Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 5 Steps To A Successful Data Warehouse Migration

Saba El-Hilo
Saba is the vice president of engineering at Unbounce.
Platform and data warehouse migrations aren’t something you do everyday or even every few years, but they’re becoming much more frequent as organizations seek to modernize their data infrastructure with the new capabilities being offered by Snowflake, Databricks, Google, AWS, and others.
[Editor’s note: We agree. Cloud database migrations were listed in our latest ebook The 22 Hottest Trends In Data Right Now]
Migrations are like Schrodinger’s cat. They’re either an amazing opportunity to create a new debt-free environment and help the business better understand your team’s value…or the cat could be dead. And you won’t know which it will be until you’ve “lifted the box” and launched your data warehouse migration.
I’ve recently been involved with two major data related migrations consisting of terabytes and billions of data points per day. The organizations and the target/source systems were different—the first was a Qubole data platform to AWS EMR and Athena migration at Mapbox, the second which is currently ongoing at Unbounce is a MySQL to AWS Redshift—but the process and best practices were remarkably similar.
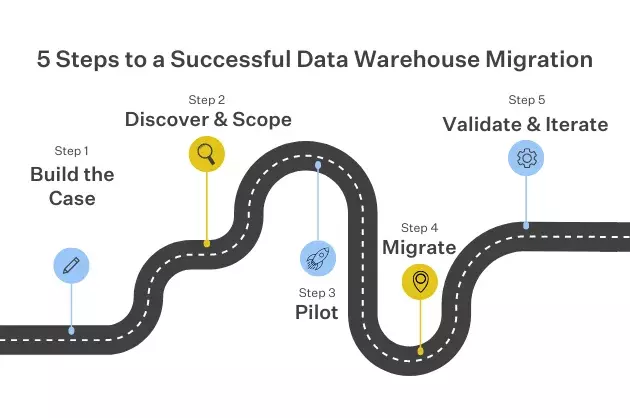
In this post, I’ll cover the 5 steps I use to conduct a successful cloud warehouse migration, including:
- Step 1: Build your business case
- Step 2: Discovery and scoping
- Step 3: Launch a pilot
- Step 4: The migration
- Step 5: Validate and iterate
Step 1: Build your business case

The greatest threat to any large scale project, but especially data warehouse migrations, is inertia. These projects take time, introduce risk, and require change management for impacted users. Not exactly a trifecta to make the C-suite swoon.
Which is why your business case can’t be about the cool new features in the target system. It needs to include expected savings across both hard infrastructure costs as well as softer costs from inefficiencies. It should also go into tangible detail around the limitations of the source system. Be sure to list the number of outages, hours to repair, unsatisfied customers, and anything else that shows that the real risk isn’t the migration, it’s the status quo.
For the decision to migrate from Qubole’s data platform to AWS services, we focused on many of those metrics, as well as our ace in the hole—security and downtime. When the source system isn’t updating its versions quickly enough, that opens our system up to security vulnerabilities that help justify a migration.
Of course, it doesn’t hurt to extol the benefits your organization will realize from the new environment as well. Getting the rest of the engineering team excited about the benefits is a great motivator and way to find project champions. At Unbounce, one of the biggest drivers for migrating to Redshift was helping our team better support business-driven decisions by making it easier to build dashboards and faster to query the data from one consolidated data warehouse.
Step 2: Discovery and scoping

This is the most important step of a migration and the most determinant of success. The conventional wisdom is that the scoping process is to determine the key requirements and tasks that will be within the purview of the project.
In my experience, it’s just as important to list out what WON’T be done during the first phase of the migration as what will be. This prevents over-promising during scoping and keeps stakeholder expectations aligned throughout the process.
Listing exclusions is also important because it prevents the dreaded “scope creep” that so often befalls data warehouse migration projects. Scope creep is real and it can kill a migration. What inevitably occurs is that as you begin to migrate each domain, you start to uncover hidden tripwires that threaten to blow your timeline up. These could be questionable data sources, bespoke data pipelines, critical documentation, or one off workflows that need to be refactored.
Scope creep can even come from within the migration team itself. When you’re moving to a new data environment, the world is your oyster. But for the sake of your timeline, it’s important to draw a line in the sand: phase one is strictly about reaching feature parity with the source system. Save the exploring of new possibilities for phase two.
Even with feature parity as the north star, depending on the size of your data and complexity of the data processing pipelines you could be looking at a multi-month, maybe even multi-quarter project for phase one—which is a lifetime in tech years.
That doesn’t mean you have to architect everything in your target system like you did in your source system. In fact, what separates a good data warehouse migration from a great migration is when teams use the data migration as a type of data audit. Especially when you’re migrating Spark jobs or ETL workflows, there are ample opportunities to clean things up that shouldn’t be there or weren’t done properly. Don’t just point jobs from platform A to platform B, take a minute to examine and re-orchestrate as needed (or maybe it’s not even needed at all!).
There are many tools that can help with data discovery. However, at some point you’re going to need to talk with someone who’s close to that domain’s data. The best discovery processes start rather than end up there. Make a checklist of everyone you need to interview and ask them about data owners, workflows, dependencies, governance, and daily operations.
Step 3: Launch a pilot

Most large scale platform and data warehouse migrations have too much complexity to skip a shakedown cruise. The goal of a good pilot is to create a templated experience that can be rolled out and scaled across multiple departments so you can move faster. This is especially important if a migration will affect multiple teams across the organization. At Mapbox, our migration from Qubole to EMR and Athena affected every single product team as all their data processing workflows and ingestion patterns were affected.
To get started, pick the team that’s most willing to work with you and provide feedback for the data warehouse migration. Join their standups, understand the unique way they interact with data, and use the experience to abstract the process and tooling you’ll be providing to other teams. This helps determine what you need as part of your standard “migration kit.” This could include FAQs, custom tooling, common libraries or data schemas.
The added benefit of a good pilot is that you’ve just created a set of advocates who can evangelize the benefits of the new system and share their positive experiences. This can help move tech laggards and skeptics into more willing adopters.
Step 4: The migration

Ironically, if you’ve done your job during discovery and the pilot, the actual moving of data from point A to point B should be the most straightforward part.
Oftentimes the cloud database you are moving to is quite eager and has tools available for you to use. For example, for those interested in moving to Redshift, AWS offers a Schema Conversion Tool to help automate the conversion of source data warehouse schema into those that are compatible with Redshift. There is also the AWS Direct Connect service that serves as a network interconnection between the two environments.
Typically, your data won’t just be moving from source to target. There will be pockets of data outside of the source environment that you wish to consolidate into the new cloud database, which will likely require custom ETL pipelines.
The best migration is the simplest possible. It’d be incredible if you could do your entire migration in one shot, though not always realistic. If you have a large amount of data with a high change rate, you may need to set up multiple waves with subsequent incremental migrations or a CDC to catch any changes and regressions introduced by the migration early.
For migrations handling data at the petabyte scale with multiple teams involved, a multi-wave migration is the most likely scenario. Migrate at non-peak hours to save cost and to avoid any possible business disruptions.
And don’t just communicate during the data warehouse migration—over communicate. Remember, this was a big ask you made of the organization and there are a wide range of stakeholders invested in its success.
Step 5: Validate and iterate

Once the migrations are complete, it usually makes sense to run both environments concurrently while you validate that everything has moved as it should and there are no issues with your pipelines. Investing in automated end to end testing frameworks and data quality metrics to monitor goes a long way!
[Editor’s note: During your data warehouse migration, data observability‘s data monitoring and data lineage features can help with this.]
Following validation, you may want to survey stakeholders to assess and report their level of satisfaction with the new environment and the migration process. Finally, once feature parity with the old environment has been reached and trust in the new environment has been established, it’s time to set your data engineers loose on all of those new projects. Have fun and good luck with your data warehouse migration!
Interested in learning about how data lineage and data observability can help you during your data warehouse migration and beyond? Schedule a time to talk with one of our experts by filling out the form below!
Our promise: we will show you the product.
Read more posts.