Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Contracts: Silver Bullet or False Panacea? 3 Open Questions


Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
Shane Murray contributed to this article.
My co-founder has been all-in on data contracts from the start.
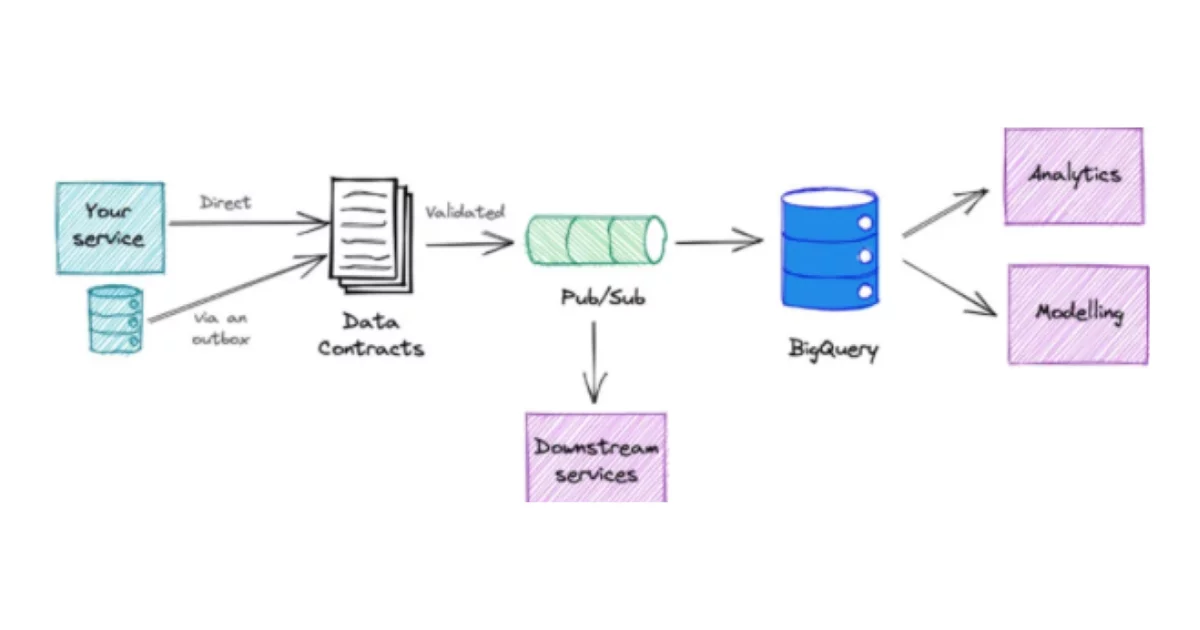
For those unfamiliar with the hottest emerging data engineering concept of 2022, data contracts are designed not just to fix, but prevent data quality issues that arise from unexpected schema changes and data swamps.
We wrote an introduction guide with more detail, but essentially data contracts involve working with data consumers to develop the schema and semantic requirements for production grade data pipelines and then delivering that data pre-modeled to the data warehouse.
In Barr’s view, this new data quality paradigm helps data engineering teams better align with the business by bringing data consumer requirements front and center. She places tremendous weight on the voice of the customer.
I don’t think she is wrong, but for me, a past and present software engineer, there are three open questions that still need to be answered to determine if data contracts will be a silver bullet or a false panacea.
Table of Contents
- Question #1: Can you find the right balance of incentives?
- Question #2: Can you get people to slow down?
- Question #3: Can data consumers accurately predict and express their requirements?
- Ultimately, I’m cautiously optimistic for the future of data contracts
Question #1: Can you find the right balance of incentives?
Incentives drive human behavior. Heavy handed top down mandates can work as well, but enforcing unnatural behavior always comes with a high cost to morale, efficiency, and executive focus.
It’s much more effective to have an answer to the age-old question, “what’s in it for me?”
The answer is pretty apparent for data engineers who would no longer need to scramble every time an unexpected schema change ruptures a key data pipeline. For other members of the data team–the power data consumers in data science and analysis roles–the advantages of higher quality data in a better organized data warehouse are also clear.
But what’s in it for those owning and managing the services producing the data? The software engineers? The Salesforce admins? In most organizations today not only are the incentives not aligned, but there are massive organizational silos and disparate reporting structures.
Data engineering and software engineering teams are almost always isolated from one another, and the reality is too often data (and data engineering) is a second class citizen. This is because traditionally data was solely leveraged for BI tools, done offline, and didn’t drive the business, at least not to the same extent.
In other words, the software engineering team has all the power and none of the incentives to adopt data contracts as yet another addition to their already crowded workflow.
Remember, they are already the “beneficiaries” of other initiatives we’ve shifted left such as cybersecurity and governance. I can speak from experience that additional red-tape workflows and approval steps outside of our area of expertise and KPIs are not popular.
In the experience of my colleague and former New York Times data senior VP Shane Murray, “With any shift-left initiative (e.g. privacy / GDPR), we needed to demonstrate why it’s valuable over and above the rest of the software engineering teams’ priorities, and we need to provide the tools to make it easy, including feedback loops that show they are getting it right as well as saving time and effort.”
Possible Answer: Technology & Process
This inherent friction may be exactly what a data contract platform could be built to solve. Technology and process are not an incentive in of itself, but it can facilitate them.
For example, GoCardless leverages technology and CI/CD processes to provide its data producers increased autonomy (automatically spinning up infrastructure and other needed resources) within its data contract system. Automation lowers barriers, accelerates workflows, and enforces policies.
Question #2: Can you get people to slow down?
When a schema change is required, someone has to slow down.
Either it’s the data producer who must wait for the appropriate updates to be made to downstream data systems or it’s the data engineering team that must fix a broken pipeline after the change has been made.
The inherent assumption within a data contract system is that the former is more valuable (or perhaps less painful) than the latter. The reality is this will depend on the cost of the data downtime from breaking schema changes compared to the cost of delaying operations related to incorporating the new schema.
You could even create a loose equation for it:

You probably don’t care about a breaking schema change if it means taking a seldom used dashboard down for a few minutes, but you probably care a lot if it will create major issues in your customer facing application.
But as much as we would love to solve this with clear examples and cold hard math, the real world tends to exist on a fuzzier spectrum.
Let’s paint a hypothetical scenario in which a data contract architecture works exactly as intended. The Sales Kickoff is coming up next week and the CRO and CFO need the sales ops team to make heavy modifications to how Salesforce is organized in order to demonstrate their revolutionary new go-to-market strategy.
They need it ASAP. The salesops team checks or gets notified that their changes are going to break schemas populating dashboards that support AEs in the northwest region. Do they stop what they are doing? Would the organization want them to pause? Maybe. Maybe not.
Again, you can see how technology could reduce the amount of time required to prepare data systems for a new schema change. However, data contracts aren’t just schema registries, they define semantics as well.
With all respect to our future supreme ruler GPT-3, creating and updating the business logic, meaning, and purpose is still largely a human bottleneck. This has been one of the primary obstacles to data catalog adoption for years.
Possible Answer: Data gets promoted
There is the carrot and then there is the stick. No one wants to be the one who pushes bad code and breaks production. That same urgency isn’t present for a service update that might take a dashboard offline for a few hours.
As data systems move more and more toward operational use cases–for instance re-accommodating stranded passengers to cite an example from the travel industry–that will change as data becomes a first-class citizen.
“I’ve seen data teams get software engineers to care about data quality – usually in smaller, cross-functional teams – by creating awareness of the downstream uses of data,” said Shane. “But scaling this to ~50 product teams contributing to the same event schema? That’s very much an open question.”
Possible Answer: Pick your battles
“There’s a principle in site reliability engineering to avoid pursuing more reliability than what is strictly necessary, and you can see how that principle applies with data contracts,” said Shane.
“If the data product is critical to the business operations or product experience, then the quality of data emitted becomes as important (or more so) than other features and the contract is paramount. Examples here would be financial reporting and some (but maybe not all) production machine learning applications,” he continued. “If data is a secondary benefit, it’s not always practical to stand in the way of a product launch. Getting visibility into the change such that you can adapt downstream pipelines may be the more viable approach.”
Question #3: Can data consumers accurately predict and express their requirements?
This is perhaps my biggest reservation and open question. If you squint, you can see how data contracts are another form of data testing.
One of the biggest paradigm shifts of data observability, and the reason it has resonated with so many data engineering teams, is the inability of humans to define what data should look like and anticipate how it will behave (the unknown unknowns problem).
Data testing remains an important component of the data reliability stack, but even if we could anticipate every type of test we need, they are impossible to scale effectively. This is a task much better suited to machine learning monitors.
So if data professionals struggle to maintain data tests and document the semantics of data assets, can we expect data consumers to succeed? Practical experience at least calls for caution.
“Data analysts/scientists will often manually append new data, interpolate or extrapolate data where missing,” said Shane “Sometimes this was because they can’t get upstream teams to collect this data, but just as often it was unforeseen or is being tested for its value.”
Yes, data consumers will know the data better. Yes, it’s easy to see how technology can bridge any technical deficiencies a business stakeholder may have, but can anyone define and anticipate the forms data will need to take? It’s like trying to define the shape of water or hoping a piece of clothing will be fashionable forever–at best it’s just a moment in time.
Possible Answer: Hope for the best, decouple for reality
Data contracts are useful for dealing with known quantities, where accuracy has a ground truth that can be guaranteed.
The experience at GoCardless has shown that, at least in some cases, data consumers may not need to make modifications to the contract too often. It may be possible to uphold a limited set of expectations for data over a closed period of time. This is especially the case with production pipelines where the data reflects the real world, like the actual number of shipments made, or a crucial customer facing metric that IS the feature.
“There needs to be a spectrum between band-aid solutions (just having data engineers fix breaking schema changes all day) and expecting perfection from data producers,” said Shane. “One way to do this is to build data products that are resilient to upstream changes using techniques like circuit breakers and decoupling production databases from data systems.”
Ultimately, I’m cautiously optimistic for the future of data contracts
An important consideration in this debate is that data contract advocates haven’t been selling snake oil or turning the FUD up to 11. They have developed these solutions organically in response to real challenges their organizations faced.
There are real world implementations that have been successful. These advocates eat their own dog food and are honest about trade-offs. The focus on production grade pipelines and fit within a larger reliability ecosystem reflects a pragmatism that will be essential to success
To go back to the titular question, data contracts will likely fall somewhere in between a silver bullet and a false panacea. But I will say that despite the open questions expressed in this post, I would strongly consider deploying a data contract solution internally within Monte Carlo as our data is essential to our product offering.
That was the realization that ultimately pushed me from data contract skeptic to cautious endorser. I look forward to seeing how these open questions get answered and how this promising new chapter in data quality evolves.
Interested to learn about how data contracts and data observability can work together to improve data quality? Set up a time to talk with us using the form below!
Our promise: we will show you the product.
Read more posts.