Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Decoding the Data Mesh


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Zhamak Dehghani, founder of the data mesh, dispels common misunderstandings around this the data mesh, an increasingly popular approach to building a distributed data architecture, and shares how some of the best teams are getting started.
Nowadays, it seems like every data person falls into two camps: those who understand the data mesh and those who don’t.
Rest assured: if you’re in either camp, you’re not alone!
Rarely in recent memory has a topic taken the data world by storm, spawning a thriving community, hundreds of blog articles, and sighs of relief from data leaders across industries struggling with democratization and scalability.
But with this new adoption comes new opportunities for misunderstanding around the true nature of a data mesh – and how to build one.
A few months ago, I joined Thoughtworks’ Zhamak Dehghani, pioneer of the data mesh framework, and Lena Hall, Director of Engineering, Big Data at Microsoft, for a discussion about all things data mesh. During the conversation, Zhamak dispelled many of its biggest misconceptions, including whether or not the data mesh was a standalone technology, who should (or shouldn’t) be building one, and if data mesh is just another word for data virtualization (hint: it’s not).
Here are just a few of the key takeaways from our conversation— be sure to listen to the entire recording for even more myth slaying and insight serving. (Note: some quotes have been edited for length and clarity.)
Can you build a data mesh from a single solution?

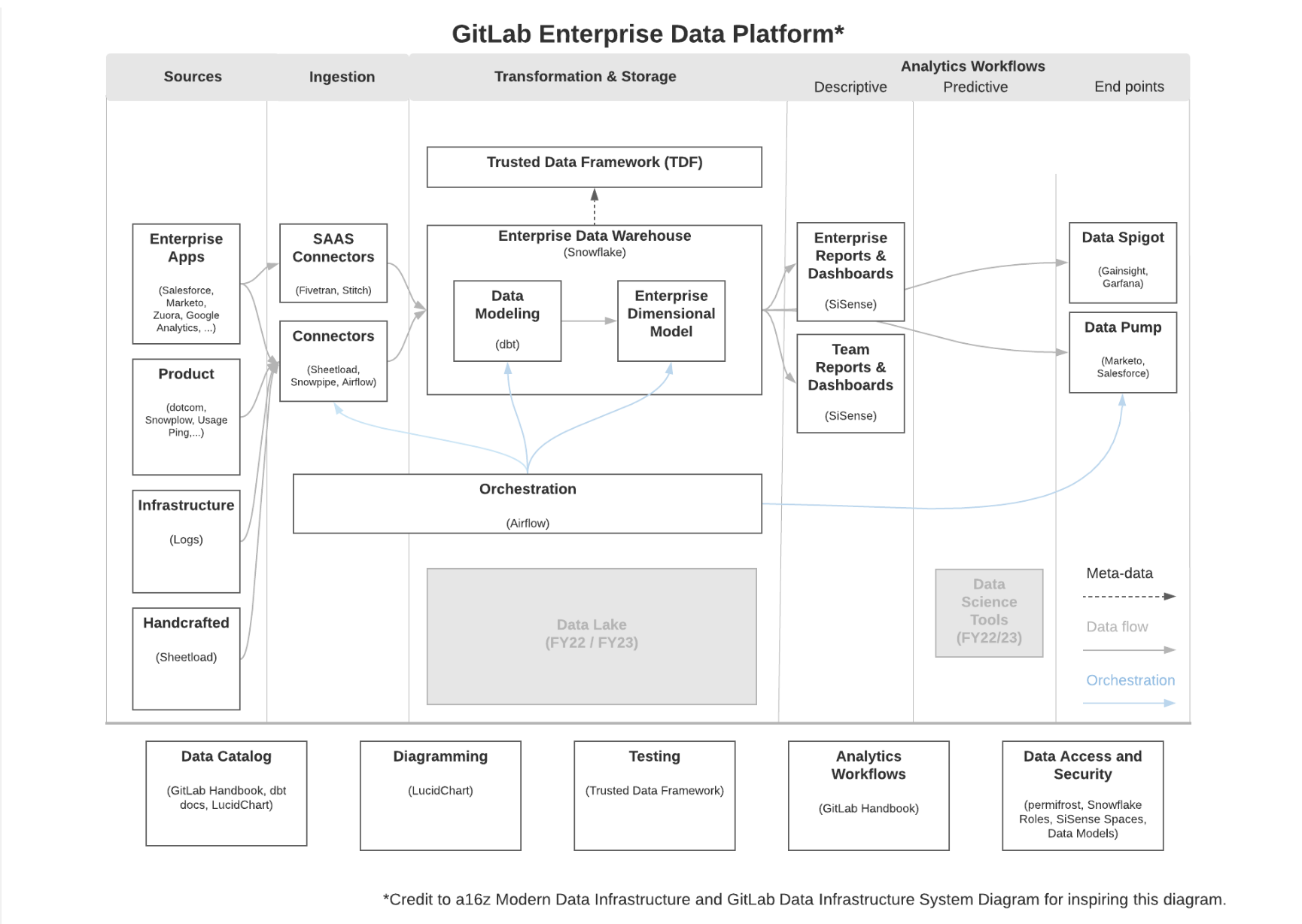
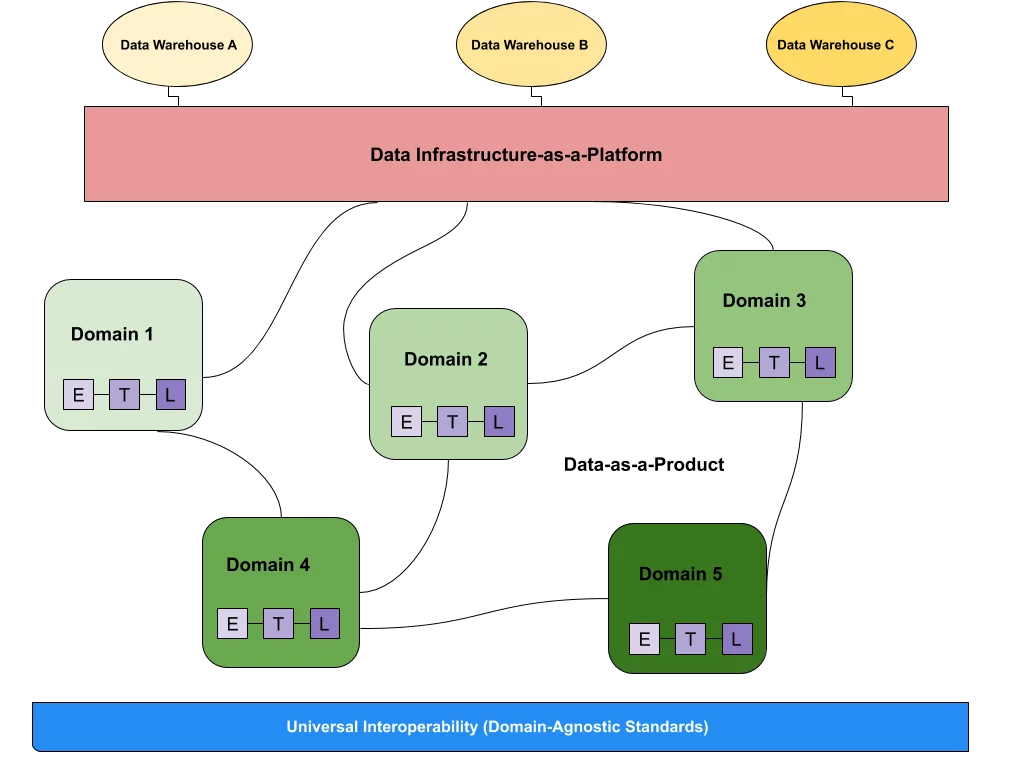
Zhamak defines the data mesh as “a socio-technical shift—a new approach in how we collect, manage, and share analytical data.” The data mesh is NOT a technical solution or even subset of technologies – it’s an organizational paradigm for how we manage and operationalize data, made up of several different technologies, whether open source or SaaS.
You couldn’t build a microservice architecture with just a database. And you wouldn’t build a data mesh with just a modern data warehouse or a BI tool. Instead, a data mesh can be powered in part by these technologies — and many, many others.
In a nutshell, a data architecture is a data mesh if it includes these four basic elements:
- Distributing ownership of data from one centralized team to the people who are most apt and suitable to control it—often, the business domains where the data comes from
- Giving those teams long-term accountability and equipping them with the product thinking they need to treat data as a product
- Empower teams with a self-serve data infrastructure
- Address new problems that may arise with a new model of federated data governance
On to the next.
Is data mesh another word for data virtualization?
There’s confusion in the data community about how decentralized data ownership actually works. As Lena describes, some technicians wonder if the concept of decentralized data ownership overlaps with the concept of data virtualization, in other words, an approach to data management that allows an application to retrieve and manipulate data across many silos.
According to Zhamak, it used to be the case that virtualization sits on top of your OLTP systems and your microservices or operational databases and exposes that data as-is or with some minor transformation. And when it comes to applying this to the data mesh, it’s probably not a wise idea.
“Whether it’s a data mesh or an API base, you’re trying to expose a database that has been optimized for a transactional purpose for analytical purposes. And predictive analytics or historical trend modeling both require a very different view of the data,” she said. “If you think about using virtualization on top of your microservices database and expose them and call that a mesh, that is probably a bad idea.”
Does each data product team manage their own separate data stores?

According to Zhamak, the answer to this question is no.
“Data mesh would say that as a data product developer, I would want to have autonomy—to have all of the structural elements, the storage and compute, and query system, and all of the things that allow me to serve my data to data scientists,” Zhamak explained. “But that doesn’t mean I have to now have my own geo-location-separated storage layer. In fact, if the mesh is an inter-organization setup with one cloud provider, you probably wouldn’t do that. And you might have a single storage layer. However, they’re independent schemas, they’re independent access rights management, they’re independent tenancy models that allow the data product to be deployed in an autonomous fashion.”
The data store is often maintained by a central data engineering or infrastructure team responsible for ensuring that the data mesh is functional and operationalized for each domain. While analysts and data scientists in each domain are in charge of building and maintaining products (say, dashboards, models, and reports) on top of the data mesh, they’re not the ones managing the infrastructure making the analytics, data science, and ML possible.
Is a self-serve data platform the same thing as a decentralized data mesh?
Large organizations are already implementing self-serve platforms for infrastructure management, but according to Zhamak, the self-serve aspect of the data mesh is different in a few key ways:
“The majority of the service or data platforms built today are built for centralized data teams—they’re built to help data specialists move through their backlog faster. They’re built to serve a centralized team that’s trying to optimize ingestion from all corners of the universe.
Data platforms, in their current state, are often optimized for a different purpose than the data mesh. Data platforms built to support the data mesh should be optimized to give autonomy to domain teams and give generalist technologists the ability to create data products— to manage their data from end to end and directly serve their data consumers: data analysts, data scientists, and other end users.
Is the data mesh right for all data teams?
While more and more organizations are beginning to adopt or explore the data mesh, Zhamak believes the model is “still fairly nascent in its evolution.”
Organizations that face the problem of scaling data reliability are the organizations where adopting the data mesh makes the most sense. Early adopters tend to be engineering-focused and open to investing in “both building and buying technology, because not all of the elements are available to buy,” Zhamak said.
According to Zhamak, if your stakeholders feel the pain around finding the right data and using it, and your innovation cycle is being slowed down, then you might be the right candidate for looking into the data mesh.
In 2021, data teams are getting bigger earlier, and data is becoming more universal. And as a result, there needs to be an earlier movement around a self-served, decentralized way to manage data without reinventing the wheel. The data mesh can help.
Does one person on your team “own” the data mesh?

Introducing the data mesh model requires more than just technology. It takes cultural buy-in across the organization.
“I think data and all the data-driven initiatives and data platform investments are so highly visible and so highly political in organizations, especially large organizations, that there has to be top-down support and top-down evangelism,” said Zhamak.
She attests that when organizations have a Chief Data Officer or a Chief Data Analytics Officer reporting directly to the CEO, they’re often more effective when it comes to data mesh adoption at scale. Still, the domains are the ones expected to take on ownership of their data, and as such will need to support this initiative, whether that means dedicated resources or interorganizational cheerleading.
“If the domains aren’t on board, all we’re doing is overengineering the distribution of data among a centralized team,” she said.
When you’re trying to grow adoption for the data mesh at your organization, teams should get one to three domains that are aligned with the vision to serve as advocates pushing the design and implementation forward. Usually, the infrastructure teams—the practitioners and the engineers—aren’t the difficult ones to convince since they’re often the ones feeling the pain.
Does the data mesh cause friction between data engineers and data analysts?
Again, the answer is: no. In fact, it’s often the opposite!
Because the data mesh mandates the decentralization of data ownership, adopting this distributed, domain-oriented model often leads to healthy reconciliation in areas where there’s historically been friction.
For instance, when organizations have an engineering team responsible for pipelines, and a data engineering group modeling data downstream, and then analysts further downstream that are consuming the data, incidents can often lead to finger pointing. But the data mesh’s universal standard of data governance ensures that there is agreement around data quality, data discovery, data product schema, and other critical elements of data health and understanding.
According to Zhamak, such self-serve capabilities inherent to any good data mesh include:
- Encryption for data at rest and in motion
- Data product versioning
- Data product schema
- Data product discovery, catalog registration, and publishing
- Data governance and standardization
- Data production lineage
- Data product monitoring, alerting, and logging
- Data product quality metrics
When packaged together, these functionalities and standardizations provide a robust layer of observability – and trust.
“The evolution that we saw in the operational world started with our own ad hoc structured logging, which was a thing we already do as a good software engineering practice,” said Zhamak. “I really hope that, with lineage and metrics and SLOs, we develop some open standards that we can use to convey these kinds of quality metrics, like your trust matrix, or tracing lineage in a standardized fashion and creating a healthy ecosystem of tooling on top of it.”
In my opinion, organizational structures like data mesh actually allow for the right kind of autonomy and discussion around governance, forcing your team to answer such questions as: When and how should data be used? What are the standards that we care about that we want to enable everyone to have? Or even: which responsibilities should each domain own?
Fact: data mesh is a shift towards decentralization and democratization
Regardless of where you stand on the data mesh, there’s no question the topic has inspired conversation around what it means to be a data professional, and what it takes to truly evangelize and operationalize data at scale for your organization.
In fact, many companies I talk to have been applying data mesh concepts for longer than they realize; they just didn’t have the words to describe it.
Often, this starts with better communication between data teams and stakeholders, organizational alignment, and understanding of the role of data at your company. And with these three pillars in place, it’ll be much easier to avoid even the most difficult mesh-conceptions.
Be sure to check out the Data Mesh Learning community for more live events or to join their Slack channel.
Have more questions about the data mesh? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.