 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How We’re Implementing a Data Mesh at Sanne Group


Martin French
Group Head of Data Engineering at Sanne Group
Initial thoughts on our data team’s data mesh implementation plan and moving toward the four data mesh principles of domain data ownership, data as a product, self-service, and federated governance.
The buzz around the data mesh is interesting in that many data professionals have opinions about it, some are even moving towards it, but very few are bold enough to claim they have done it.
As I begin to plot our data mesh implementation plan at Sanne Group, a leading asset management services provider, I can see why this idea that was originally introduced in 2019 has gained so much mindshare, but so few fully formed meshes nearly four years later.
As my fellow data engineering leaders can attest, it is much easier to scale data pipelines than to scale organizational change. The four principles of the data mesh–domain driven data ownership, data as a product, self-serve data platform, and federated governance–all require sweeping changes and widespread buy-in.
So much so, that my data mesh implementation plan is to approach these principles in uneven, iterative phases that are driven by the needs of the business. While the decision in implementing a data mesh is strategic, execution will be both opportunistic and pragmatic.
In sharing our plan to adopt and adapt the data mesh dogma, my hope is that it will generate a discussion that will help accelerate our journey and others.
In this post I will cover:
- Why we are moving to a data mesh
- Our approach building a data mesh architecture
- Our approach to domain-driven data ownership
- Our approach to treating data as a product
- Our approach to self-service
- Our approach to federated governance
- Our data mesh implementation will get some things wrong, and that’s OK
Why we are moving to a data mesh
If the data mesh journey is arduous with many anticipated starts and stops, why embark on it at all? For me, the answer is people and the very specific position our company holds as a global financial institution.
I can hire the world’s best data analyst, but without specific domain knowledge, the learning curve toward productivity is too steep and the consequences of poor analysis are too severe. It is much more effective when we can harness the existing knowledge within our organization, advance their data literacy, and empower them with the right tools.
Another way to look at it is that the data analyst embedded in a domain may be great with the data, but the domain expert empowered as a data analyst is going to ask great questions–and asking the right question is one of the most important and overlooked qualities of a data-driven organization.
The other big driver is speed. When you have a centralized data team structure, the journey from an analyst’s question to an answer might travel through seven distinct steps across different members of the team each of whom have a SLA of 24 to 48 hours. That adds up!

Our approach building a data mesh architecture
While a pure data mesh is a federated set of interconnected domains that are of roughly equal stature, there are multiple variants that may better serve the unique needs of your organization.
Piethein Strengholt, a senior cloud solution architect at Microsoft, has an excellent description and visualization of some of the data mesh variants he has seen in the wild.
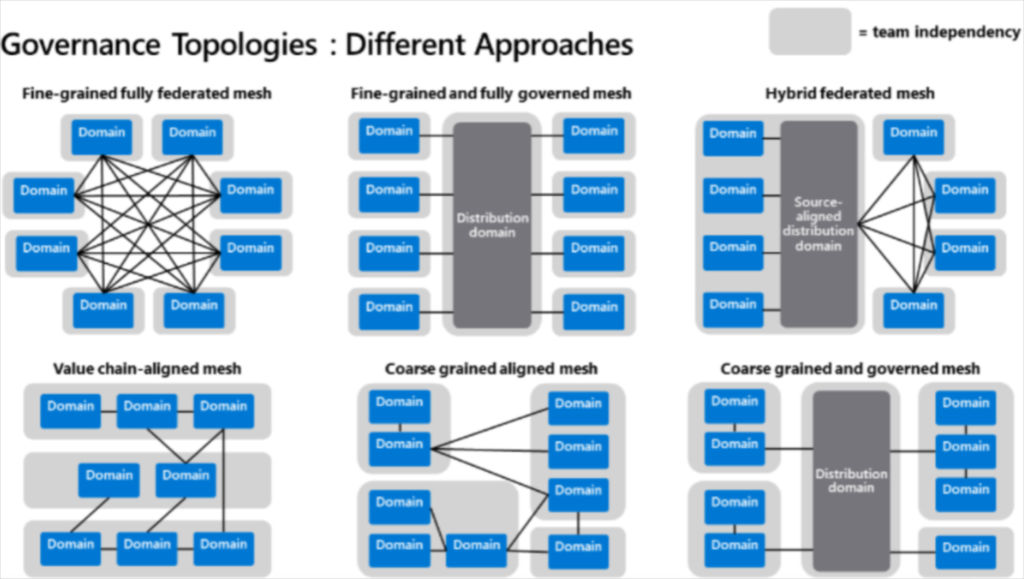
The current data mesh implementation plan at Sanne would most closely resemble the “coarse grained and governed” mesh. There will be a “center of excellence” consisting of a small team of data engineers that will facilitate communication and help form a central set of standards, but each domain will be empowered to shape their infrastructure, products, and governance according to their specific situation.
There are a few factors shaping this architecture. I joined the company within the last year, and we are currently in the process of integrating our $2 billion merger with Apex. This means both our data team and modern data stack are in both a period of transition and a greenfield state.
Having been given somewhat of a blank canvas and a mandate for growing the team, I am resisting the urge to immediately paint the big picture and instead allow space for organic, decentralized evolution (with guardrails of course).
For example, I anticipate each domain growing and maturing at very different paces because their workflows are more or less data centric. They will be staffed accordingly. For instance, the Risk department may start with a smaller team of data engineers and analysts building their own models and gradually move toward cognitive analytics requiring data scientists to be added to the team whereas it’s likely the Finance department will be very data analyst heavy.
Because there is always a lag time between the business need for data talent and being able to fill it, especially in today’s market, the center of excellence will also serve as a pool of talent that can be deployed to fill short-term gaps as long-term solutions are in progress.
The other driving factor is the Sanne Group has offices in more than 20 countries around the globe serving more than 2,135 clients. The data regulatory regimes vary widely requiring teams to have more flexibility in their governance models.
Our approach to domain-driven data ownership
In a fully decentralized data mesh the lines of data ownership are clear, but for our more coarsely grained data mesh there could be questions around who has overriding authorization.
Is it the domain or center of excellence? What about situations where multiple domains have a stake in a certain data asset? Salary data, for example, is relevant to both HR and finance.
My answer is accountability and authorization must sit with the domain. That being said, especially during the early days of our transition, I plan to have a few key assets and reports sit with the center of excellence until our evolution has matured.

In addition to the concept of data owner, we will also have the concept of a data trustee. This role will be occupied by one of the domain leaders with the understanding that they do not own the data outright but are responsible for overseeing it in coordination with other stakeholders.
Our approach to treating data as a product
The initial data mesh implementation plan is for data products to follow a set of criteria, but to not have a standard bar that must be cleared (consistent with the overarching goal to enable as much flexibility as possible).
For example, data products must have an outlined data model, quality standard, defined lineage, and governance plan–but the level of quality and governance required can vary by domain. The idea here is that the production process of Hyundai and Rolls Royce look very different even if they are making the same type of product.
For Sanne, it would not make sense to hold all domains to the same standard as what has been set for our highly regulated financial data.
Data as product is where the rubber will hit the road for our data mesh strategy. Our plan is to create our first data product (as defined by data mesh principles) for the data set leveraged by almost every business unit: customer data.
In this way, we can learn by doing and create our newly decentralized processes and procedures collaboratively in a way that helps us understand that while our operations are decentralized we are still interconnected. This will also establish buy-in and give everyone at the table a voice as we start.
Our approach to self-service
Self-service is an incredibly daunting and fraught objective. Many of the modern data infrastructure providers describe a central platform where all data lands from all different sources. But then how do you build an interface, how do you use an analytical tool, to serve all use cases for all audiences across all domains?
I think the reality, at least for us in the short-term, is that you have to look at it by use case and bring the data to the user rather than bring the user to the data. What I mean by this is that each domain has their own set of tools they are comfortable using to access and analyze data.
For marketing and sales it might be the CRM system for example. That is your self-service entry point.
This approach will also help right size our efforts. Our stakeholders are not in the business of self-serving data for the sake of it, they are doing it to do their job.
Rather than have a central point with all sorts of self-service hooks for all sorts of hypothetical use cases, we can focus on actual stakeholder workflows where users are motivated to become more data centric. We can be iterative and duplicate what we have found to be successful.
That being said, I am very open to admitting this may be the wrong approach and will be keeping a close eye on it. The biggest risks of course are creating data silos and duplication among the solutions in our stack.
Data literacy is also at the heart of our self-service approach. This has been an active two pronged strategy. The track geared toward the analyst and semi-technical data professionals focuses around the four types of analytics (descriptive, diagnostic, predictive and prescriptive) and a track geared toward the wider business.
Our approach to federated governance
I’ve talked a bit already about our data mesh implementation plan to include very domain-centric governance partly as a result of the diversity of the regulatory regimes we face.
What I will add to that is all the other principles of the data mesh work together to improve not only data governance, but data quality. Data quality is at its highest when the people working with the data are the ones closest to it.
Data certification and “golden data sets” with high veracity and SLA adherence are concepts that I foresee being layered onto this principle. Additionally, the ability to have our data mesh automatically mapped and visualized through data lineage is a high priority item for the center of excellence that will enable the freedom we want to provide to our domains.
Our data mesh implementation will get some things wrong, and that’s OK
I am excited for the Sanne Group data team’s next phase. Our team is growing by leaps in bounds, both in capability and headcount.
High quality, domain-driven data is absolutely essential to our mission to be one of the world’s leading providers of alternative asset and corporate administration services, and will be foundational to our data mesh success.
The data mesh may not be for the faint of heart, but I’m confident that by listening to the business and iterating, our team can provide unprecedented value.
Interested in how data observability can play a key role in your data mesh implementation plan? Talk to us!
Our promise: we will show you the product.
Read more posts.





