables that may be defining metrics that have fallen out of favor or and models that are likely to fail.
On the other side of the coin, Monte Carlo’s identification of key tables–generally calculated by the number of read/writes and consumption in the BI layer–can help teams proactively identify possible aggregations that should become a formal metric and part of the semantic layer.
Finally, Monte Carlo imports dbt tags and descriptions on table and field levels allowing developers to manage all the critical metadata–things like ownership, certification levels, and documentation–from a single pane of glass.
dbt and Monte Carlo: Better together
With their upcoming Semantic Layer announcement, dbt is set to move the ball significantly on a foundational piece of the modern data stack.
We will be exhibiting and speaking at Coalesce Booth 305 about many topics including monitoring the semantic layer – be on the lookout for product updates in the not-too-distant future.
Come stop by and talk to us!

Also, we’re thrilled to have dbt founder Tristan Handy keynote at this year’s IMPACT conference. Be sure to register and attend his session.
Finally, we’ll let one of our mutual customers, Kolibri Games, have the last word in regard to the power of Monte Carlo and dbt:
“With over 100 million unique events produced per day across 40 different event types, our games generate an unprecedented amount of data, and in order to trust it, we need to prevent bad data from entering our pipelines and know when incidents arise downstream,” said António Fitas, Head of Data Engineering at Kolibri Games. “Monte Carlo and dbt are the perfect tools to help us achieve the level of trust and reliability as we scale our data platform…”
Interested in learning more about how Monte Carlo can help you improve data quality and maintain a highly reliable semantic layer? Fill out the form below to schedule some time to speak with us!
Our promise: we will show you the product.
Read more posts.