 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
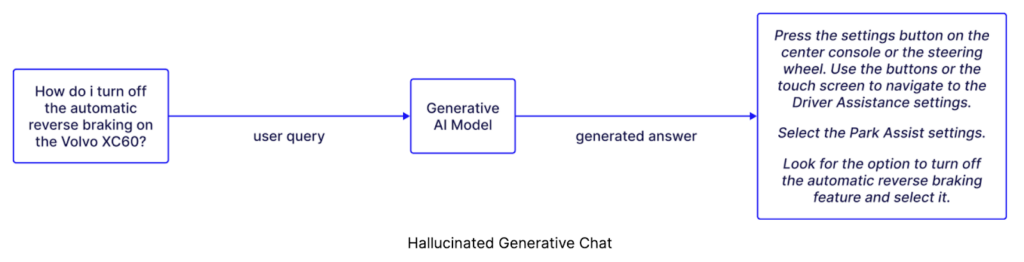
The ULTIMATE Guide To Data Lineage Will GenAI Replace Data Engineers? No — And Here’s Why.


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
These days, keeping up with the latest advancements in GenAI is harder than saying “multimodal model.” It seems like every week some shiny new solution launches with the lofty promise of transforming our lives, our work, and the way we feed our dogs.
Data engineering is no exception.
Already in the wee months of 2024, GenAI is beginning to upend the way data teams think about ingesting, transforming, and surfacing data to consumers. Tasks that were once fundamental to data engineering are now being accomplished by AI — usually faster, and sometimes with a higher degree of accuracy.
As familiar workflows evolve, it naturally begs a question: will GenAI replace data engineers?
While I can’t in good conscience say ‘not in a million years’ (I’ve seen enough sci-fi movies to know better), I can say with a pretty high degree of confidence “I don’t think so.”
At least, not anytime soon.
Here’s why.
Table of Contents
The current state of GenAI for data engineering
First, let’s start off our existential adventure by looking at the current state of GenAI in data engineering — from what’s already changed to what’s likely to change in the coming months.
So, what’s the biggest impact of GenAI on data engineers in Q1 of 2024?
Pressure.
Our own survey data shows that half of data leaders are feeling significant pressure from CEOs to invest in GenAI initiatives at the expense of higher-returning investments.
For data engineering teams, that can mean kicking off a race to reconfigure infrastructure, adopt new tools, figure out the nuances of retrieval-augmented generation (RAG) and fine-tuning LLMs, or navigate the endless stream of privacy, security, and ethical considerations that color the AI conversation.
But it’s not all philosophy. On a more practical level, GenAI is tangibly influencing the ways data engineers get work done as well. Right now, that includes:
- Code assistance: Tools like GitHub Copilot are capable of generating code in languages like Python and SQL — making it faster and easier for data engineers to build, test, maintain, and optimize pipelines.
- Data augmentation: Data scientists and engineers can use GenAI to create synthetic data points that mimic real-world examples in a training set — or intentionally introduces variations to make training sets more diverse. Teams can also use GenAI to anonymize data, improving privacy and security.
- Data discovery: Some data leaders we’ve spoken with are already integrating GenAI into their data catalogs or discovery tools as well to populate metadata, answer complex questions, and improve visibility, which in turn can help data consumers and business stakeholders use GenAI to get answers to their questions or build new dashboards without overburdening data teams with ad hoc requests.
And by and large, these developments are good news for data engineers! Less time spent on routine work means more time to spend driving business value.
And yet, as we see automation overlap with more of the routine workflows that characterize a data engineer’s day-to-day, it’s normal to feel a little… uncomfortable.
When is GenAI going to stop? Is it really going to eat the world? Are my pipelines and infrastructure next?!
Well, the answer to those questions are, “probably never, but probably not.” Let me explain.
Why GenAI won’t replace data engineers
To understand why GenAI can’t replace data engineers—or any truly strategic role for that matter—we need to get philosophical for a moment. Now, if that sort of tête-à-tête makes you uncomfortable, it’s okay to click away. There’s no shame in it.
You’re still here?
Okay, let’s get Socratic.

Artificial “intelligence” is limited
First thing’s first—let’s remember what GenAI stands for: “generative artificial intelligence”. Now, the generative and artificial parts are both fairly apt descriptors. And if it stopped there, I’m not sure we’d even be having this conversation. But it’s the “intelligence” part that’s tripping people up these days.
You see, the ability to mimic natural language or produce a few lines of accurate code doesn’t make something “intelligent.” It doesn’t even make someone intelligent. A little more helpful perhaps, but not intelligent in the true sense of that word.
Intelligence goes beyond spitting out a response to a carefully phrased question. Intelligence is information and interpretation. It’s creativity. But no matter how much data you pump into an AI model, at the end of the day, it’s still ostensibly a regurgitation machine (albeit a very sophisticated regurgitation machine).
AI isn’t capable of the abstract thought that defines a data engineer’s intelligence, because it’s not capable of any thoughts at all. AI does what it’s told to do. But you need to be able to do more. A lot more.
AI lacks business understanding
Understanding the business problems and use cases of data is at the heart of data engineering. You need to talk with your business users, listen to their problems, extract and interpret what they actually need, and then design a data product that delivers meaningful value based on what they meant—not necessarily what they said.
Sure, AI can give you a head start once you figure all of that out. But don’t give the computer credit for automating a process or building a pipeline based on your deep research. You’re the one who had to sit in that meeting when you could have been playing Baldur’s Gate. Don’t diminish your sacrifice.
AI can’t interpret and apply answers in context
Right now, AI is programmed to deliver specific, useful outputs. But it still requires a data team to dictate the solution, based on an enormous amount of context: Who uses the code? Who verifies it’s fit for a given use case? Who will understand how it’s going to impact the rest of the platform and the pipeline architecture?
Coding is helpful. But the real work of data engineers involves a high degree of complex, abstract thought. This work — the reasoning, problem-solving, understanding how pieces fit together, and identifying how to drive business value through use cases — is where creation happens. And GenAI isn’t going to be capable of that kind of creativity anytime soon.
AI fundamentally relies on data engineering
On a very basic level, AI requires data engineers to build and maintain its own applications. Just as data engineers own the building and maintenance of the infrastructure underlying the data stack, they’re becoming increasingly responsible for how generative AI is layered into the enterprise. All the high-level data engineering skills we just described — abstract thinking, business understanding, contextual creation — are used to build and maintain AI infrastructure as well.
And even with the most sophisticated AI, sometimes the data is just wrong. Things break. And unlike a human—who’s capable of acknowledging a mistake and correcting it—I can’t imagine an AI doing much self-reflecting in the near-term.
So, when things go wrong, someone needs to be there babysitting the AI to catch it. A “human-in-the-loop” if you will.
And what’s powering all that AI? If you’re doing it right, mountains of your own first-party data. Sure an AI can solve some pretty menial problems—it can even give you a good starting point for some more complex ones. But it can’t do ANY of that until someone pumps that pipeline full of the right data, at the right time, and with the right level of quality.

In other words, despite what the movies tell us, AI isn’t going to build itself. It isn’t going to maintain itself. And it sure as data sharing isn’t gonna start replicating itself. (We still need the VCs for that.)
What GenAI will do (probably)
Few data leaders doubt that GenAI has a big role to play in data engineering — and most agree GenAI has enormous potential to make teams more efficient.
“The ability of LLMs to process unstructured data is going to change a lot of the foundational table stakes that make up the core of engineering,” John Steinmetz, prolific blogger and former VP of data at healthcare staffing platform shiftkey, told us recently. “Just like at first everyone had to code in a language, then everyone had to know how to incorporate packages from those languages — now we’re moving into, ‘How do you incorporate AI that will write the code for you?’”
Historically, routine manual tasks have taken up a lot of the data engineers’ time — think debugging code or extracting specific datasets from a large database. With its ability to near-instantaneously analyze vast datasets and write basic code, GenAI can be used to automate exactly these kinds of time-consuming tasks.
Tasks like:
Assisting with data integration: GenAI can automatically map fields between data sources, suggest integration points, and write code to perform integration tasks.
Automating QA: GenAI can analyze, detect, and surface basic errors in data and code across pipelines. When errors are simple, GenAI can debug code automatically, or alert data engineers when more complex issues arise.
Performing basic ETL processes: Data teams can use GenAI to automate transformations, such as extracting information from unstructured datasets and applying the structure required for integration into a new system.
With GenAI doing a lot of this monotonous work, data engineers will be freed up to focus on more strategic, value-additive work.
“It’s going to create a whole new kind of class system of engineering versus what everyone looked to the data scientists for in the last five to ten years,” says John. “Now, it’s going to be about leveling up to building the actual implementation of the unstructured data.”
How to avoid being replaced by a robot
There’s one big caveat here. As a data engineer, if all you can do is perform basic tasks like the ones we’ve just described, you probably should be a little concerned.
The question we all need to ask—whether we’re data engineers, or analysts, or CTOs or CDOs—is, “are we adding new value?”
If the answer is no, it might be time to level up.
Here are a few steps you can take today to make sure you’re delivering value that can’t be automated away.
- Get closer to the business: If AI’s limitation is a lack of business understanding, then you’ll want to improve yours. Build stakeholder relationships and understand exactly how and why data is used — or not — within your organization. The more you know about your stakeholders and their priorities, the better equipped you’ll be to deliver data products, processes, and infrastructure that meet those needs.
- Measure and communicate your team’s ROI: As a group that’s historically served the rest of the organization, data teams risk being perceived as a cost center rather than a revenue-driver. Particularly as more routine tasks start to be automated by AI, leaders need to get comfortable measuring and communicating the big-picture value their teams deliver. That’s no small feat, but models like this data ROI pyramid offer a good shove in the right direction.
- Prioritize data quality: AI is a data product—plain and simple. And like any data product, AI needs quality data to deliver value. Which means data engineers need to get really good at identifying and validating data for those models. In the current moment, that includes implementing RAG correctly and deploying data observability to ensure your data is accurate, reliable, and fit for your differentiated AI use case.
Ultimately, talented data engineers only stand to benefit from GenAI. Greater efficiencies, less manual work, and more opportunities to drive value from data. Three wins in a row.
Call me an optimist, but if I was placing bets, I would say the AI-powered future is bright for data engineering.
Our promise: we will show you the product.
Read more posts.





