Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 5 Things Every Data Engineer Needs to Know About Data Observability


Jesse Anderson

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
As a new or aspiring data engineer, there are some essential technologies and frameworks you should know. How to build a data pipeline? Check. How to clean, transform, and model your data? Check. How to prevent broken data workflows before you get that frantic call from your CEO about her missing data? Maybe not.
By leveraging best practices from our friends in software engineering and developer operations (DevOps), we can think more strategically about tackling the “good pipelines, bad data” problem. For many, this approach incorporates observability, too.
Jesse Anderson, managing director of Big Data Institute and author of Data Engineering Teams: Creating Successful Big Data Teams and Products, and Barr Moses, co-founder and CEO of Monte Carlo, share everything you need to know to get started with this next layer of the data stack.
Data engineering is often called the “plumbing of data science” — usually, referring to the way data engineers make sure all the pipelines and workflows are functioning properly, with the right data flowing in the right directions to the right stakeholders. But most data engineers I talk to also relate to plumbers in one very specific way: you only call them when something goes wrong.
The late-night email from your VP — I need the latest numbers for my board presentation tomorrow morning, and my Looker dashboard is broken.
The early-morning phone call from a data scientist — the data set they’re consuming for a model isn’t working right anymore.
The mid-meeting Slack from a marketing lead — my campaign ROI is out of whack this month. I think something’s wrong with the attribution data.
The message that never comes — the data in this report is perfect. Keep up the good work!
OK, hopefully your company does recognize and appreciate a job consistently well done, but the truth remains: too many data engineers spend too much time fighting fires, troubleshooting issues, and trying to patch burst pipelines.
One way to get out of the vicious late-night-email cycle? Data observability.
#1. What data observability is — and why it matters
Data observability is a new layer in the modern data tech stack, providing data teams with visibility, automation, and alerting into broken data (i.e., data drift, duplicate values, broken dashboards… you get the idea). Frequently, observability leads to faster resolution when issues occur, and can even help prevent downtime from impacting data consumers in the first place.
Beyond its obvious benefit — healthier data! — data observability can also build trust and foster a data-driven culture across your entire organization. When observability tooling and frameworks are made available to data consumers as well as engineers and data scientists, they can more fully understand where data is coming from and how it’s being used, as well as get real-time insight into the status of known issues. This added transparency leads to better communication, more efficient collaboration, and more trust in data.
And with data observability tooling in place, engineers can reclaim valuable time that was previously spent fire-fighting and responding to data emergencies. For example, the data engineering team at Blinkist found that automated monitoring saved up to 20 hours per engineer each week. Those valuable hours can now be spent on innovation and problem-solving–not wrangling data gone wrong.
#2. How DevOps inspired data observability
All this talk of observability, downtime, monitoring, and alerting likely sounds familiar to anyone with experience in software engineering. That’s because the parallels are intentional: the concept of data observability was inspired by DevOps, following the principles and best practices that software engineers developed over the last 20 years to prevent application downtime.
Just like in DevOps, data observability leverages a blanket of diligence for data, flipping the script from ad-hoc troubleshooting to proactive automation of monitoring, alerting, and triaging. By applying these principles, data engineers can better identify and evaluate data quality, building trust with other teams and laying the groundwork for a data-driven organization.
Following the framework of observability in application engineering, data observability is broken into five pillars: freshness, distribution, volume, schema, and lineage.
- Freshness captures how up-to-date your data tables are.
- Distribution tells you if your data falls within an expected range.
- Volume offers insights on the completeness of your data tables and the health of your data sources.
- Schema delivers an understanding of who makes changes to data tables, and when.
- Lineage maps the upstream sources and downstream ingestors of your data, helping you determine where errors or outages have occurred.
#3. Data can break for a million different reasons…but there are 3 key factors that contribute to each
Data downtime will occur. When it does, understanding the common factors that contribute to most outages will help you resolve issues swiftly.
First is the sheer number of third-party data sources your company relies on to provide data — the more sources you have, the more opportunities for data to go missing or be incorrect. You can’t control third-party sources, but observability helps you be the first to know when something’s gone wrong (instead of your CEO on the morning of her important board meeting).
Second, as your number of sources increases, so does the complexity of your data pipelines. Once data flows into your organization, it may be stored, secured, processed, transformed, aggregated, and delivered — and again, the more your data moves, the more opportunities for something to go wrong.
The final key factor in broken data may be the first one you thought of: your increasing number of data consumers. As data is piped into more dashboards and BI tools, there are still more opportunities for breakages, as well as innocent misunderstandings or misinterpretations that may spur last-minute fire drills when nothing was actually wrong with your data in the first place.
#4. Data observability is more than just vigorous testing and monitoring
Just like in application engineering, testing is a useful way to identify outages or issues in your data. But data testing alone is insufficient, particularly at scale. Data changes — a lot — and even moderately sized datasets introduce a lot of complexity and variability. It also comes from third-party sources, where changes to data structure can happen without warning. And security and compliance concerns can make it challenging for some data teams to find a representative dataset that can be used for development and testing purposes.
Since unit testing can’t find or anticipate every possible issue, innovative data teams blend testing with continual monitoring and observability across the entire pipeline. Automation makes this possible, with the best observability tools using machine learning to observe, understand, and predict downtime with automatically generated rules — and route alerts intelligently for faster resolution.
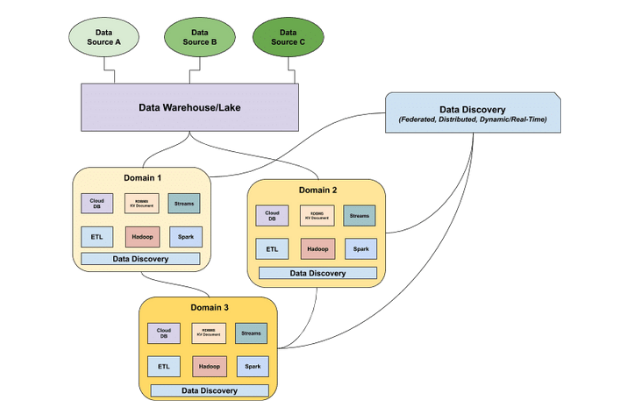
Data observability also delivers lineage, which we defined earlier as mapping the upstream sources and downstream ingestors of your data. Lineage truly gives you a bird’s-eye view of your data, understanding where it came from, who interacted with it, any changes that were made, and where it’s ultimately served to end consumers.
This visibility enables data discovery, which we describe as the next generation of data catalogs — providing a dynamic understanding of your data based on its lineage. Automated, scalable, and distributed, data discovery enables you to answer questions about the current state of your data across every domain: When was this table last updated? Who has access to it? When was this data asset last used? Is it production-quality?
With all of this information and automation at your disposal, you can prepare and operate robust playbooks for incident remediation. When downtime does occur, your team will be well-equipped to laser in on the root cause and respond swiftly — again, reducing the time spent on fire drills in favor of innovation and problem-solving.
#5. When it comes to your data, having mostly bad data is worse than having no data at all.
Bad data is insidious in a way that bad code is not. With application engineering, testing usually reveals any errors — or, if it doesn’t, your application will likely break due to buggy code. And then you can fix it.
With data, it’s different. Even with testing, you may not realize when bad data has crept into your ecosystem through one of many APIs or endpoints. And without observability, that bad data may go undetected for some time — leading to incorrect reporting and even ill-informed decision making.
As organizations grow increasingly reliant on data to drive their business, it’s well past time for data engineers to pay as much attention to data quality as DevOps engineers do to application health. By embracing a more holistic approach to data quality and discovery, you and your team can reclaim valuable time, build trust, and break the cycle of late-night emails and last-minute fire drills. For good.
Interested in learning more? Reach out to Jesse Anderson or Barr Moses.
Read more posts.