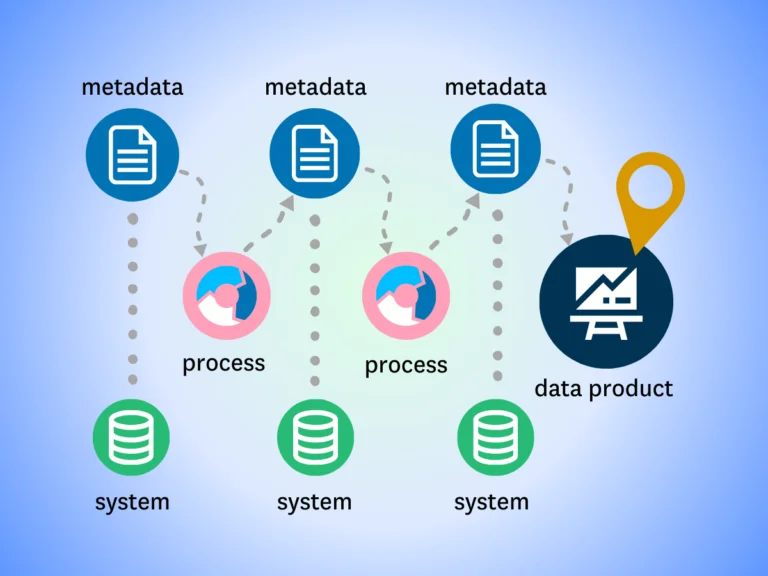
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Is Prompt Engineering Overhyped? No—But Learn These 3 GenAI Skills Too


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.

Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Prompt engineering is the new black. Or so some say.
As GenAI has zoomed onto center stage in the daily data discourse, prompt engineering has been quietly along for the ride.
Today the enterprise landscape is littered with prompt engineering guides and bootcamps, career opportunities and full-time salaries, all of which are prompting (see what I did there?) discussions around the impact—and longevity—of this allegedly necessary skill.

So, here’s the big question: is prompt engineering really that important? Or is it all just hype for the clicks?
Here’s the short answer: no, prompt engineering isn’t all hype. And as we move into our undoubtedly AI-laden future, prompt engineering will be a necessary skill for every data engineer to develop.
But, unlike the click-bait influencers might suggest, prompt engineering isn’t going to be your super power either.
In this article, we’ll look at prompt engineering, what it is, and why it’s valuable—as well as a few other genAI skills that should be at the top of your list.
Table of Contents
What is prompt engineering?
Prompt engineering is a strategic way to communicate and interact with an LLM. It encapsulates the design, refinement, and optimization of prompts and the underlying data structures of generative AI models.
There are several types of prompt engineering, including priming, zero-shot, few-shot prompting, chain of thought prompting, and knowledge generation. Let’s define a few:
- Priming: As the name suggests, priming involves interacting with an LLM in a way that prepares it for the prompt and steers its comprehension toward a specific context. This is typically done through a variety of questions, statements, or directives.
- Zero-shot prompting: This means an AI model is capable of understanding and executing a prompt or task without having seen any explicit examples of what’s being asked. It’s a one-and-done Q&A (but be sure to check that its answer is what you’re looking for!).
- Few-shot prompting: 1-shot, 3-shot, 5-shot prompting, etc entails providing an LLM with a few input-output example pairs to generate the outputs you want.
- Chain of thought prompting: A more advanced prompt engineering technique, this kind of prompting involves breaking down the problem into smaller steps and demonstrating those steps to the model to help demonstrate how to work it out.
- Knowledge generation: This type of prompting requires an API or external integration to ensure the LLM has access to the correct knowledge needed for the requested output.
Prompt engineering is an important skill for data engineers because it allows them to develop a rubric or recipe as a best practice for getting the best answers out of a generative AI model. This is especially important for business stakeholders or other non-technical users who may interface with the AI.
Why is prompt engineering important?
One of the most important skills when it comes to integrating and leveraging GenAI is learning how to speak AI. That’s where prompt engineering comes in.
For data engineers, prompt engineering extends beyond formulating queries. It involves a deep understanding of the model’s architecture and capabilities, the nuances of language, and the specific requirements of the task at hand. The goal is to construct prompts that efficiently leverage the AI’s understanding and generation capabilities to produce desired results, whether that’s answering a complex query, generating insightful analyses, or creating content that aligns with certain criteria.
You also may need to install guardrails to prevent your end users’ prompts from abusing your AI applications — such as your chatbot happily selling brand new cars for a dollar.
Mastering prompt engineering usually involves a lot of experimentation, staying on top of the latest AI models and best practices, and incorporating feedback loops into your approach. By honing your prompt engineering skills, you can help your organization develop GenAI applications that deliver meaningful value and positive experiences to your end users.
Why prompt engineering isn’t all that and a bag of SQL queries
Just because prompt engineering is a part of the lexicon doesn’t mean it’s been welcomed with the open arms of some other data engineering skills. In fact, prompt engineering has caused some serious contention.
Why is prompt engineering so divisive?
While prompt engineering is undoubtedly an important skill to develop, focusing on prompt engineering at the expense of other value-added experiences is a recipe for redundancy if I’ve ever seen one.
At the end of the day, prompt engineering isn’t what’s going to make your data team—or your data products—more valuable to the business. Understanding the business needs and solving real problems will.
Sure, prompt engineering can help teams get the most out of their internal and external AI products—and the right prompt skills will certainly make it easier to realize the efficiencies of adopting genAI in an enterprise context—but the real challenge isn’t controlling what comes out of an AI model but what goes into it.
But like brute strength in a cage fight, prompt engineering isn’t everything.
Here are three areas to focus on before prompt engineering to provide even more value to your stakeholders.
Understand vector databases
The infrastructure and technical roadmap for AI tooling is being developed as we speak, with new startups emerging every day to tackle various problems. But even with all that constant change, one thing is for sure: the underlying data store of this new architecture will be vector databases.
A vector database is a type of database that stores data as high-dimensional “vectors” or a string of numbers which captures the semantic meaning of an object. In a vector database, similar objects will appear close together, enabling models to locate objects by similarity to one another in a process known as “vector search.” Unlike other databases, vector databases are AI-native, optimizing search for generative AI applications first and foremost—hence their increased popularity in the AI-boom.
A vector database enables a GenAI system to retrieve similar objects based on those vector embeddings, which means the LLM can leverage these connections to find the best output. A vector database also assists a GenAI model with:
- Semantic search
- External memory
- Rapid prototyping
- Integration with GenAI tech stack
- Scalability
- Data protection and compliance
A vector database is foundational to prompt engineering because it sets up the source to be queried. With a vector database, semantic layer, and RAG architecture underpinning your GenAI model, your organization is set up to not only prompt the LLM more effectively, but drive more business value as well.
For example, when a user prompts a RAG application, the app converts the question into an embedding using an embedding model. It then performs a semantic search against the vector database to find the most relevant embeddings, and the top results are then passed to the LLM. The model generates a response based on these results, providing the user with a detailed answer based on the data provided to the knowledge base.
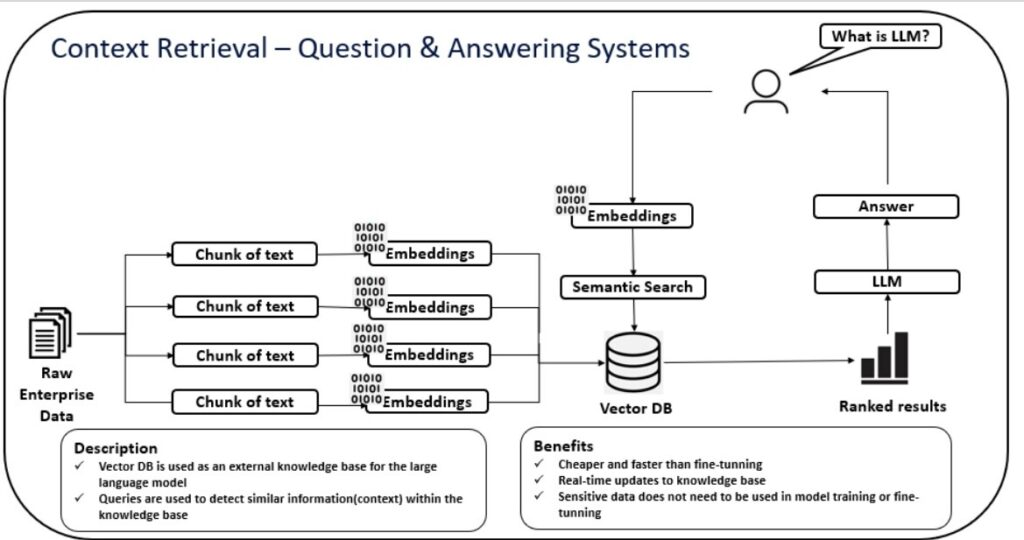
One important note here: it’s crucial to ensure the data leveraged in this infrastructure is reliable.
Monte Carlo’s recent release of data observability for vector databases means teams can confidently build AI applications while knowing their pipelines are being monitored for anomalies of any sort.
If prompt engineering is the equivalent of giving a man a fish, then understanding vector databases and how to make them more reliable is like giving that man a fishing boat, a crew, and a lifetime fishing license at the same time.
Create AI differentiation with RAG
Prompt engineering is a step in the right direction. But a baby step. As a data leader, you’re going to need a lot more to drive business value with AI.
Leveraging RAG architecture into your AI models is one such solution.
RAG combines information retrieval with a text generator model, so it has access to your database while trying to answer a question from the user.
This means that RAG architecture can enable AI models to provide output that’s inclusive of proprietary data.
That added business context ensures that any outputs—whether internal or external—will provide information that’s not just accurate but differentiated. And in business-specific differentiation, there is value.
Pair those differentiated resources with the right prompt structure, and you’ve got yourself a darned valuable output.
Of course, the use of RAG necessitates the right data to power it. Low quality inputs equal low-quality outputs. So, as you develop your RAG architecture, be thinking about how you’ll ensure the quality of your context data just as much as the quality of the data in your other data products.
RAG is still fairly new, and teams are still wrapping their heads around the governance and compliance requirements. But, as RAG grows in popularity, prompt engineering will become more and more useful.
Find and solve real business problems
Whether you’re honing your prompt engineering skills to develop better AI applications for your data consumers or just trying to squeeze a little more out of AI’s efficiencies for your own team, prompt engineering is definitely a value add for modern data teams.
But like we’ve demonstrated above, prompt engineering isn’t the end-all-be-all of AI prowess for the data engineer. Data scientists and practitioners certainly stand to benefit from brushing up their prompt chops—but data engineers are called to something greater.
As the shepherds of an organization’s data assets, data engineers are at the heart of an AI’s power and performance. They aren’t simply users of AI—they’re the cultivators of it. So, while prompt engineering offers some return for data engineers, it’s not the kind of return that makes data engineers indispensable to their organizations.
Even the most finely tuned models won’t make an impact if they aren’t solving a meaningful business problem. So, in all your prompt engineering existentialism, it’s critically important that you don’t neglect the most fundamental data engineering skill: understanding business knowledge and stakeholder engagement.
As a data engineer, you can’t build or leverage AI until you understand what problems your stakeholders are facing and how GenAI can be used to solve them. Just saying “AI is a priority” is neither a sufficient direction nor an effective use of time. Instead, you should be asking:
- Why is AI a priority?
- Is AI a priority to make your team more efficient?
- Is AI a priority to deliver new planes of value for your consumers?
- What is our AI doing exactly?
GenAI can handle a lot of data engineering tasks, including writing passable Python scripts, assisting with data integrations, and performing basic ETL processes. But what it can’t do is replicate human insight, collaboration, and creative problem solving.
As a data leader in the AI age, the skills you need to cultivate aren’t simply how to use an AI. The skills you need to cultivate are the skills that get AI closer to the business.
High-quality data always lives up to the hype
No matter how you’re using GenAI today—or not—helping your organization realize more value from its data will always be a value add.
Whether we’re talking about dashboards or LLMs, garbage in means garbage out. If you can’t trust what’s going to your AI, there’s no way you can trust what’s coming back out of it.
Data observability helps data teams protect the integrity of their data products by identifying data quality issues in real-time and arming data quality owners with the resources to root cause and resolve issues faster than ever—eliminating the costly impact of data quality incidents and fostering data trust in the process.
Whether GenAI dreams are on the horizon or you’re focusing on the fundamentals, becoming a data quality expert with the solutions to back it up is one resume-builder that will never go out of style.
Want to learn more about data observability for GenAI? Give us a call.
Our promise: we will show you the product.
Read more posts.