 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Top 5 Open Source Data Lineage Tools (With User Reviews)


Michael Segner
Michael writes about data engineering, data quality, and data teams.
Data lineage tools are like detectives that help data professionals quickly sort through the tangled webs of interdependencies that make up the modern data stack.
Whether you’re a data scientist, data engineer, or business analyst, keeping track of your data’s origin, transformation, and movement is crucial for maintaining transparency, enforcing data governance, and ensuring data quality.
Just like Sherlock Holmes relied on his trusty magnifying glass to uncover hidden details, you too need powerful data lineage capabilities to get a better understanding of your data environment.
The first instinct of many early stage companies or budget strapped data teams is to turn to open source data lineage tools. While there are several affordable tools that we evaluate and compare below, what you will see is that their implementation and maintenance is anything but “elementary.”
Depending on your requirements (more on that in the next section), it is prudent to evaluate open source data lineage tools alongside the several other types of platforms that provide data lineage capabilities. You may even already have access to one of them.
Data lineage tools help you uncover and map the complex relationships between data elements across various sources, systems, and processes. By understanding your data’s lineage, you can ensure data accuracy, enhance data governance, meet regulatory compliance requirements, and improve decision-making.
This guide will serve as a handy resource to help you navigate the various open source data lineage tools out there, along with discussion on the pros and cons of open source, and how to select the right tool for your specific needs.
Table of Contents
Pros and Cons of Open Source Data Lineage Tools
The choice between open source and proprietary is a matter of assessing your organization’s specific needs, resources, and future goals. We’ve written extensively on how to analyze the build vs buy decision across the modern data stack, but it’s important to speak specifically about open source data lineage options.
The reality is data lineage is incredibly complex to build as well as maintain, and as a result there aren’t many strong open source options that will address most organizations’ needs. There are a few reasons for this, but it’s mainly because data lineage involves so many layers–system, code, users– that are constantly evolving.
We know this because Monte Carlo was (and still is) on the forefront of developing data lineage for the modern data stack as one of the five pillars of data observability. We’ve been open about this work, providing very technical deep dives into how we developed column-level lineage and even some of our failures in building Spark data lineage for data lakes.
The Spark data lake lineage example is helpful for context here. Our team attempted to leverage Spline (one of the open source data lineage tools listed here) as a building block. That version of the project ultimately didn’t succeed because Spark commands are constantly evolving and the Spline open source community ultimately can’t keep up. Instead, we more closely integrated with Databricks Unity Catalog.
Another consideration for these tools are the integration points across the data pipeline. A question to ask is how will these data lineage source solutions account for dbt models, Fivetran connectors, and their relationship to tables? If our organization decided to pack up and migrate from one table format or data warehouse to another, would all the work we put into maintaining our open source data lineage solution for naught?
Finally, it’s important to consider first principles. Why do you need data lineage? Is it mainly a governance use case, a discovery/self-service use case, data quality use case, or all of the above?
For light data governance use cases you may already be on platforms such as Databricks or Google BigQuerywhich provide data catalog options that will suffice such as Unity Catalog and Dataplex respectively.
However, if there are any data quality requirements or desired data lineage use cases then you will want to consider a data observability platform. This is because data lineage, incident detection, and resolution capabilities need to be within a unified platform to enjoy accelerated resolution, incident triage, and other benefits.
“I understand the instinct to turn to open source, but I actually have a lower cost of ownership with a tool like Monte Carlo because the management burden is so low and the ecosystem works so well together. After one phone call with the Monte Carlo team, we were connected to our data warehouse, and we had data observability a week later,” said Adam Woods, CEO, Choozle. “I love that with Snowflake and Monte Carlo my data stack is always up-to-date and I never have to apply a patch. We are able to reinvest the time developers and database analysts would have spent worrying about updates and infrastructure into building exceptional customer experiences.”
Ok, that is enough caveat emptor. To summarize, if feasible, evaluate the open source data lineage tools below alongside other options to see what works best for you.
OpenMetadata
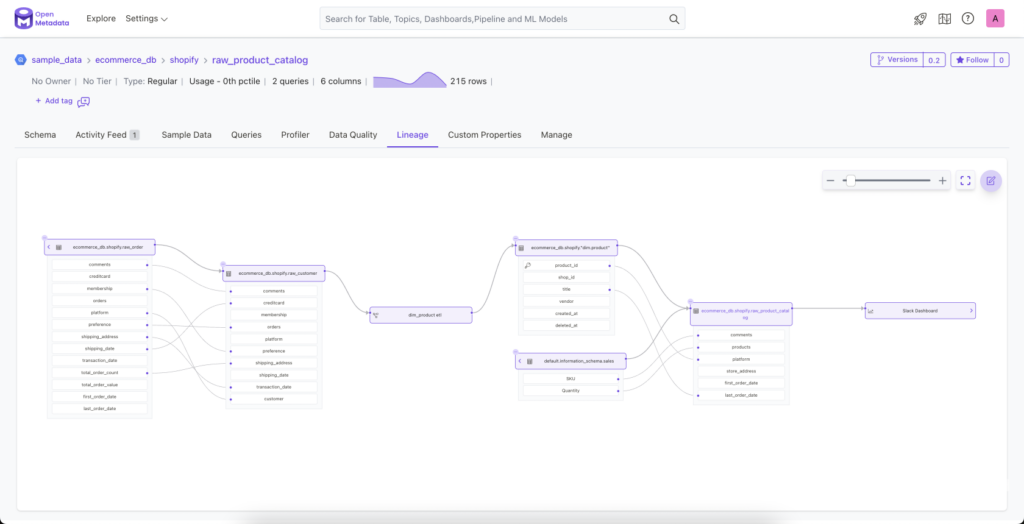
OpenMetadata is an open-source data lineage tool with several stand out features:
- Column-level Lineage: Data transformations and dependencies can be traced down to the individual column level, enabling an incredibly granular view of data lineage.
- Query Filtering: You can isolate and focus on specific segments of data lineage using filters, facilitating better analysis and understanding.
- No-code Editor: It’s possible to augment the lineage captured from machine metadata with a drag and drop no-code editor. Tables, pipelines, and dashboards can be manually added, modified or removed on the lineage graph for a richer and more detailed understanding of the provenance of data.
- dbt Integration: This integration unveils the models used to generate tables. While data lineage broadly indicates where a table’s data came from, the dbt model provides more specific details about the transformations involved.
In short, OpenMetadata provides a balance of simplicity and detail, making it accessible for users without coding knowledge while still providing the granularity needed by data professionals to understand complex data transformations.
One reviewer said, “I’m in the process of setting up OpenMetadata in our org, ingesting metadata from Athena, Superset and Dagster. Setting up a local env barely took a few minutes, the documentation is pretty good. Had a few hiccups configuring ingestion but got it working after a few small fixes/workarounds in their Python code, but you’ll probably have an easier time if using more popular metadata sources.”
OpenLineage + Marquez
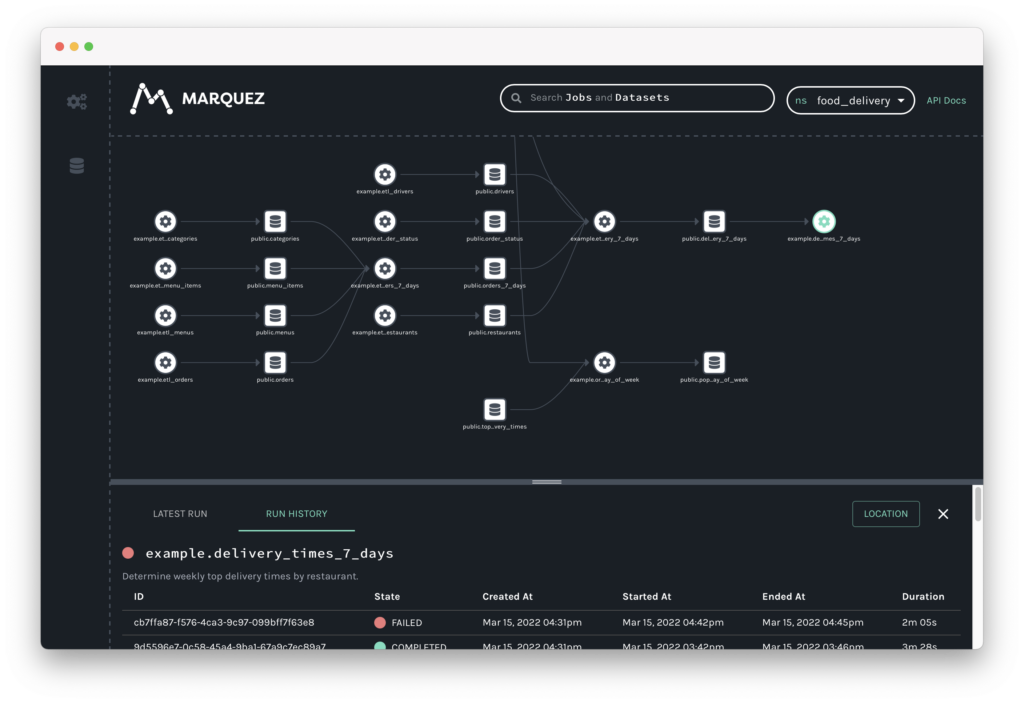
Technically, OpenLineage isn’t a tool. Rather it’s an open standard for metadata and data lineage collection. The actual collecting, aggregating and visualizing of metadata to construct data lineage is done by any tool that adheres to this standard. OpenLineage’s docs reference the open-source tool Marquez to do this.
Marquez offers a slick, dark web UI that’s easy to understand (although not drag-and-drop) and provides a robust API that can be integrated with a multitude of data sources and tools, allowing for automation of key tasks like backfills and root cause analysis. Moreover, Marquez has a rich set of features enabling metadata management, offering more than just data lineage tracking.
One reviewer in late 2022 said this about OpenLineage, “Column-level lineage in OpenLineage is in its early days. There’s support in the spec for it, and the integration with Spark currently emits column-level metadata.”
In their TechnologyRadar report, Thoughtworks says, “Although there is a risk of it being another “standard in the middle,” being a Linux Foundation AI & Data Foundation project increases its chances of gaining widespread adoption. OpenLineage currently supports data collection for multiple platforms, such as Spark, Airflow and dbt, although users need to configure its listeners. Support for OpenLineage data consumers is more limited at this time.”
Egeria
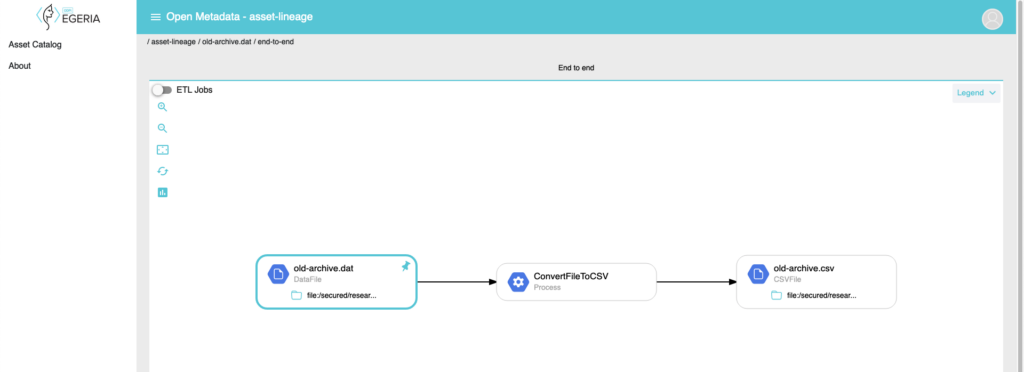
Egeria is also not a tool but rather provides open APIs, event formats, types, and integration logic enabling metadata exchange and governance in organizations. These features make it useful for managing data lineage.
Like Marquez, Egeria relies upon the OpenLineage standard for data lineage, but Egeria’s interface is not as slick. “These user interfaces are experimental and under constant development”, they say.
Apache Atlas
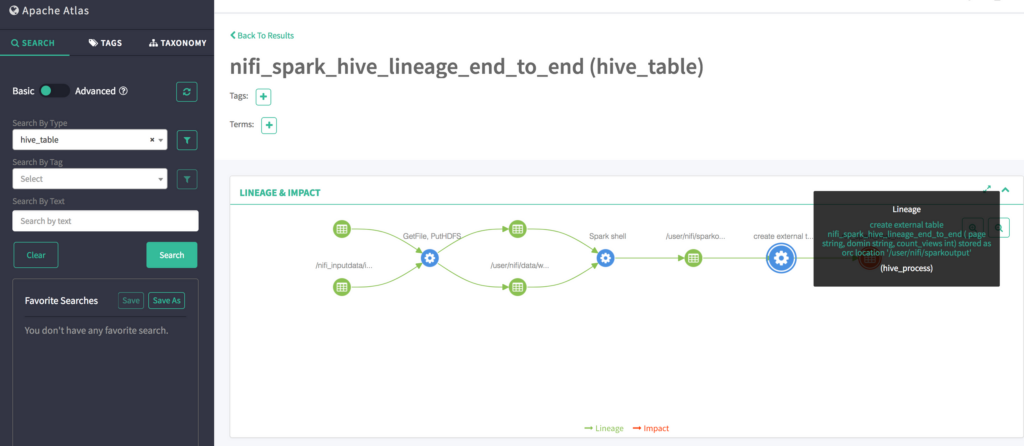
Apache Atlas bills itself as an open-source metadata management and governance tool, but it can also be used to track and manage data lineage. Atlas’ UI allows you to view the lineage of data as it moves through various processes and there is a set of REST APIs that allow you to access and update data lineage information.
Atlas supports the OpenLineage standard too, making it easy to share data lineage information in a format that is compatible with other tools that support OpenLineage.
While receiving generally positive reviews, many users point to some common downsides seen across open source data lineage tools including responsiveness and long time to value.
“It’s a good product…but the response time and performance can be improved,” said one reviewer.
“The initial setup and learning curve required to leverage the full potential of the solution is something that is a big blocker to getting started. Requires significant time [and] resources to set it up,” said another.
Spline
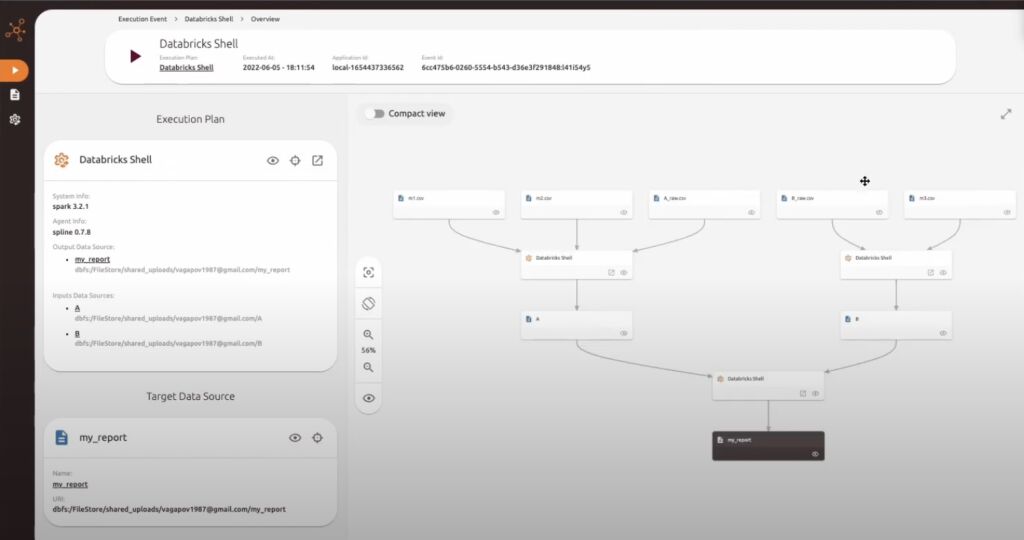
Spline was originally designed for Apache Spark but the project has expanded to accommodate data lineage for other data sources as well. Spline has APIs for both collecting and querying data lineage data, supports OpenLineage integration, provides a web UI to display the stored lineage information, and you can view lineage in different levels of detail (e.g. data source level, operation level, computation level, etc.). Spline is a set of modules that can be used together or alone.
“I have used Spline, it works well with Spark,” said one user.
“…The documentation concerning the inputs, outputs, and movements of the data used in the model is lacking,” said another.
The Game’s Afoot
In conclusion, open source data lineage tools can be an evaluation option for early-stage companies looking to maintain transparency and ensure data quality.
However, they should be evaluated alongside other data lineage solutions such as data catalogs and data observability solutions depending on your desired use cases. Did we miss an open source data lineage tool? Tell us in the comments.
Interested to understand how data observability can improve your data lineage reporting? Schedule a time to speak with us using the form below!
Our promise: we will show you the product.
Read more posts.





