Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Experts Share the 5 Pillars Transforming Data & AI in 2024


Sara Gates
Sara is a content strategist and writer at Monte Carlo.
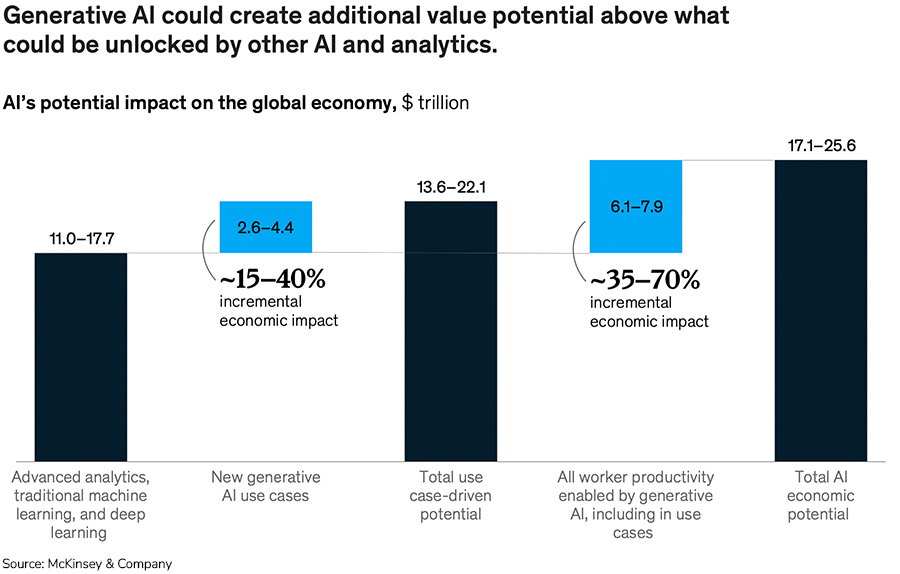
Predicting the future of data and AI in 2024 is not for the faint of heart. New and improved models are constantly emerging. Shiny new technologies promise pie-in-the-sky outcomes. And when will production-ready models really emerge out of all this generative AI talk?
In a recent webinar, we assembled three of the industry’s boldest thinkers to make a few predictions about what lies just around the corner: Zhamak Dehghani, founder of the data mesh and founder/CEO of Nextdata; Maxime Beauchemin, creator of Apache Airflow and Superset, and founder/CEO of Preset; and John Steinmetz, prolific blogger and former VP of data at shiftkey.
Read on to hear their predictions for the 5 pillars the industry will be built on in 2024, and their recommendations for how data teams can maximize AI’s current capabilities in the short-term — while laying the groundwork for long-term transformation.
Table of Contents
Prediction 1: AI will transform data science and engineering. Those who don’t embrace it will be left behind.
With the right prompt (this is key!), Gen AI can whip up serviceable code in moments — making it much faster to build and test data pipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. But what does that mean for the roles of data engineers and data scientists going forward?
According to Max, data professionals need to harness AI and use it, or risk being left behind.
“If you don’t pay for OpenAI and use ChatGPT as a first reflex for everything you do everyday, you’re probably not in a good place right now,” says Max. “If you don’t use Copilot as a programmer, if you’re not crafting a complex prompt of all the things you know and the things you want to see if AI can help you with in a particular workflow, you’re probably missing out.”
John agrees. “The ability of LLMs to process unstructured data is going to change a lot of the foundational table stakes that make up the core of engineering,” he says. “Just like at first everyone had to code in a language, then everyone had to know how to incorporate packages from those languages — now we’re moving into, ‘How do you incorporate AI that will write the code for you?’”
According to Zhamak, the recent advancements in AI are just another step in a long evolution. As we zoom back out in time, she says, “Machines were dumb and humans were smart, and we were compensating for the dumb machines. At the beginning, we had to create this perfectly normalized, multi-dimensional warehouse of facts so the dumb machine can do an optimized search and operations. As the machine became smarter with the next generation of data access, we flattened everything to features and columns. And now, as the machine becomes smarter and smarter, perhaps the effort that humans have to make to compensate for them becomes smaller and smaller.”
This means that data scientists and engineers will be able to spend less time on painstakingly preparing datasets for analytics or writing complex code. Within the next year or so, John says, most of the practical use cases for gen AI in data will be centered around productivity. “They’re not going to change what people do — they’re just going to change how people do it, and they’re going to make you more efficient and effective. Hopefully, that will free up time for people to learn the next wave of technologies and implementations.”
As LLMs and new models learn better, more efficient ways of working with data, says John, “It’s going to create a whole new kind of class system of engineering versus what everyone looked to the data scientists for in the last five to ten years. Now, it’s going to be about leveling up to building the actual implementation of the unstructured data.”
Prediction 2: When it comes to asking the right questions, RAG is the answer
As organizations rush to build enterprise-ready AI applications, they encounter two possible paths at the end of the LLM development process: retrieval augmented generation (RAG) and fine-tuning. RAG involves integrating a real-time database into the LLM’s response generation process, while fine-tuning trains models on targeted datasets to improve domain-specific responses.
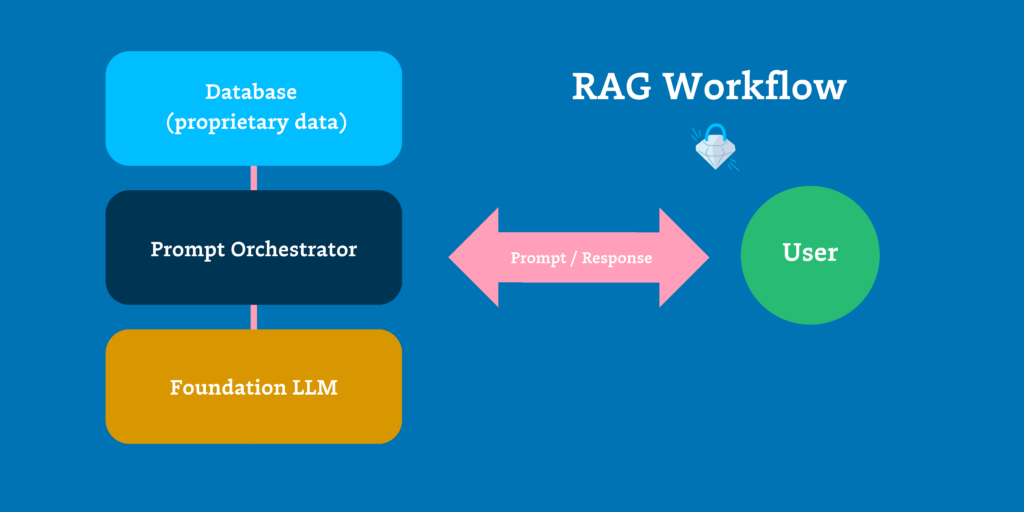
For Max and his team at Preset, RAG has proven to be the right approach. Once ChatGPT launched, they quickly started exploring how to use OpenAI’s API to bring AI inside their BI tools, such as enabling their customers to use plain-language text-to-SQL queries. But given the limits of ChatGPT’s context window, it wasn’t possible to provide the AI with all the necessary information about their datasets — like their tables, naming conventions, column names, and data types. And when they attempted fine-tuning models and custom training, they found the infrastructure wasn’t quite there yet — especially when needing to segment that for each one of their customers.
“I can’t wait to have infrastructure to be able to custom train or fine-tune with your own private information from your organization, your GitHub, your Wiki, your dbt project, your Airflow dags, your database schema,” says Max. “But we’ve talked to a bunch of other founders and people working around this problem, and it became clear to me that custom training and fine tuning is really difficult in this era.”
Given that Max and his team couldn’t take a customer’s entire database, or even just the metadata, and fit it in the context window, “We realized we needed to be really smart about RAG, which is retrieving the right information to generate the right SQL. For now, it’s all about retrieving the right information for the right questions,” he says. “That implies working with new patterns like vector databases.”
Prediction 3: Inconsistent data definitions will be a challenge for RAG — but one single definition may not rule them all
Our panelists agree that one of the biggest challenges around implementing many AI applications, such as natural language queries of company data, is the lack of consistent, consolidated definitions of metrics across the organization.
“Almost every business I walk into, you can talk to the marketing team and the sales team and they have different definitions of things with the same name,” John says. “I think we’re a little bit away from being able to build a model that can actually learn your business — it’s going to take a while before it can understand through other means what you mean when you say ‘churn’ or ‘total lifetime value’ and things like that.”
Max agrees. “It’s hard with RAG. If your definition of churn is buried somewhere in a Notion doc, how do you retrieve that at the moment when people ask a prompt to the AI? And put that in context, and know if it’s stale or up-to-date? The challenge in this phase is to figure out how to ask the right question with AI with the right private context.”
For her part, Zhamak doesn’t see this issue going away anytime soon. “This is a really hard problem,” she says. “I think this ideal we had in terms of unifying language across organizations will always remain a blocker because we try to put a straightjacket of constancy around this chaotic world that people move through at different speeds in their local context.”
Moving forward, our panelists agree that the solution is likely going to involve allowing teams to use their own definitions — but enabling translations across the organization.
As the creator of the decentralized data mesh architecture, Zhamak’s recommendation is to think differently and embrace the diversity of how data operates within different domains in the organization. “Look at the local definitions and local meanings, but have connectivity and interoperability between those local definitions as opposed to a single definition to rule them all. Create the links between them that this concept is the same as that concept — but allow that diversity of operation and local influence in the domain language.”
“It’s a virtuous thing to say ‘We all need to agree on everything so we can speak the same language’,” says Max. “It’s also kind of impossible because people think about the data in different ways. The trade-off for seeking consensus comes at the cost of speed. Maybe it’s OK for the VP of marketing to disagree with the VP of something else on how to compute their NRR, so we can move forward. But I like the idea of speaking different languages in different areas of the business, but we’re able to translate and communicate and move fast on both sides.”
Prediction 4: Data and AI leaders need to focus on building trust
Just as data teams have long needed (and often struggled) to build a culture of data trust, the same will be true for AI leaders in their organizations.
“People come from a place where they mistrust AI for good reason,” says Max. “They think it’s going to steal their jobs — but it doesn’t know everything about their business. ‘It knows about Wikipedia and the internet, but it doesn’t know anything about my job and what I do every day.’ The moment we saw ChatGPT, everyone tried to break it and prove it wrong.”
While this may mean AI leaders face an uphill battle, our panelists have a few strategies in mind to build trust faster: start small and provide visibility.
John advises data teams to introduce AI capabilities gradually, rather than with grandeur. “In data, we try things and they fail — that’s a constant we all deal with,” he says. “But I’ve seen people try to do too much too quickly with the outside business, and it typically breaks everything down. Start small and automate the things they already do, or repeat reports that they do manually. Don’t go and build something new that is all over the place — then you have to backtrack and evaluate what’s working and isn’t working.”
Trust in AI will grow, says Max, as people encounter it in the workflows and patterns they use every day. For example, “Maybe I spend a lot of time in Apache Superset doing data visualization and dashboarding, and if AI is helping me in that context within the tool that I use, it can show me what it’s doing,” he says. “It can show me how it built that chart, which dataset it used, and show me the metadata.”
Embedding conversational AI capabilities into business intelligence products is an example of a good starting point. “Business users will start to trust AI more if they’re asking specific questions about what they know,” says John.
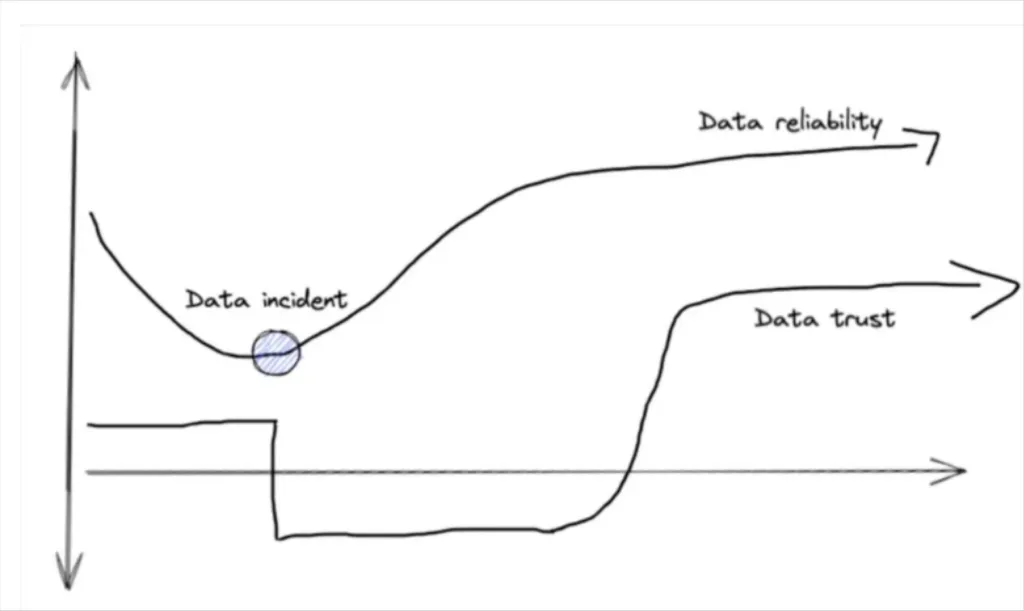
Our panelists also agree there’s an inextricable link between trust in AI and trust in the data itself. In her pioneering work on the data mesh, Zhamak came across a fundamental definition of trust from Oxford fellow Rachel Botsman: the bridge between known and unknown.
She points to this concept as key to understanding how trust functions in regards to AI. “Right now, if these large language models or ML model that serves you is this magic box of unknown, there is quite a gap that you’ve got to bridge in order to know and trust it,” Zhamak says. “And when we unpack that, we see this box is composed of two main things: a mathematical model and a lot of data that’s been fed to that model. The models are usually open, they’re well-known, there are papers around them. But the data is the area where you probably don’t know what went into it, where it came from, what it includes, and what it excludes. So when we go back to trust and knowing, we have to break that down and understand why people don’t trust their data.”
For Max, building trust in AI and data both tie back to metadata. “The key to trust in data lies in the metadata — how accessible it is, and how it’s presented to users,” he says. “If someone looks at an NRR trend, they’re going to ask, ‘How do I trust this? Who built what for this number to get here? What is the lineage? How fresh is the data? How is it used by other people in my organization? Is it a metric everyone uses every day? Can I see the pipeline? Can I see the data source?’”
Using data observability tooling to provide visibility into the data that powers AI products — including information about accuracy, freshness, and lineage — will help build trust throughout the organization.
“The CEO of a Fortune 500 company may not be able to go into their Airflow pipeline to figure out how it was computed,” says Max. “But being able to see who built the pipeline and being able to talk to them can build some trust.”
John shares how his team at shiftkey provided extra visibility into data freshness after experiencing a few instances of data downtime. “We started to feel that business users didn’t fully trust our data because, at a time or two, we had some data blips,” he says. “So we integrated the Monte Carlo data observability API to expose data freshness on the reports themselves, almost like metadata. We kept it really simple, just green or red. So when somebody came to a report, they didn’t have to worry about the data being out of date. They knew that it was all green.”
Prediction 5: The limit for AI innovation does not exist
Finally, our panelists agree on one thing about the future of AI: the possibilities are about to expand beyond our current imagination.
“I think the limitations we see now are going out the window,” says Maxime. “Custom training, fine tuning at scale, isolated models for each one of your customers or however you want to segment — that stuff is happening fast and accelerating. It’s the .com boom of AI — every company is going to get funded.”
Still, Maxime cautions data teams not to throw their existing tools out the window in favor of AI-centric newcomers promising magical results. “People are going to come and try to sell you a new alternative to dbt, Monte Carlo, Superset, Tableau — ‘We have a completely new way of doing things that is AI-powered’,” he says. “But at the same time, AI is coming into all the tools you already use every day. I think, at least in the short-term, it’s better to stay with the tool that you already use. The AI integrations they bring in will have access to all your metadata, you’ll be in workflows you already know, and it will help you be more productive with the tools you already use. For this phase, it makes a lot of sense to do that as opposed to going with the hot new thing that is selling some magic.”
In the short term, Zhamak predicts that AI will become practical for enterprise applications through advancements like vector databases, rack prompting, and autonomous agents. But what excites her most is how AI will change how we think. “It’s not going to have any practical impact at scale over the next year, but AI is going to impact our imagination and the way we think about the possibilities of the future.”
She describes attending a demo of a prototype in the co-generation programming space. “My mind was blown. I came home that night depressed and excited. At the same time, I felt like a caveman standing at the edge of the invention of fire. I cannot even possibly imagine how this fire is going to impact how I digest food, how my brain is going to grow, and how that will lead to a completely new future as a caveman. That’s how I felt. Some of this tooling will not be super practical for day-to-day application, but they’re going to open up this dreaming space of what could be possible years down the road. That’s super exciting.”
Laying a foundation of high-quality data for transformative gen AI
As data leaders and teams focus on implementing gen AI-powered applications, one thing will never change: the data feeding those models needs to be accurate, reliable, and trustworthy.
Data observability is essential to ensuring quality and building trust in the era of generative AI. Get in touch with our team to learn more about this must-have layer in your data and AI stack.
Our promise: we will show you the product.
Read more posts.