Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The New Face of a Data Governance Model


Molly Vorwerck
Molly is Head of Content & Communications @ Monte Carlo.
Data governance doesn’t need to be a hassle. It just needs to meet data teams where they are: in distributed organizations.
Here’s why our longstanding approach to data governance isn’t a fit for the modern data stack and what some of the best data teams are already doing about it.
Data governance is top of mind for many data leaders, particularly in light of GDPR, CCPA, IPOs, COVID-19, and any number of other acronyms that speak to the increasing importance of compliance and privacy when it comes to managing your company’s data.
Traditionally, data governance refers to the process of maintaining the availability, usability, provenance, and security of data, and, as a data leader once told us, is the “keep your CFO out of jail card.”
Still, Gartner suggests that more than 80 percent of data governance initiatives will fail in 2022.
Frankly, we’re not surprised.
While data governance is widely accepted as a must-have feature of a healthy data strategy, it’s hard to achieve in practice, particularly given the demands of the modern data stack.
Data governance model B.C. (before cloud)
We owe this shift in how we approach governance to one key catalyst: the cloud.
Before the rise of the cloud data warehouse (thanks Snowflake!), analytics was primarily handled by siloed teams. Cloud architectures and the tools that powered them made it cheaper and easier than ever before to spin up analytics dashboards and reports. Suddenly, Joan from Marketing and Robert from Finance could glean near real-time insights about the business without having to ping the Data Science team every time they had to present to their board.
Data was *actually* becoming democratized. Sort of.
While the technologies enabling data to become more accessible and easier to use were innovating at an unprecedented pace, the tools and processes in place to ensure that data was easily discoverable and reliable (in other words, data governance) are falling short of our needs.
Here’s why.
A manual approach to governance is no longer cutting it.
While we’ve made great advancements in areas such as self-service analytics, cloud computing, and data visualization, we’re not there yet when it comes to governance. Many companies continue to enforce data governance through manual, outdated, and ad hoc tooling.
Data teams spend days manually vetting reports, setting up custom rules, and comparing numbers side by side. As the amount of data sources increase and tech stacks become more complex, this approach is neither scalable nor efficient.
While data catalogs often market themselves as the answer to data governance, many data leaders find their catalogs lacking in even the most rudimentary aspects when it comes to manual requirements.
In some organizations, these operations take up a significant amount of time in manually mapping upstream and downstream dependencies — not to mention the maintenance work required to keep this up to date.
Data is everywhere; data governance is not.
For many companies, increasing the speed of data innovation is critical to survival. While data infrastructure and business intelligence tools have advanced to support this innovation over the past several years, DataOps has lagged behind with most DataOps solutions like data quality alerts and lineage tracking being manual, one-dimensional, and unscalable.
One of the ways in which DataOps and solutions can catch up is by drawing on concepts from software engineering. Many of the problems we face in data are in fact problems that have been solved in engineering, security, and other industries.
As companies migrate to more distributed architectures (i.e., the data mesh), the need for ubiquitous and end-to-end governance has never been greater.
The good news? We don’t have to accept the status quo. In the same way that software engineering teams lean on automation, self-healing processes, and self-service tooling, data teams need to take a similar approach by embracing the new face of data governance.
Here’s why – and how.
Things have changed
Many things have changed since the B.C era. Before painting the new face of data governance, it’s key to understand the structural changes which brought about the need for renewal. This part is dedicated to exploring the catalysts to new data governance practices.
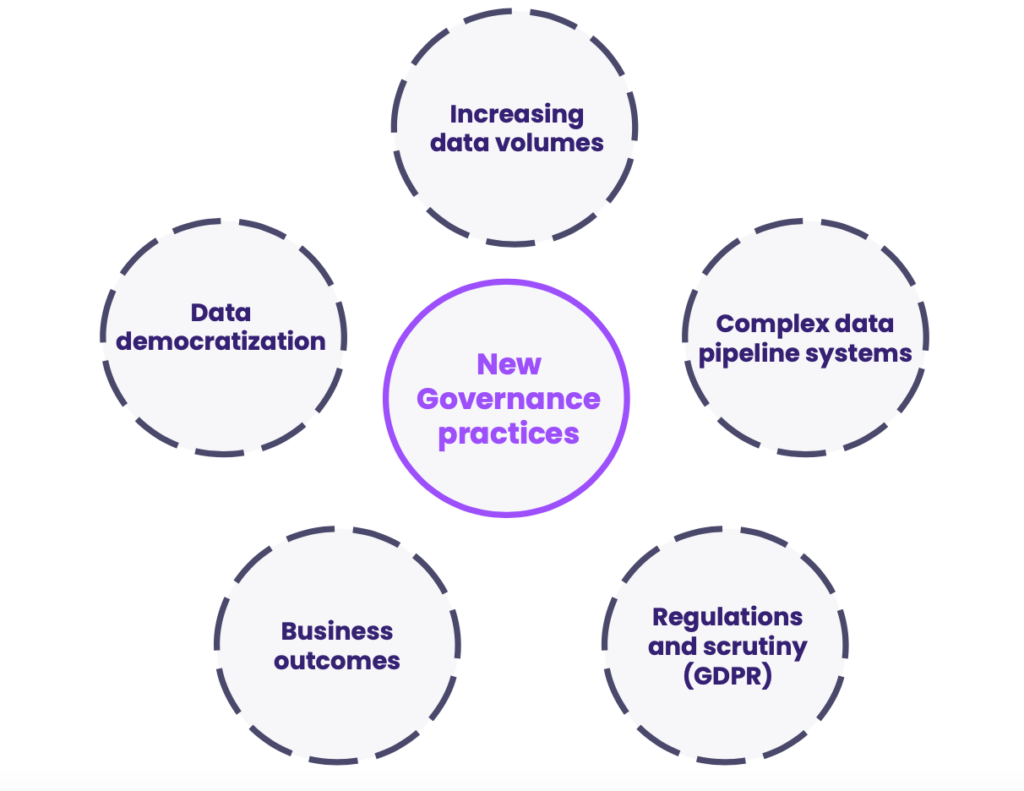
1. Companies are ingesting increasing amounts of data
In the past few decades, storage and computation costs have plummeted by a factor of millions, with bandwidth costs shrinking by a factor of thousands. This has led to the exponential growth of the cloud, and the arrival of cloud data warehouses such as Amazon Redshift or Google BigQuery. The peculiarity of cloud data warehouses is that they are infinitely more scalable than traditional data warehouses, with a capacity to accommodate virtually any amount of data.
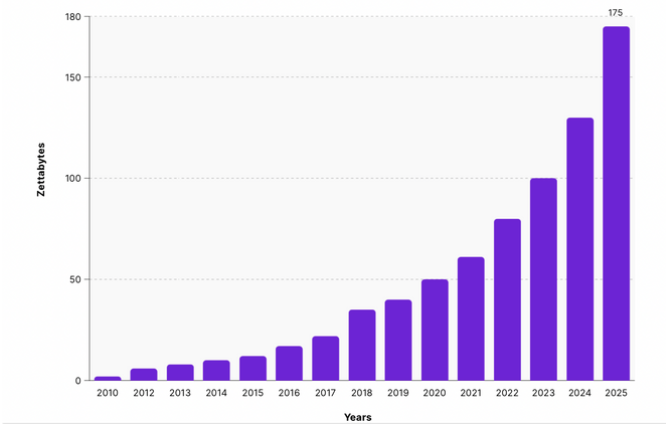
These developments allowed organizations from all horizons to collect and store tremendous amounts of data. Data is now far more disparate and distributed than it used to be and it can be characterized by the “Three Vs” of big data: soaring volume, variety and velocity.
The very nature of data has changed, which should prompt a change in data governance models that are meant to manage this data.
2) Pipelines and ecosystems are becoming increasingly complex
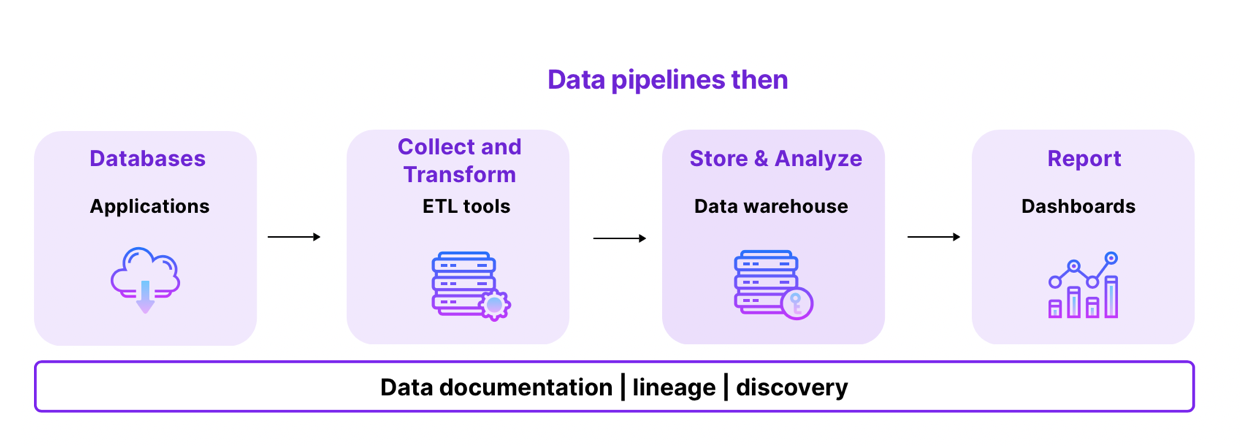
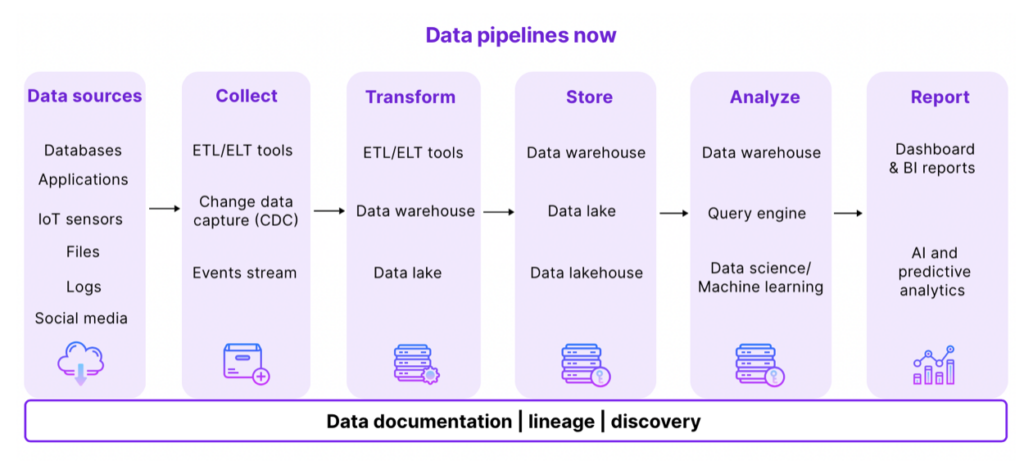
Until 15-20 years ago, data pipelines were rather basic, serving stable requirements for business analytics. Business intelligence teams required historical measures of their financial position, inventory levels, sales pipelines, and other operational metrics. Data engineers used ETL (Extract, Load, Transform) tools to transform the data for specific use-cases and load it in the data warehouse. From this, data analysts created dashboards and reports using business intelligence software.
Data pipelines now run with a combination of complex tools (Apache Spark, Kubernetes, and Apache Airflow, to name a few), and as the number of interconnected parts increases, so does the risk of pipeline failure. The diversity of tools is necessary, as it allows data teams to choose the best platforms at each layer of their data stack. But the combination of all these engines makes it practically impossible to gain visibility into the different parts of the pipelines.
Modern data pipelines are not only complex, but they also have blackbox features. You know what goes in, you know what comes out, but you have no clue of what happened in between. It’s fine as long as the desired outcome comes out. But when it doesn’t, it’s highly frustrating. When data sets come out of the pipeline, you are often left with strange values, missing columns, letters in fields that were meant to be numeric, and so on. As a result, data engineers spend hours scratching their heads about what on earth went wrong, where, and how to fix it. Forrester estimates that data teams spend upwards of 40% of their time on data quality issues instead of working on value-generating activities for the business.
Traditional data governance models are not suited to these highly complex systems, causing data to break for obscure and unexplainable reasons. We need to shift towards a new model which can deal with this new level of complexity.
3. Data is under more scrutiny than ever before
Data is not only more voluminous, it is also more regulated and scrutinized. Although the first regulations related to data privacy came into force in the 1990s, they only became a worldwide issue in the 2010s with the appearance of GDPR, HIPAA, etc.. This led to the emergence of data governance tools, which helped enterprise-level organizations comply with these tight requirements. At the time, only enterprise-level organizations could afford the infrastructure necessary to collect and store data. Hence, they were the only ones who faced data compliance issues.
But as we’ve seen in the above section, the 2010s also marked the exponential growth of data volumes in organizations thanks to cloud storage. This cheap storage alternative allowed startups and SMBs to collect and store considerable amounts of data. The problem was, GDPR, HIPAA, and other regulations leave no small business exemptions and demand that businesses from all sizes follow the law and take their responsibilities for handling personal data. Companies still need to comply with GDPR, even if they have less than 250 employees. This gave rise to the challenge of data governance for small businesses, as startups and SMBs started to face enterprise-level problems. Existing data governance tools are out of the question for SMBs, as their pricing model reflects their enterprise focus (i.e they’re super expensive).
The cost of collecting and storing data has drastically fallen in the past decades, it’s time for the cost of managing the integrity and security of this data to follow the same trend. New data governance models need to take into account that compliance is not just for big actors, but that everyone has to be serious about it.
4. Everyone is using data
With only a few specialized people using data, it’s easy to control access to data and enforce some kind of data traceability. The issue is, data is not reserved for a small group of specialists – it’s now used by everyone.
Today, companies increasingly engage in operational analytics – an approach consisting in making data accessible to “operational” teams, for operational use cases (sales, marketing, ..). We distinguish it from the more classical approach of using data only for reporting and business intelligence. Instead of using data to influence long-term strategy, operational analytics informs strategy for the day-to-day operations of the business. Trends such as code-less BI make operational analytics possible by empowering operational teams to manipulate data.
Organizations are thus increasingly aiming at democratizing data, ensuring everyone can access the data they need, whenever they need it. Although this brings about many great things, it also creates two major problems:
- With everyone using data and building reports/dashboards/new datasets, organizations quickly end up with numbers that don’t match between different departments.
- It became much harder to control the level of access to data, as well as to ensure data was used the right way and by the right people. This makes compliance issues even more of a nightmare than they were before.
This “data anarchy” cause traditional data governance models to fail, prompting the need for new, more adapted models.
5. Data governance fuels business outcomes

Data governance was born as a response to the tight regulations around data that emerged in the past decades. It used to be perceived as this boring, uninteresting task which you have to complete in order to escape hefty fines. Today, things are different. Data governance does not only allow organizations to escape fines, but it also drives business performance. How so?
From a short-term viewpoint, a strong data governance program ensures data traceability and data quality. It makes data users more efficient at finding and understanding data. It also introduces the ability to reuse data and data processes, thus reducing repeated work in organizations. A more productive data team maximizes the income generation of potential data.
In the long term, good data governance increases consistency and confidence in decision-making. It’s much easier to make a decision when numbers and dashboards from all departments agree than when they go in opposite directions. Disagreement between numbers leads to trust erosion, making the huge investments in data collection largely ineffective.
To recapitulate this part, we went from a world in which a few people needed access to limited amounts of unregulated data, to a world in which everyone needs access to vast amounts of highly regulated data. And it’s no surprise that these two worlds should be governed in a different manner.
What should the new face of a data governance model look like?
In light of the changes in the nature of data, the level of data regulation, and the data democratization trend, it’s safe to say that the traditional, old, boring, data governance is dead. We can’t let it in the grave, as we need data governance more than ever today. Our job is thus to resurrect it, and give it a new face. This section is dedicated to understanding what this new face should look like for modern data governance models to work.
Data governance needs to be secure/compliant
A good data governance program should ensure flawless data compliance. Data compliance refers to the practice of ensuring that all sensitive data is managed and organized in a way that enables organizations to meet legal and governmental regulations. It pertains to the privacy of information considered as personal, and how businesses manage this sensitive data. New data governance models should have you be confident that your organization is adhering to regulations. This should be the building block of data governance programs, as regulations will only tighten in the future, with fines becoming more important.
Data governance needs to be accessible
Data governance should embrace the trends of operational analytics and data democratization, and ensure that anybody can use data at any time to make decisions with no barrier to access or understanding. Data democratization means that there are no gatekeepers creating a bottleneck at the gateway to data.
This is worth mentioning, as the need for data governance to be secure and compliant often leads programs to create bottlenecks at the gateway to data, as the IT team is usually put in charge of granting access to data. Operational people can end up waiting hours until they manage to get access to a dataset. By then, they have already given up on their analysis. It’s important to have security and control, but not at the expense of the agility that data offers.
Data governance needs to be distributed
Traditional data governance programs have organizations manage data through the data steward or a centralized IT team. Given the change in data volumes, this way of doing things can’t do the trick anymore. In fact, it becomes virtually impossible for a single department to keep track of all the organization-wide data. For this reason, data governance must shift towards a distributed model. By distributed, we refer to an organizational framework for delegating data management responsibilities throughout the enterprise. It means the responsibility of data management is split between data users in the organization. It works great, as data users have grown in number thanks to data democratization, which makes it easier to share the burden of data governance.
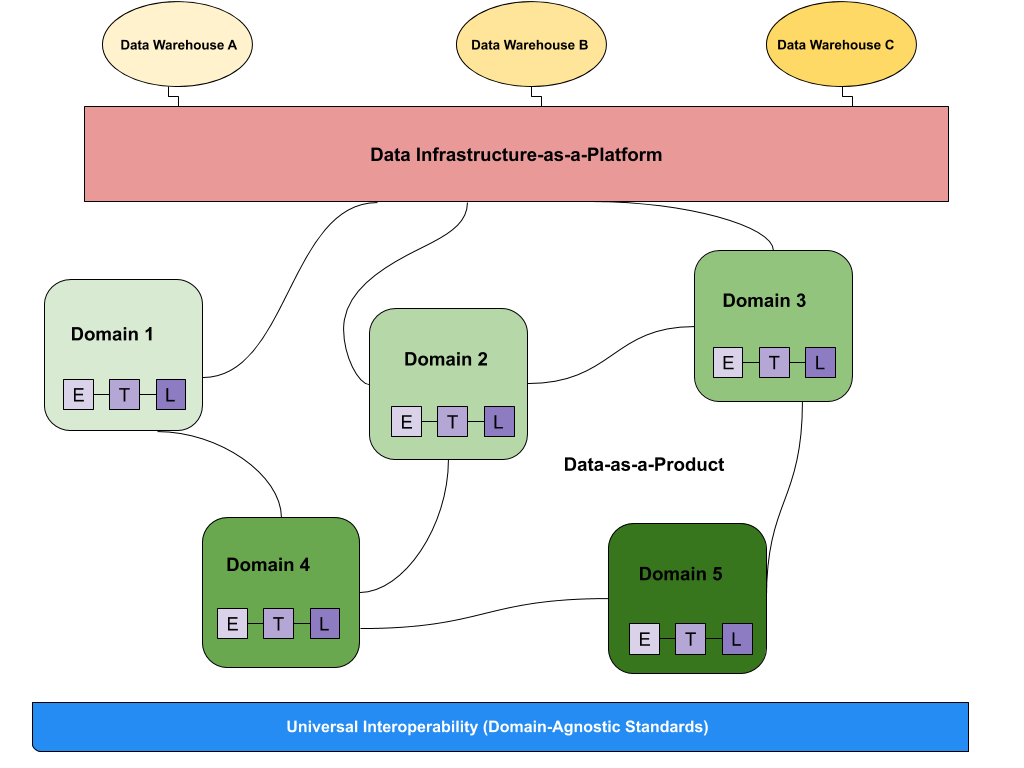
The goal of a distributed data governance model is to allow teams that are closest to the data to manage access and permissions while eliminating the bottleneck that currently exists with centralized IT. This system accomplishes a lot, as it allows data governance to be both secure & compliant while making data accessible to all. We thus need to find a framework or tools which can orchestrate the collaboration of data users to support the data governance effort. Of course, that’s no easy task. If you’re interested in how to achieve distributed data stewardship, check out this article.
Data governance needs to be automated
Data governance processes used to be conducted manually. Yet, data is alive and processes change every hour. What’s more, data volumes managed by organizations make it practically impossible to track data assets manually. It would mean maintaining metadata for 10+ fields for thousands of tables manually. With current data volumes, it would mean hiring a full team just to work on data governance issues. For this reason, it’s time to turn towards automated ways of orchestrating data governance. Automated data governance tools take 10 min to set up on your cloud data warehouse (compared with 6 months for non-automated tools), and minimizes the fields that have to be maintained manually
How do we get there?

Data teams serious about governance need to embrace technologies that lean into the distributed, scalable nature of the cloud AND the distributed nature of modern data teams. To get there, we need to reframe our approach across three different pillars of governance: observability, discovery, and security.
Data Observability
Instead of putting together a holistic approach to address unreliable or inaccurate data, teams often tackle data quality on an ad hoc basis. Much in the same way DevOps applies observability to software, data observability platforms give data teams the ability to monitor, alert for, root cause, fix, and even prevent data issues in real-time.
Data observability refers to an organization’s ability to fully understand the health of the data in their system, and supplements data discovery by ensuring that the data you’re surfacing is trustworthy at all stages of its life cycle. Like its DevOps counterpart, data observability uses automated monitoring, alerting, and triaging to identify and evaluate data quality and discoverability issues, leading to healthier pipelines, more productive teams, and happier customers. Some of the best solutions will also offer the ability to create custom rules and circuit breakers.
Data observability is broken down into its own five pillars: data freshness, distribution, volume, schema, and data lineage. Together, these components provide valuable insight into the quality and reliability of your data.

Freshness: Freshness seeks to understand how up-to-date your data tables are, as well as the cadence at which your tables are updated. Freshness is particularly important when it comes to decision making; after all, stale data is basically synonymous with wasted time and money.
Distribution: Distribution, in other words, a function of your data’s possible values, tells you if your data is within an accepted range. Data distribution gives you insight into whether or not your tables can be trusted based on what can be expected from your data.
Volume: Volume refers to the completeness of your data tables and offers insights on the health of your data sources. If 200 million rows suddenly turns into 5 million, you should know.
Schema: Changes in the organization of your data, in other words, schema, often indicates broken data. Monitoring who makes changes to these tables and when is foundational to understanding the health of your data ecosystem.
Lineage: When data breaks, the first question is always “where?” Data lineage provides the answer by telling you which upstream sources and downstream ingestors were impacted, as well as which teams are generating the data and who is accessing it. Good lineage also collects information about the data (also referred to as metadata) that speaks to governance, business, and technical guidelines associated with specific data tables, serving as a single source of truth for all consumers.
With data observability, you can monitor changes in the provenance, integrity, and availability of your organization’s data, leading to more collaborative teams and happier stakeholders.
Data Discovery
Data discovery posits that different data owners are held accountable for their data as products, as well as for facilitating communication between distributed data across different locations. Once data has been served to and transformed by a given domain, the domain data owners can leverage the data for their operational or analytic needs.
Data discovery replaces the need for a traditional data governance platform by providing a domain-specific, dynamic understanding of your data based on how it’s being ingested, stored, aggregated, and used by a set of specific consumers. Governance standards and tooling are federated across these domains (allowing for greater accessibility and interoperability), a real-time understanding of the data’s current (as opposed to ideal) state is made easily available.
Data discovery can answer these questions not just for the data’s ideal state but for the current state of the data across each domain:
- What data set is most recent? Which data sets can be deprecated?
- When was the last time this table was updated?
- What is the meaning of a given field in my domain?
- Who has access to this data? When was the last time this data was used? By who?
- What are the upstream and downstream dependencies of this data?
- Is this production-quality data?
- What data matters for my domain’s business requirements?
- What are my assumptions about this data, and are they being met?
Security and access
While modern data stack tools open up additional capabilities for working with data, they must also be protected and appropriately managed to ensure that only the people that should have access to data are using it.
To start the New Year on a more secure foot, we suggest data engineering teams partner with their security and legal counterparts to conduct a cross-organizational “data audit.”
According to Atul Gupte, former Data Product Manager at Uber, the first job for any data leader is to audit the data that you’re collecting and storing, as well as who has access to this data (they referred to it as their “Data Blast Radius”).
In 2022, most businesses will rely on a combination of enterprise-level transactional data residing in traditional data warehouse systems, event streaming, and other data platform capabilities, including your company’s operations strategy. Both requirements emphasize the need for a robust and automated approach to policy enforcement that prioritizes PII identification and access control to capture the meaning, location, usage patterns, and owners of your data.
Turn and face the change
At the end of the day, solving for data governance extends beyond implementing the right technologies. Achieving equitable data access and end-to-end trust relies on building better processes, too. After all, it doesn’t matter what’s in your data stack if the data itself can’t be found, trusted, or secured.
It’s time we adopted a new culture that prioritizes these three sides of data governance’s new face – and in the process, gives data teams the ability to empower data democratization and better decision making across the business.
Data governance doesn’t need to be a hassle – it just needs to meet data teams where they are.
Interested in learning more about the new face of data governance? Send a note to Louise or Molly.
Curious about how data observability fits into your governance strategy? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.