 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Future of Big Data Analytics & Data Science: 6 Trends of Tomorrow


Michael Segner
Michael writes about data engineering, data quality, and data teams.
The concept of big data – complicated datasets that are too dense for traditional computing setups to deal with – is nothing new. But what is new, or still developing at least, is the extent to which data engineers can manage, data scientists can experiment, and data analysts can analyze this treasure trove of raw business insights.
Thanks to widespread migration to the cloud, new ways of processing data, and advances in AI, we can do more with big data in 2024 than ever before. However, with the rapid rate in which data is being produced and aggregated across the enterprise, will our analytical capabilities scale fast enough to provide valuable insights in time?
We’ve previously discussed the need for quality over quantity when it comes to big data and, in this article, we’ll be looking at how recent technological innovations and new processes across 4 of the 5 ‘V’s of big data (volume, velocity, veracity, variety) are changing the future of big data analytics.
Table of Contents
The increasing velocity of big data analytics
The days of exporting data weekly, or monthly, then sitting down to analyze it are long gone. In the future, big data analytics will increasingly focus on data freshness with the ultimate goal of real-time analysis, enabling better-informed decisions and increased competitiveness.
Streaming data, as opposed to processing it in batches, is essential for gaining real-time insight, but has implications when it comes to maintaining data quality – fresher data can mean a higher risk of acting on inaccurate or incomplete data (which can be be addressed using the principles of data observability).
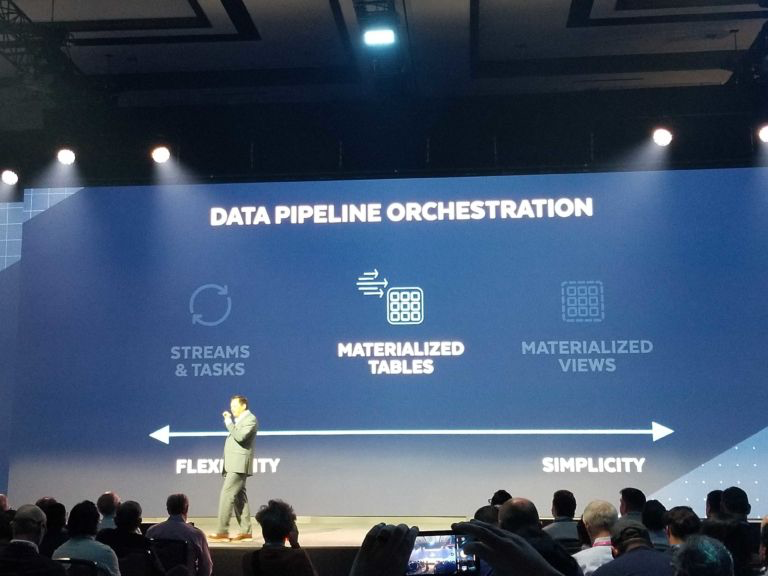
Snowflake, for example, announced Snowpipe streaming at this year’s summit. The company has refactored their Kafka connector and made it so that when data lands in Snowflake it is queryable immediately resulting in a 10x lower latency.
Google recently announced that PubSub can directly stream into BigQuery as well as the launch of Dataflow Prime, an upgraded version of their managed streaming analytics service.
On the data lake side, Databricks has launched Unity Catalog to help bring more metadata, structure, and governance to data assets.
Real-time data/insights
Being able to access real-time data for analysis might sound like overkill to some, but that’s just no longer the case. Imagine trading Bitcoin based on what it was worth last week or writing your tweets based on what was trending a month ago.
Real-time insight has already shaken up industries like finance and social media, but its implications beyond them are huge: Walmart, for example, has built what may be the world’s largest hybrid cloud to, among other things, manage their supply chains and analyze sales in real time.
Real-time, automated decision making
Machine learning (ML) and artificial intelligence (AI) are already being successfully employed in industries like healthcare, for detection and diagnosis, and manufacturing, where intelligent systems track wear and tear on parts. When a part is close to failure, the system might automatically reroute the assembly line elsewhere until it can be fixed.
That’s a practical example, but there are all sorts of applications beyond this: email marketing software that can diagnose the winner of an A/B test and apply it to other emails, for example, or analysis of customer data to determine loan eligibility. Of course, businesses that don’t yet feel comfortable fully automating decisions can always retain a final step of manual approval.
The heightened veracity of big data analytics
The more data we collect, the more difficult it is to ensure it’s accuracy and quality. To read more about this, check out our recent post on the future of data management, but for now, let’s get into trends surrounding the veracity of big data analytics.
Data quality
Making data-driven decisions is always a sensible business move…unless those decisions are based on bad data. And data that’s incomplete, invalid, inaccurate, or fails to take context into account is bad data. Fortunately, many data analytics tools are now capable of identifying and drawing attention to data that seems out of place.
It’s always best, of course, to diagnose a problem rather than treating the symptom. Instead of just relying on tools to identify bad data in the dashboard, businesses need to be scrutinizing their pipelines from end to end. Figuring out the right source(s) to draw data from for a given use case, how it’s analyzed, who is using it, and so on, will result in healthier data overall and should reduce issues of data downtime.
Data observability
There’s more to observability than just monitoring and alerting you to broken pipelines,. An understanding of the five pillars of data observability – data freshness, schema, volume, distribution, and lineage – is the first step for businesses looking to get a handle on the health of their data and improve its overall quality.

Beyond that, a data observability platform like Monte Carlo can automate monitoring, alerting, lineage, and triaging to highlight data quality and discoverability issues (and potential issues). The ultimate goal here is to eliminate bad data altogether and prevent it from recurring.
Data governance
With the volumes of data we’re talking about here, taking proper protective measures becomes even more important. Compliance with measures like the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) is vital to avoid fines, but there’s also the issue of how damaging data breaches can be to a company’s brand and reputation.
We’ve previously written about data discovery – real-time insights about data across domains, while abiding by a central set of governance standards – but it’s worth bringing up again here.
Creating and implementing a data certification program is one way to ensure that all departments within a business work only using data that conforms to appropriate and agreed upon standards. Beyond that, data catalogs can be used to outline how stakeholders can (and can’t) use data.
Storage and analytics platforms are handling larger volumes of data
By using cloud technology, things like storage availability and processing power can be virtually infinite. Businesses no longer need to worry about buying physical storage or extra machines, because they can use the cloud to scale to whatever level they need at that moment.
Beyond that, cloud data processing means that multiple stakeholders can access the same data at the same time without experiencing slowdown or roadblocks. It also means that, as long as the right security measures are in place, up to the minute data can be accessed at any time and from anywhere.
The current status quo for this is data warehousing, with most notable providers – Snowflake, Redshift, BigQuery – operating in the cloud. Elsewhere, Databricks and their “data lakehouse” combine elements of data warehouses and data lakes.
But the primary aim remains the same: data, analysis, and potentially AI, in one (or just a few) places. Of course, more data also means a pressing need for more/better ways to handle, organize, and display these large data sets in a way that’s easily digestible.
Keenly aware of that need, modern business intelligence tools (Tableau, Domo, Zoho Analytics, etc.) are increasingly prioritizing the importance of dashboarding to more easily manage and track large volumes of information to enable data-driven decisions.
Processing data variety is easier
With larger volumes of data comes, typically, more disparate sources of data. Managing all these different formats, along with obtaining any sort of consistency, is virtually impossible to do manually…unless you have a very large team that’s fond of thankless tasks.
Tools like Fivetran come equipped with 160+ data source connectors, from marketing analytics to finance and ops analytics. Data can be pulled from hundreds of sources, and prebuilt (or custom) transformations applied, to create reliable data pipelines.
Similarly, Snowflake has partnered with services like Qubole (a cloud big data-as-a-service company) to build ML and AI capabilities into their data platform: with the right training data, ‘X’ data being imported will result in ‘Y’ happening within Snowflake.
Fortunately, the emphasis in big data analytics is currently very much on finding ways to collate data from different sources and find ways to use it together rather than trying to force consistency before data is loaded where it needs to be.
Democratization and decentralization of data
For many years, business analysts and executives have had to turn to in-house data scientists when they needed to extract and analyze data. Things are very different in 2022, with services and tools that enable non-technical audiences to engage with data.
We’re seeing more emphasis on analytics engineering, with tools like dbt focused on “modeling data in a way that empower end users to answer their own questions.” In other words, enabling stakeholders rather than analyzing or modeling projections for them.
Plus, there’s lots of talk about a more visual approach – modern business intelligence tools like Tableau, Mode, and Looker all talk about visual exploration, dashboards, and best practices on their websites. The movement to democratize data is well and truly underway.
No-code solutions
As their name suggests, no-code tools rework an existing process to take away any coding knowledge that may previously have been required. On the consumer side we’ve seen products like Squarespace and Webflow do exactly that, but tools like Obviously AI are shaking up the big data analytics space in a similar way.
The biggest advantage of no-code (and low code) tools is that they enable stakeholders to get to grips with data without having to pester the data team. This not only frees up data scientists to work on more intensive activities, but also encourages data-driven decisions throughout the company because engaging with data is something that everyone is now capable of.
Microservices / data marketplaces
The use of microservices architecture breaks down monolithic applications into smaller, independently deployable services. In addition to simplifying deployment of these services, it also makes it easier to extract relevant information from them. This data can be remixed and reassembled to generate or map out different scenarios as needed.
That can also be useful for identifying a gap (or gaps) in the data you’re trying to work with. Once you’ve done that, you can use a data marketplace to fill in those gaps, or augment the information you’ve already collected, so you can get back to making data-driven decisions.
Data mesh
The aim of using a data mesh is to break down a monolithic data lake, decentralizing core components into distributed data products that can be owned independently by cross-functional teams.
By empowering these teams to maintain and analyze their own data, they get control over information relevant to their area of the business. Data is no longer the exclusive property of one specific team, but something that everyone contributes value to.
Leveraging GenAI and RAG
We’re entering a transformative era in big data analytics as two emerging trends – generative AI (GenAI) and retrieval-augmented generation (RAG) – gain traction.
GenAI is particularly exciting. It pushes the boundaries of traditional data analysis, allowing us to generate synthetic datasets and automate content creation. This innovation opens up new avenues for predictive analytics and data visualization, which were previously limited by the scale and scope of manually gathered datasets. As data engineers, our role is evolving from merely managing data flows to actively participating in the generation of data that can provide deeper insights and foster innovation in various business domains.
RAG, on the other hand, presents a unique challenge and opportunity. It enhances the AI models by augmenting them with real-time data retrieval, ensuring that the insights generated are not only accurate but also contextually relevant. The integration of RAG into our data systems requires a sophisticated understanding of how to efficiently orchestrate data flows and ensure the seamless retrieval of relevant information. This necessitates an advanced skill set in data pipeline architecture, focusing on agility and accuracy, to support the dynamic nature of RAG-enabled systems.
Be ready for the future of big data analytics
While many large companies are already edging closer to, if not already fully embracing, all of these trends, giving them an edge over their competitors, the future of big data analytics is no longer locked behind a wall of price barriers.
Data engineers and scientists are developing innovative ways to uncover insights hidden beneath the heap of data without requiring the budget of a Fortune 500.
We’re going to see a lot more small and mid-size companies incorporating big data analytics into their business strategies.
The future is bright for those who take action to understand and embrace it.
To learn more about how data observability – and other trends in the analytics space – can level up your business, schedule time with the form below.
Our promise: we will show you the product.
Read more posts.





