Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Future of Data Engineering as a Data Engineer

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
In the world of data engineering, Maxime Beauchemin is someone who needs no introduction.
One of the first data engineers at Facebook and Airbnb, he wrote and open sourced the wildly popular orchestrator, Apache Airflow, followed shortly thereafter by Apache Superset, a data exploration tool that’s taking the data viz landscape by storm. Currently, Maxime is CEO and co-founder of Preset, a fast-growing startup that’s paving the way forward for AI-enabled data visualization for modern companies.

It’s fair to say that Maxime has experienced – and even architected – many of the most impactful data engineering technologies of the last decade, and pioneering the data engineering role itself through his landmark blog post, The Rise of the Data Engineer, in which he chronicles many of his observations. In short, Maxime argues that to effectively scale data science and analytics in the future, data teams needed a specialized engineer to manage ETL, build pipelines, and scale data infrastructure.
Enter, the data engineer. The data engineer is a member of the data team primarily focused on building and optimizing the platform for ingesting, storing, analyzing, visualizing, and activating large amounts of data.
A few months later, Maxime followed up that piece with a reflection on some of the data engineer’s biggest challenges: the job was hard, the respect was minimal, and the connection between their work and the actual insights generated were obvious but rarely recognized. Data engineering was a thankless but increasingly important job, with data engineering teams straddling between building infrastructure, running jobs, and fielding ad-hoc requests from the analytics and BI teams. As a result, being a data engineer was both a blessing and a curse.
In fact, in Maxime’s opinion, the data engineer was the “worst seat at the table.”
So, six years later in the future, where does the field of data engineering stand? What is a data engineer today? What do data engineers do?
I sat down with Maxime to discuss the current state of affairs, including the decentralization of the modern data stack, the fragmentation of the data team, the rise of the cloud, and how all these factors have changed the role of the data engineer forever.
The speed of ETL and analytics has increased
Maxime recalls a time, not too long ago, when data engineering would require running Hive jobs for hours at a time, frequent context switching between jobs and managing different elements of your data pipeline.
To put it bluntly, data engineering was boring and exhausting at the same time.
“This never-ending context switching and the sheer length of time it took to run data operations led to burnout,” he says. “All too often, 5-10 minutes of work at 11:30 p.m. could save you 2-4 hours of work the next day — and that’s not necessarily a good thing.”
In 2024, data engineers can run big jobs very quickly thanks to the compute power of BigQuery, Snowflake, Firebolt, Databricks, and other cloud warehousing technologies. This movement away from on-prem and open source solutions to the cloud and managed SaaS frees up data engineering resources to work on tasks unrelated to database management.
On the flipside, costs are more constrained.
“It used to be fairly cheap to run on-prem, but in the cloud, you have to be mindful of your compute costs,” Maxime says. “The resources are elastic, not finite.”
With data engineers no longer responsible for managing compute and storage, their role is changing from infrastructure development to more performance-based elements of the data stack, or even specialized roles.
“We can see this shift in the rise of data reliability engineering, and data engineering being responsible for managing (not building) data infrastructure and overseeing the performance of cloud-based systems.”
It’s harder to gain consensus on governance – and that’s OK
In a previous era of data engineering, data team structure was very much centralized, with data engineers and tech-savvy analysts serving as the “librarians” of the data for the entire company. Data governance was a siloed role, and data engineers became the de facto gatekeepers of data trust — whether or not they liked it.
Nowadays, Maxime suggests, it’s widely accepted that governance is distributed. Every team has their own analytic domain they own, forcing decentralized team structures around broadly standardized definitions of what “good” data looks like.
“We’ve accepted that consensus-seeking is not necessary in all areas, but that doesn’t make it any easier,” he says. “The data warehouse is the mirror of the organization in many ways. If people don’t agree on what they call things in the data warehouse or what the definition of a metric is, then this lack of consensus will be reflected downstream. But maybe that’s OK.”
Perhaps, Maxime argues, it’s not necessarily the sole responsibility of the data team to find consensus for the business, particularly if the data is being used across the company in different ways. This will inherently lead to duplication and misalignment unless teams are deliberate about what data is private (in other words, only used by a specific business domain) or shared with the broader organization.
“Now, different teams own the data they use and produce, instead of having one central team in charge of all data for the company. When data is shared between groups and exposed at a broader scale, there needs to be more rigor around providing an API for change management,” he says.
Which brings us to our next point…
Change management is still a problem – but the right tools can help
When Maxime wrote his first data engineering article, “when data would change, it would affect the whole company but no one would be notified.” The lack of future-proofing change management has caused both by technical and cultural gaps.
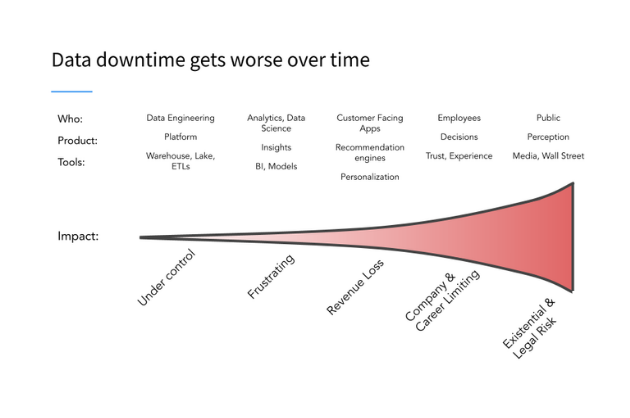
When source code or data sets were changed or updated, breakages occurred downstream that would render dashboards, reports, and other data products effectively invalid until the issues were resolved. This data downtime (periods of time when data is missing, inaccurate, or otherwise erroneous) was costly, time-intensive, and painful to resolve.
All too often, downtime would strike silently, and data engineering teams would be left scratching their heads trying to figure out what went wrong, who was affected, and how they could fix it.
Nowadays, data engineering teams are increasingly relying on DevOps and software engineering best practices to build stronger tooling and cultures that prioritize communication and data reliability.
“Data observability and lineage have certainly helped data engineering teams identify and fix problems, and even surface information about what broke and who was impacted,” said Maxime. “Still, change management is just as cultural as it is technical. If decentralized teams are not following processes and workflows that keep downstream consumers or even the central data platform team in the loop, then it’s challenging to handle change effectively.”
If there’s no delineation between what data is private (used only by the data domain owners) or public (used by the broader company), then it’s hard to know who uses what data, and if data breaks, what caused it. Lineage and root cause analysis can get you half of the way there.
For example, while Maxime was at Airbnb, Dataportal was built to democratize data access and empower all Airbnb employees to explore, understand, and trust data. Still, while the tool told them who would be impacted by data changes through end-to-end data lineage, it still didn’t make managing these changes any easier.
Data should be immutable – or else chaos will ensue
Data tools are leaning heavily on software engineering for inspiration – and by and large, that’s a good thing. But there are a few elements of data that make working with ETL pipelines much different than a codebase. One example? Editing data like code.
“If I want to change a column name, it would be fairly hard to do, because you have to rerun your ETL and change your SQL,” said Maxime. “These new pipelines and data structures impact your system, and it can be hard to deploy a change, particularly when something breaks.”

For instance, if you have an incremental process that loads data periodically into a very large table, and you want to remove some of that data, you have to pause your pipeline, reconfigure the infrastructure, and then deploy new logic once the new columns have been dropped.
Data engineering tooling doesn’t really help you much, particularly in the context of differential loads. Backfilling data can still be really painful, but there are some benefits to holding onto them.
“There are actually good things that come out of maintaining this historical track record of your data,” he says. “The old logic lives alongside the new logic, and it can be compared. You don’t have to go and break and mutate a bunch of assets that have been published in the past.”
Keeping important data assets for future use (even if they’re no longer in use) can provide helpful context. Of course, the goal is that all of these changes should be documented explicitly over time.
So, pick your poison? Data debt or data pipeline chaos.
For a similar perspective on data immutability, check out Convoy head of data Chad Sanderson’s article “Is the Modern Data Warehouse Broken?“
The role of the data engineer is splintering
Just as in software engineering, the roles and responsibilities of data engineering are changing, particularly for more mature organizations. The database engineer is becoming extinct, with data warehousing needs moving to the cloud, and data engineers are increasingly responsible for managing data performance and reliability.
According to Maxime, this is probably a good thing. In the past, the data engineer was “the worst seat at the table,” responsible for operationalizing the work of someone else with tooling and processes that didn’t quite live up to the needs of the business.
Now, there are all sorts of new data engineering type roles emerging that make this a little bit easier. Case in point, the analytics engineer. Coined by Michael Kaminsky, editor of Locally Optimistic, the analytics engineer is a role that straddles data engineering and data analytics, and applies an analytical, business-oriented approach to working with data.
The analytics engineer is like the data whisperer, responsible for ensuring that data doesn’t live in isolation from business intelligence and analysis.
“The data engineer becomes almost like the keeper of good data habits. For instance, if an analytics engineer reprocesses the warehouse at every run with dbt, they can develop bad habits. The data engineer is the gatekeeper, responsible for educating data teams on best practices, most notably around efficiency (handling incremental loads), data modeling, and coding standards, and relying on data observability and DataOps to ensure that everyone is treating data with the same diligence.”
Operational creep hasn’t gone away – it’s just been distributed
Operational creep, as discussed in Maxime’s earlier article, refers to the gradual increase of responsibilities over time, and unfortunately, it’s an all-too-common reality for data engineers. While modern tools can help make data engineers more productive, they don’t always make their lives easier or less burdensome. In fact, they can often introduce more work or technical debt over time.
Still, even with the rise of more specialized roles and distributed data engineering teams, the operational creep hasn’t gone away. Some of it has just been transferred over to other roles as technical savvy grows and more and more functions invest in data literacy.
For instance, Maxime argues, what the analytics engineer prioritizes isn’t necessarily the same thing as a data engineer.
“Do analytics engineers care about the cost of running their pipelines? Do they care about optimizing your stack or do they mostly care about providing the next insight? I don’t know.” He says. “Operational creep is an industry problem because, chances are, the data engineer will still have to manage the ‘less sexy’ things like keeping tabs on storage costs or tackling data quality.”
In the world of the analytics engineer, operational creep exists, too.
“As an analytics engineer, if all I have to do is to write a mountain of SQL to solve a problem, I’ll probably use dbt, but it’s still a mountain of templated SQL, which makes it hard to write anything reusable or manageable,” Maxime says. “But it’s still the option I would choose in many cases because it’s straightforward and easy.”
Ideally in the future he suggests, we’d want something that looks even more like modern code because we can create abstractions in a more scalable way.
So, what’s the future of data engineering?
My conversation with Maxime left me with a lot to think about, but, by and large, I tend to agree with his points. While data team reporting structure and operational hierarchy is becoming more and more vertical, the scope of the data engineer is becoming increasingly horizontal and focused on performance and reliability – which is ultimately a good thing.
Focus breeds innovation and speed, which prevents data engineers from trying to boil the ocean, spin too many plates, or generally burn out. More roles on the data team mean traditional data engineering tasks (fielding ad-hoc queries, modeling, transformations, and even building pipelines) don’t need to fall solely on their shoulders. Instead, they can focus on what matters: ensuring that data is trustworthy, accessible, and secure at each point in its lifecycle.
The future of the data engineering tooling landscape reflects this move towards a more focused and specialized role. DataOps makes it easy to schedule and run jobs; cloud data warehouses make it easy to store and process data in the cloud; data lakes allow for even more nuanced and complex processing use cases; and data observability, like application monitoring and observability before it, automates many of the rote and repetitive tasks related to data quality and reliability, providing a baseline level of health that allows the entire data organization to run smoothly.
Data quality, especially, is more important than ever as data engineers become tasked with managing and optimizing the data that powers the output of generative AI (genAI) and Retrieval-Augmented Generation (RAG) models. This responsibility not only amplifies the importance of their role in the AI-driven landscape but also requires a deeper understanding of machine learning operations (MLOps), data ethics, and bias mitigation.
With the rise of these new technologies and workflows, engineers also have a fantastic opportunity to own the movement towards treating data like a product. Building operational, scalable, observable, and resilient data systems is only possible if the data itself is treated with the diligence of an evolving, iterative product. Here’s where use case-specific metadata, ML-driven data discovery, and tools that can help us better understand what data actually matters and what can go the way of the dodos.
At least, that’s what we see in our crystal ball.
What do you see in yours? 🙂
Reach out to Maxime or Lior with your data engineering predictions. We’re all ears. Book a time to speak with Monte Carlo using the form below.
Our promise: we will show you the product.
FAQ By Monte Carlo
Will data engineering be automated?
To some extent yes, certain tasks required to be performed currently by data engineers in the future could be automated. However, that would simply mean that the areas of responsibility of data engineers would shift towards more strategic tasks.
What are data engineering skills?
Data engineers design, build, and maintain data pipelines to ensure data from various sources get to where it’s needed. They also play a crucial role in sourcing, curating, and ensuring the quality of the data feeding genAI and RAG models.
What would data engineers do in the future?
In the future, data engineers can run big jobs very quickly thanks to the computing power of BigQuery, Snowflake, Firebolt, Databricks, and other up-and-coming cloud warehousing technologies. This movement away from on-prem and open source solutions to the cloud and managed SaaS frees up data engineering resources to work on tasks unrelated to database management.
Read more posts.