Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 7 Lessons From GoCardless’ Implementation of Data Contracts

Andrew Jones
Andrew Jones is the Data Team Lead at GoCardless, a UK-based FinTech company.
Editor’s Note: We ran into Andrew at our London IMPACT event in early 2022. At the time, he was one of a very few people using the term “data contract.” Not only was he using the term, but his implementation was generating results.
Data contracts have since became one of the most discussed topics in data engineering. For posterity, we have preserved Barr’s forward that examines what was then a very nascent trend, but we have also added an updated data contract FAQ as an addendum. Enjoy!
Forward: A Data Engineering Movement Afoot?
By Barr Moses
GoCardless’s ETL approach focuses on treating data like an API. They codify data needs in a data contract and schemas from consumers up front, and then deliver the data pre-modeled into the data warehouse.
It’s becoming clear a data engineering movement is afoot as we have recently covered other organizations taking a similar approach: Convoy and Vimeo.
You can read more about Convoy’s approach from our blog with their Head of Product, Data Platform, Chad Sanderson, “The modern data warehouse is broken.” We also have an article covering Vimeo’s approach in our case study sourced from former VP Lior Solomon’s interview with the Data Engineering Show podcast.
Is this a (back to the future as Joe Reis would call it) data engineering best practice? Is it an alternative approach fit for a certain breed of organization? (Interestingly these three organizations share a need for near real-time data and have services that produce copious first-party event/transactional data). Or is it a passing fad?
Time will be the judge. But the emergence of this alternative approach reveals a few truths of which data leaders should note:
- Data pipelines are constantly breaking and creating data quality AND usability issues.
- There is a communication chasm between service implementers, data engineers, and data consumers.
- ELT is a double edged sword that needs to be wielded prudently and deliberately.
- There are multiple approaches to solving these issues and data engineers are still very much pioneers exploring the frontier of future best practices.
Data contracts could become a key piece of the data quality puzzle, and much can be learned from Andrew’s experience implementing them at GoCardless, detailed below.
7 Key Learnings From Our Experience Implementing Data Contracts
A perspective from Andrew Jones, GoCardless
One of the core values at GoCardless is to ask why.
After meeting regularly with data science and business intelligence teams and hearing about their data challenges, I began to ask “why are we having data issues arise from service changes made upstream?”
This post will answer that question and how asking it led to the implementation of data contracts at our organization. I will cover some of the technical components I have discussed in a previous article series with a deeper dive into the key learnings.
- Data quality challenges upstream
- Talking to the team
- Our data contract architecture and process
- Key learnings
- Tradeoffs
- The future of data contacts at GoCardless
- Addendum Data Contract FAQ

Data quality challenges upstream
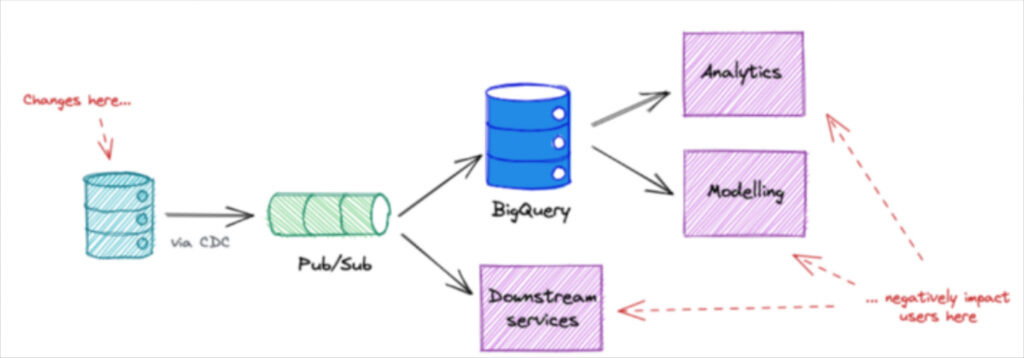
What I found in my swim upstream were well meaning engineers modifying services unaware that something as simple as dropping a field could have major implications on dashboards (or other consumers) downstream.
Part of the challenge was data was an afterthought, but part of the challenge was also that our most critical data was coming directly from our services’ databases via a CDC.
The problem with investing in code and tooling to transform the data after it’s loaded is that when schemas change those efforts either lose value or need to be re-engineered.
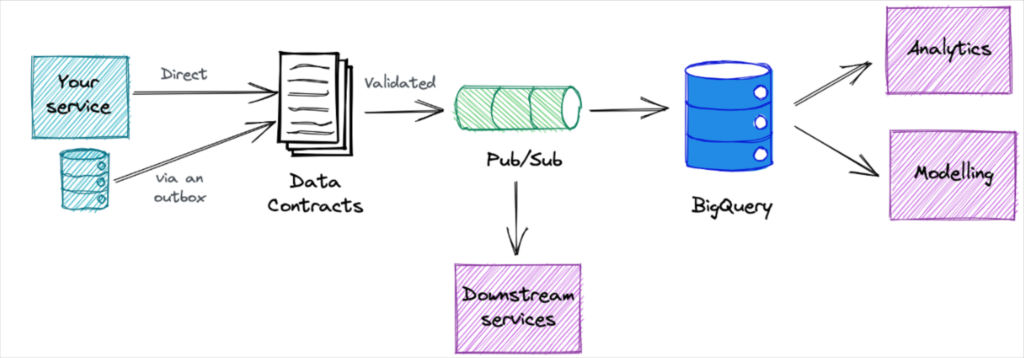
So there were two problems to solve. On the process side, data needed to become a first class citizen during upstream service updates, including proactive downstream communication. On the technology side, we needed a self-service mechanism to provision capacity and empower teams to define how the data should be ingested.
Fortunately, software engineers solved this problem long ago with the concept of APIs. These are essentially contracts with documentation and version control that allow the consumer to rely on the service without fear it will change without warning and negatively impact their efforts.
At GoCardless we believed data contracts could serve this purpose, but as with any major initiative, it was important to first gather requirements from the engineering teams (and maybe sell a bit too).
Talking to the team
We started talking to every engineering team at the company. We would explain what data contracts were, extol their benefits, and solicit feedback on the design.
We got some great, actionable feedback.
For example, most teams didn’t want to use AVRO so we decided to use JSON as the interchange format for the contracts because it’s extensible. The privacy and security team helped us build in privacy by design particularly around data handling and categorizing what entity owned which data asset.
We also found these teams had a wide range of use cases and wanted to make sure the tooling was flexible enough. In fact, what they really wanted was autonomy.
In our previous setup, once data came into the data warehouse from the CDC, a data engineer would own that data and everything that entailed to support the downstream services. When those teams wanted to give a service access to BigQuery or change their data, they would need to go through us.
Not only was that helpful feedback, but that became a key selling point for the data contract model. Once the contract was developed they could select from a range of tooling, not have to conform to our opinions about how the data was structured, and really control their own destiny.
Let’s talk about how it works.
Our data contract architecture and process
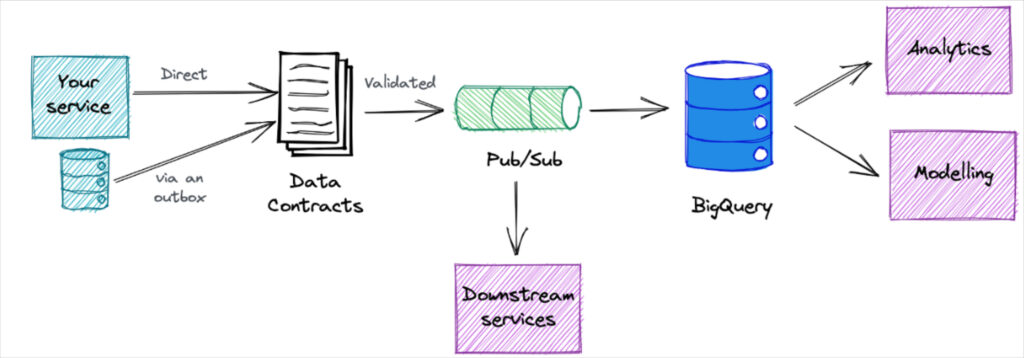
The data contract process is completely self-serve. It starts with the data team using Jsonnet to define their schemas, categorize the data, and choose their service needs. Once the Json file is merged in Github, dedicated BigQuery and PubSub resources are automatically deployed and populated with the requested data via a Kubernetes cluster.
For example, this is an example of one of our data contracts, which has been abridged to only show two fields.

The process is designed to be completely automated and decentralized. This minimizes the dependencies across teams so that if one service needs to increase the workers for a service, it doesn’t impact another teams’ performance.
The Internal Risk division was one of the first teams to utilize the new system. They use data across different features to identify and mitigate risk from potentially fraudulent behavior. Previously they were leveraging data from the production database just because it was there. Now they have a much more scalable environment in BigQuery that they can manage directly.
As of this writing, we are 6 months into our initial implementation and excited by the momentum and progress. Roughly 30 different data contracts have been deployed which are now powering about 60% of asynchronous inter-service communication events.
We have made steady inroads working with traditional data consumers such as analytics and data science teams and plan to help migrate them over to this system as we decommission our CDC pipeline at some point in the next year.
Most importantly, our data quality has started to improve, and we are seeing some great examples of consumers and generators working together to set the data requirements – something that rarely happened before.
Key learnings
So what have we learned?
- Data contracts aren’t modified too much once set: One of the fears of this type of approach is there will be a lot of upfront work to define schemas that will just change anyway. And the beauty of ETL is that data can be quickly rearranged and transformed to fit those new needs whereas ours requires more change management. However, what we have found with our current user base is their needs don’t change frequently. This is an important finding because currently even one schema change would require a new contract and provision a new set of infrastructure creating the choice of going greenfield or migrating over the old environment.
- Make self-service easy: Old habits die hard and it’s human nature to be resistant to change. Even if you are promising better data quality, when it comes to data, especially critical data, people are often (understandably) risk averse. This is one of the reasons we made our self-service process as easy and automated as possible. It removes the bottleneck and provides another incentive–autonomy.
- Introduce data contracts during times of change: This could be counterintuitive as you might suppose the organization can only digest so much change at a time. But our best adoption has come when teams want new data streams versus trying to migrate over services that are already in production. Data contracts are also a great system for decentralized data teams, so if your team is pursuing any type of data meshy initiative, it’s an ideal time to ensure data contracts are a part of it.
- Roadshows help: Being customer obsessed is so important it’s almost a cliche. This is true with internal consumers as well. Getting feedback from other data engineering teams and understanding their use cases was essential to success. Also, buy-in took place the minute they started brainstorming with us.
- Bake in categorization and governance from the start, but get started: Making sure we had the right data ownership and categorization from the start avoided a lot of potentially messy complications down the road. While putting together the initial data contract template with the different categories and types may seem daunting at first, it turned out to be a relatively straightforward task once we had started following our roadshow.
- Interservices are great early adopters and helpful for iteration: Teams with services that need to be powered by other services have been our greatest adopters. They have the greatest need for the data to be reliable, timely and high quality. While progress with analytics and data science consumers has been slower, we’ve built momentum and iterated on the process by focusing on our early adopters.
- Have the right infrastructure in place: Simply put, this was the right time for data contracts at GoCardless. We had concluded an initiative to get all the necessary infrastructure in place and our data centralized in BigQuery. Leveraging an outbox pattern and PubSub have also been important to make sure our service-to-service communications are backed up and decoupled from production databases.
Tradeoffs
No data engineering approach is free of tradeoffs. In pursuing this data contract strategy we made a couple of deliberate decisions including:
- Speed vs sprawl: We are keeping a close eye on how this system is being used, but by prioritizing speed and empowering decentralized teams to provision their own infrastructure there is the possibility of sprawl. We will mitigate this risk as needed, but we view it as the lesser evil compared to the previous state where teams were forced to use frequently evolving production data.
- Commitment vs. change: Self service is easy but the data contract process and the contract itself is designed for the data consumer to put careful consideration into their current and future needs. The process for changing a contract is intentionally heavy to reflect the investment and commitment being made by both parties in maintaining this contract.
- Pushing ownership upstream and across domains: We are eliminating ourselves as a bottleneck and middleman between data generators and data consumers. This approach doesn’t change the core set of events that take place that impact data quality. Implementation services still need to be modified and those modifications still have ramifications downstream. But what has changed is these contracts have moved the onus on service owners to communicate and navigate these challenges and they now know which teams to coordinate with regarding which data assets.
The future of data contracts at GoCardless
Data contracts are a work in progress at GoCardless. It is a technical and cultural change that will require commitment from multiple stakeholders.
I am proud of how the team and organization has responded to the challenge and believe we will ultimately fully migrate to this system by the middle of next year–and as a result will see upstream data incidents plummet.
While we continue to invest in these tools, we are also starting to look more at what we can do to help our consumers discover and make use of the data. Initially this will be through a data catalog, and in future we will consider building on that further to add things like data lineage, SLOs and other data quality measures.
Addendum Data Contract FAQ
By Barr Moses
It’s been less than a year since we published this article and already the data contract discussion has noticeably evolved.
Andrew’s experience at GoCardless and Chad Sanderson’s experience at Convoy, where they lead the first modern data contract implementations, remain the definitive guide. This is the privilege and responsibility of the concept creator whether it’s Bill Imon and the data warehouse, or Zhamak Dehghani and the data mesh.
At the same time, when a concept becomes big enough and important enough, other valid interpretations emerge. In the section below, I’ll mainly reference the concept as originally conceived by Andrew and Chad, but will also point to other experts who have advanced alternative points of view.
It’s my hope that this will both clarify confusion as well as stimulate the discussion necessary to continue evolving our field – and ultimately, help data teams improve data quality at scale.
- What are data contracts?
- Why do we need data contracts?
- Do you need to define data consumer needs prior to creating a data contract?
- What are data contracts important?
- How do you implement data contracts? How do you enforce data contracts?
- Who is responsible for data contracts?
- Can you buy data contract solutions?
- What data contract alternatives exist?
- When should you consider data contracts?
- Can you implement data contracts within data mesh?
- What is the difference between data contract vs data model?
- What is the difference between data contract vs data catalogue?
- What is the difference between data contract vs data observability?
- What is the difference between data contract vs data testing?
- What is the difference between data contract vs SchemaOps?
What are data contracts?
A data contract defines and enforces the schema and meaning of the data being produced by a service so that it can be reliably leveraged and understood by data consumers.
Despite what the name may suggest, data contracts are not the product of hard fought negotiations between data producers (typically software engineers who are responsible for the software or service emitting data) and data consumers (typically data engineers or data scientists tasked with handling and gleaning insights from data).
A data contract is a type of interface that operates in a similar transparent and versionable manner to how an API enables the reliable exchange of information between applications. While most data contract architectures are built for data operations within an organization, they can also be used as part of an external data sharing initiative.
The actual data contract itself is typically written in a templated interactive data language (IDL) such as Apache Avro or JSON. There is also a mechanism for decoupling the data architecture to avoid using production data or change data capture (CDC) events directly.
Why are data contracts important?
The most commonly cited use case for data contracts is to prevent cases where a software engineer updates a service in a way that breaks downstream data pipelines. For example, a code commit that changes how the data is output (the schema) in one micro-service, could break the data pipelines and/or other assets downstream. Having a solid contract in place and enforcing it could help prevent such cases.
Another equally important use case is downstream data quality issues. These arise when the data being brought into the data warehouse isn’t in a format that is usable by data consumers. A data contract that enforces certain formats, constraints and semantic meanings can mitigate such instances.
Do you need to define data consumer needs prior to creating a data contract?
It depends on who you ask. In my opinion, this is the main schism within the data contract philosophy.
Data contracts as originally conceived involve gathering data consumer requirements and then pre-modeling data to those specifications before it landed in the data warehouse. Putting the data consumer first is strongly emphasized as part of the cultural change that needs to accompany any technical changes.
Others have suggested alternative data contract architectures (see below) that are designed to be more reactive and agile. This version of data contracts is less focused on bridging the gap between data producer and data consumers and more focused on creating tests that prevent data produced by unexpected schema changes from landing in production.
In other words, one version envisions a process by which the software engineers or other data producers are aware of what’s required for data reliability and are responsible for change management the same as they are for any other impacts their code may have. The other version envisions a process by which these schema changes still happen, but data teams are able to make quick fixes and ensure that bad data never enters production.
What does a data contract look like?
The data contract by Andrew Jones earlier in this article is one of the best examples I’ve seen, but another good example is from Chad Sanderson.
In this case, Chad suggests spreadsheets as one possibility for holding the data contract…
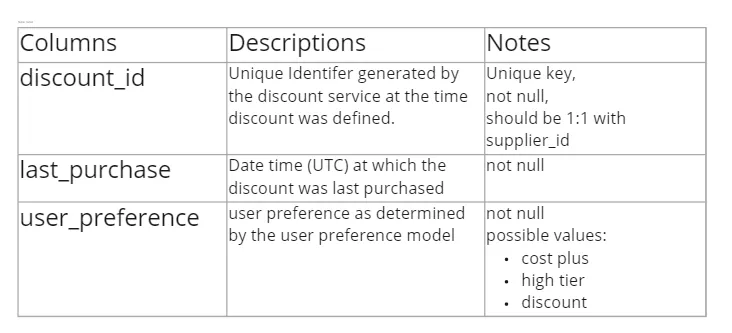
…before it is defined in a service like Protobuf (note these two images are not the same contract):

For another example of a data contract template, check out what PayPal has open sourced on GitHub.
How do you implement data contracts? How do you enforce data contracts?
Here are some different data contract architectures categorized by different schools of thought.
Pre-defined contracts
- Andrew Jones, GoCardless— contract is in Jsonette, merged to Git by the data owner, dedicated BigQuery and PubSub resources are automatically deployed and populated with the requested data via a Kubernetes cluster and custom self-service infrastructure platform called Utopia.
- Chad Sanderson, Convoy– Defined in Protobuf, enforced as part of the service’s code using Docker compose, enforced using Kafka schema registry, Debezium for abstraction/decoupling and fulfillment.
dbt as contract
- Benn Stancil, Mode– Data is written into a staging schema from services, dbt test validates schema and transfers to raw environment, dbt transforms raw data and transforms back to staging schema, validated with final dbt test before it enters production.
Git handshakes and pull requests
- Piethein Strengholt, Microsoft– Data contracts are stored in a metastore, leverage Git as source control, custom built “data product sidecar” for access control/security.
- Gleb Mezhanskiy, Datafold– Use pull request process within some mechanism (perhaps Git) that validates if the schema changes, if the data changes, and impact on downstream assets.
- Anath Packkildurai, creator of Schemata (describing Slack’s architecture circa 2016) – Developers make changes to Slog, a thrift format for logging client and server logs, which triggers a Github pull request for the data team. The data team then verifies and merges the schema change.
Who is responsible for data contracts?
The data producer must have some responsibility for data contracts and data quality.
That being said, data engineers will always have a responsibility for the quality of the data they produce and will continue to play a crucial role in maintaining data contracts given the nature of their ownership over the data pipeline. In fact, if you find data contracts in the wild, chances are it was implemented and is currently enforced by a data engineer.
Can you buy data contract solutions?
Not yet, although I predict it’s only a matter of time as there are already multiple open-source data contract projects.
Remember, data contracts are just one component of your data reliability stack along with tests, circuit breakers, and data observability.
What data contract alternatives exist?
Not every pipeline nor every company needs to implement data contracts to ward off issues with unexpected schema changes. Other options include:
- Regular meetings with the software engineering team to review past and upcoming service updates
- Deploying a DataOps team to keep data operations running smoothly, including being responsible for handling schema changes and other change management related issues.
- More informal processes using decoupled dbt models or Git pull requests.
- Leveraging data observability and ensuring all members of the software engineering and data teams have full visibility into data lineage.
More details here.
When should you consider implementing data contracts?
You should consider implementing data contracts when you have:
- Production pipelines, data products, or other key data assets in which data reliability is paramount.
- You have the capacity/talent to gather requirements, develop data models, and build a solution.
- You are experiencing repeated data incidents related to unexpected schema changes as well as overly brittle SQL queries or transformation models.
- You have already deployed a data observability and data monitoring solution to quickly detect, resolve, and prevent data quality issues at scale.
Can you implement a data contract within a data mesh?
Yes, data contracts can work with both centralized and decentralized data systems.
What is the difference between a data contract vs data model?
A data contract defines and enforces the schema and meaning of a dataset. A dbt model makes data transformation more reliable and modular. Since dbt models can include tests, some pundits have advocated for having dbt as your data contract architecture.
Data modeling can also refer to the process of how data is organized within the data warehouse or other data repository using Kimball, Inmon, Data Vault or other methodologies. Many data contract advocates emphasize the need for organizations to have robust data modeling practices to make data warehouses usable and easy to navigate for consumers.
What is the difference between a data contract vs data catalog?
A data contract defines and enforces schema and semantic meaning in a prescriptive way to prevent changes that break downstream data assets whereas data catalogs define schemas and semantics in a descriptive manner in order to build shared understanding.
What is the difference between a data contract vs data observability?
A data contract seeks to improve data quality by operationalizing and scaling change management across a pipeline, whereas data observability seeks to improve data quality by leveraging machine learning to reduce the time to detection and resolution of data downtime. Both are important solutions for improving data reliability.
Data contracts seek to prevent data incidents caused by unexpected schema changes or overly brittle SQL code before these issues impact production. However, for many reasons, even the best data contract architecture cannot prevent all data incidents. This is one reason why data observability’s real-time data monitoring and anomaly resolution capabilities are so critical for reducing data downtime.
Data observability solutions can also highlight the full picture of an organization’s data health (and thus also help prevent incidents) with capabilities such as data lineage, reliability dashboards, health insights, key asset tables, and more.
What is the difference between a data contract vs data testing?
If you squint, a data contract could be described as a very sophisticated set of programmatic data tests specifically focused on schemas. However, this sells data contracts short as their implementation is not quite as manual as writing SQL tests. Moreover, they have the added benefit of helping define important data processes.
What is the difference between a data contract vs SchemaOps?
They are virtually identical concepts that deal with the same issue (unexpected schema changes). However, the original conception of data contracts emphasizes defining data consumer needs upfront and SchemaOps as coined by Anath Packkildurai emphasizes a more reactive, agile approach with decentralized data modeling.
If you feel that GoCardless appeals to you and that you would like to find out more about life at GoCardless you can find their posts on Twitter, Instagram and LinkedIn. Are you interested in joining GoCardless? See the jobs board here.
Interested in learning more about data quality? Book a time to speak with Monte Carlo in the form below.
Our promise: we will show you the product.
Read more posts.