 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage A Major Step Forward For Generative AI and Vector Database Observability


Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
Organizations are racing to deploy generative AI applications to unlock new sources of value and stave off potential disruptors as this transformative technology takes hold.
LLMs have quickly become plug-and-play APIs while smaller specialized models are becoming rapidly commoditized as well. To differentiate and expand the usefulness of these models, organizations must augment them with first-party data – typically via a process called RAG (retrieval augmented generation).
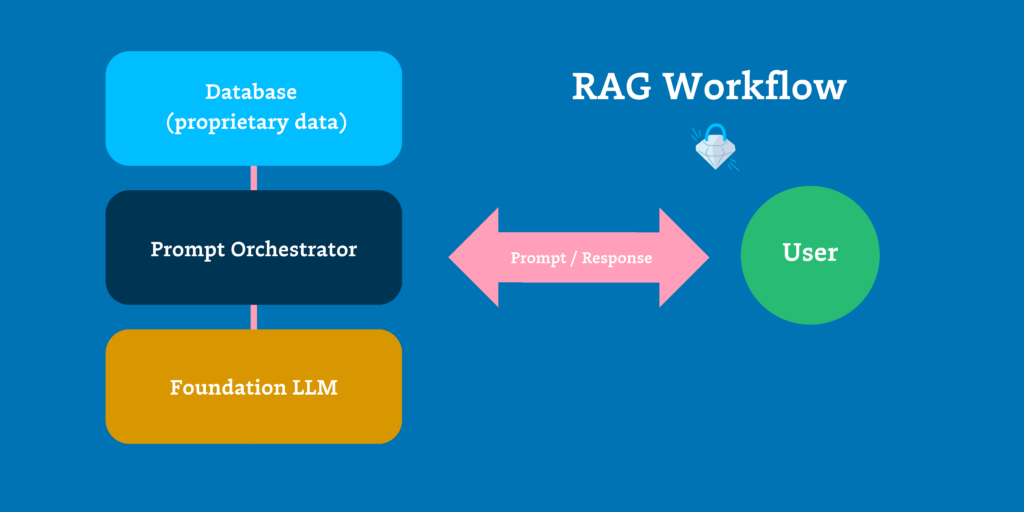
Today, this first-party data mostly lives in two types of data repositories. If it is structured data then it’s often stored in a table within a modern database, data warehouse or lakehouse. If it’s unstructured data, then it’s often stored as a vector in a namespace within a vector database.

Monte Carlo has been the leader in data observability to improve the data reliability of structured and unstructured data processed by modern data platforms built around warehouses, lakes, and lakehouses. The category was introduced with five original pillars:
- Freshness: Did the data arrive when expected?
- Volume: Are there too many rows? Too few?
- Schema: Did the data structure change in ways that will break downstream processes?
- Quality: Is the data itself anomalous? Is the range, NULL rate, uniqueness, and other metrics within historical norms?
- Lineage: A map of how and where data is flowing and changing across your pipelines.
Today, we are thrilled to highlight a major step forward in the evolution of data observability and how Monte Carlo improves the reliability of unstructured data held within vector databases–and specifically Pinecone.
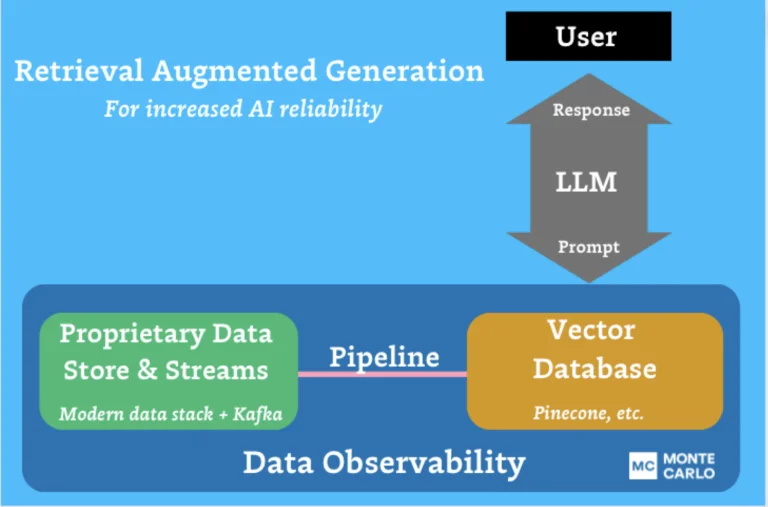
Our Vision for Vector Data Observability
Just like any database, vector databases involve data pipelines that ingest and consume data. Their lineage can be mapped and their health can be measured using the same core pillars of freshness, volume, and schema (metadata).
And just like any other data pipeline, they carry data—vectors—that can be monitored for anomalous behavior indicating problems with its quality.
At Monte Carlo, we’re committed to supporting the (still emerging) Gen AI stack to help our customers understand at-a-glance the health of the data powering their AI models. Our current efforts in this area involve how we can support the five pillars of data observability for vector databases.
Our latest release is that first pillar and a bold step into the future of reliable AI: volume monitors for Pinecone.
How Pinecone volume monitors support reliable AI
A common data reliability challenge for Generative AI and vector databases is that if you’re not actively monitoring the ingestion of indexes into the vector data pipeline, it’s challenging if not impossible to determine whether the proper amount of data has loaded in a given amount of time.
For example, data reliability within Pinecone is key for beta user Worknet and its AI copilot for support teams. Unstructured data from product documentation, Slack chats, internal knowledge repositories, and other sources is uploaded to Pinecone. There it can be accessed by the company’s generative AI application as part of the RAG process. Using Worknet, instead of clicking through pages of documentation or bugging busy product managers, support engineers can quickly ask questions in natural language to understand the latest technical product details.
That is, if the data answering their question actually lands in Pinecone. If the pipeline is disrupted for whatever reason then there is a risk of unavailable or inaccurate information.
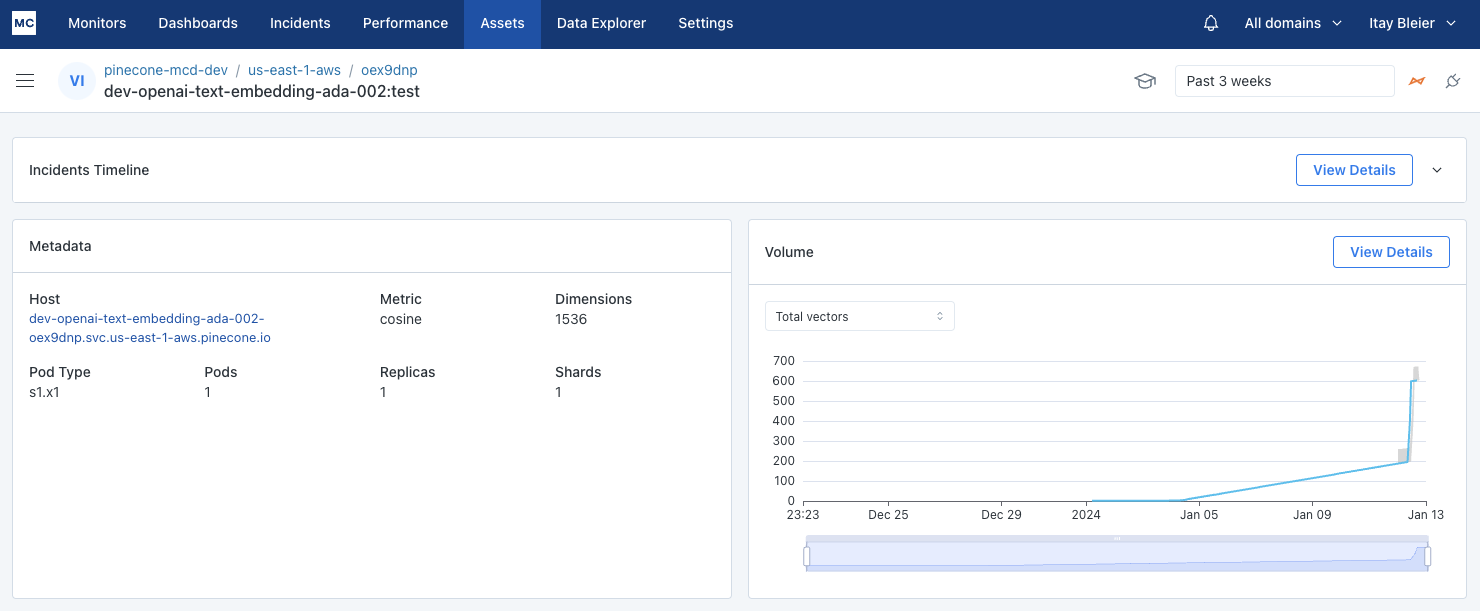
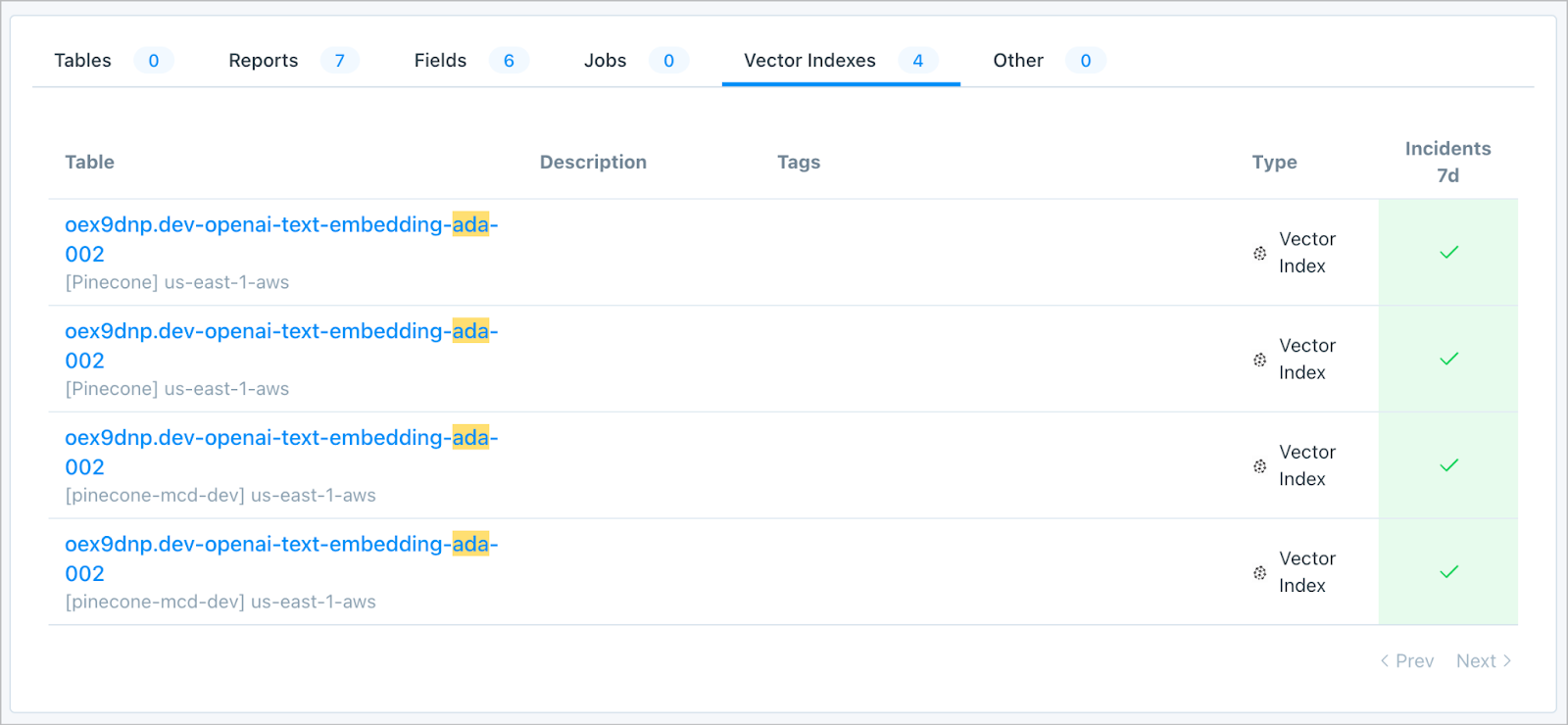
Taking advantage of Pinecone’s functionality that separates vector data into customer-defined categories or ‘Index Namespaces,’ Monte Carlo’s integration will alert Pinecone users when data is missing or duplicated in any of the namespaces within their indices, pinpointing when and where they took place.
As soon as you connect Pinecone, hourly tracking of vector count by each Index and Index Namespace will be collected and actively monitored by Monte Carlo’s machine learning – no other setup necessary.
The Future Is Here
We are excited to work with data teams to take Generative AI from buzzy trend to viable, revenue-driving enterprise technology–and we’re just at the beginning. If this is an area your team is exploring we encourage you to get in touch via the form below.
Our promise: we will show you the product.
Read more posts.





