Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Unleash the Quacken: A Dummies’ Guide to DuckDB


Michael Segner
Michael writes about data engineering, data quality, and data teams.
A duck walks into a database and asks the bartender, “Got any data to crunch?”
The bartender replies, “Sorry, we only serve row-based queries here.” The duck smirks and says, “No problem, I brought my own columnar storage!” And that’s how DuckDB waddled its way into the world of data analytics – or so I imagine.
As an embeddable, open-source analytical database management system known for its columnar storage and vectorized query execution, DuckDB delivers faster and more efficient performance for complex analytical queries compared to row-based databases.
Who is DuckDB for?
If you’re reading this you’ve undoubtedly seen the hype around DuckDB. It’s used by Google, Facebook, and Airbnb. It was on O’Reilly’s Radar Trends to Watch. A startup called MotherDuck, focused on commercializing DuckDB packages, raised a series A round led by Andreessen Horowitz. There’s this tweet:
— Matthew Mullins (@mullinsms) August 9, 2022
Yet who exactly is DuckDB for and what do they get out of it that makes DuckDB so amazing?
Here’s who’s using DuckDB and what for:
- Data Analysts: Analysts working with large datasets and complex analytical queries benefit from DuckDB’s performance and columnar storage. They can run SQL queries on data sources like Pandas DataFrames and Parquet files directly, without importing the data into the system, speeding up their workflow.
- Data Scientists: Data scientists using languages like Python and R can take advantage of DuckDB’s APIs and seamless integration with Pandas, enabling them to perform complex data manipulation and analysis tasks more efficiently.
- Software Developers: Developers who need to embed a lightweight, high-performance database in their applications are choosing DuckDB. Its small binary size, minimal dependencies, and cross-platform support make it an ideal option for embedding in various types of applications.
- Database Administrators (DBAs): DBAs use DuckDB for managing and optimizing analytical workloads, particularly when dealing with larger-than-memory datasets or wide tables. DuckDB’s parallel execution capabilities can help DBAs improve the performance of data processing tasks.
- Researchers: Academics and researchers working with large volumes of data use DuckDB to process and analyze their data more efficiently. DuckDB’s open-source nature and support for multiple programming languages make it an accessible and cost-effective option for research projects.
- Data Engineers: Data engineers who work with data pipelines and ETL processes use DuckDB to enhance the performance of their data processing tasks. They can leverage DuckDB’s efficient query execution and integration with data formats like Parquet to optimize their data workflows.
What makes DuckDB different?
First, there is no one-size-fits-all database system. DuckDB themselves are first to admit that you shouldn’t use it for large client/server installations or high-volume transactional use cases.
Where DuckDB is creating a different path is as an embedded analytical database. Kojo Osei from Matrix Partners has a similar diagram to the one below showing where DuckDB sits:
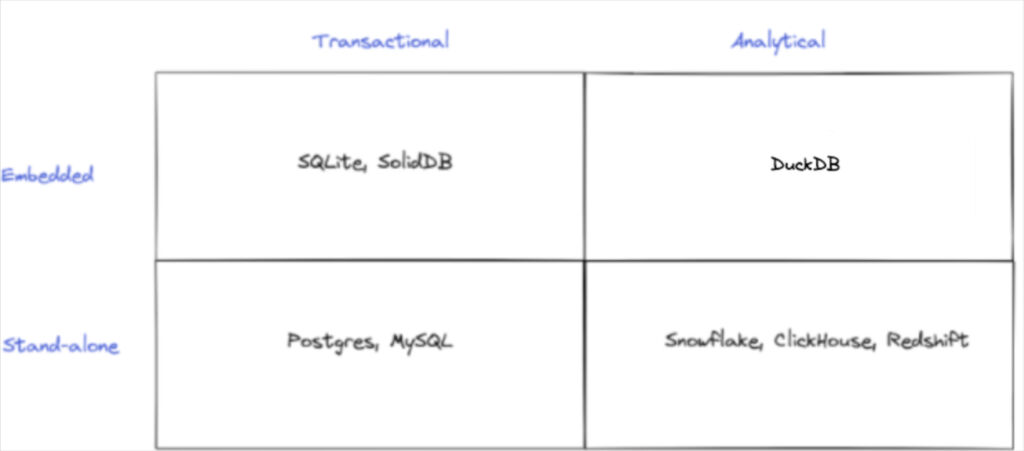
Whereas a stand-alone analytical data warehouse uses a client-server model, where the database sits on a centralized server and is queried by a client application, DuckDB is tightly integrated with the application and runs on the same host compute resources.
This in-process design simplifies data access and processing for applications, as it doesn’t require an external server or communication between processes, thus reducing latency and complexity. This makes DuckDB great for IoT use cases by performing analysis directly on edge nodes, as well as simplifies machine learning pipeline setup by running in the same application host process, removing the need to replicate data.
When you outgrow DuckDB, stay on top of data quality issues with Monte Carlo
While DuckDB is excellent as an embedded analytical database, when your data needs expand beyond what can run on a single machine, that’s when you’ll need a full-fledged solution to maintain the health and performance of your stand-alone data warehouse.
Enter the data observability platform Monte Carlo. Monte Carlo understands and tracks the data flowing through your pipelines to enable you to detect and address issues promptly. With data observability in tow, you never have to worry about data quality issues causing broken data pipelines or data downtime.
Let us show you what data observability and DuckDB can do by signing up for a demo using the form below.
Our promise: we will show you the product.
Read more posts.