Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Best Egg Implemented a Reliable Data Mesh with Data Observability


Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
Fintech consumer lending marketplace Best Egg has built its products—including personal loans, debt consolidation, credit cards, and a financial health platform—on a foundation of data. Employee number three at Best Egg was Randy Addis, now Head of Data and Business Intelligence. Today, nearly a decade later, Randy leads over 20 people on the Best Egg data and BI teams.
Randy’s team integrates application data from potential customers, credit bureaus, and other third-party sources. They support analytics functions across direct mail, marketing channels, acquisition funnels, customer engagement, and credit risk evaluations. And they enable crucial business functions like forecasting delinquency, credit losses, and collections and recovery.
In other words, the Best Egg data team has a long history of solving tough data problems. But in recent years, Randy and his colleagues have tackled one of their biggest challenges yet: building a data mesh, a type of decentralized data platform architecture that leverages a domain-driven, self-serve design.
We recently sat down with Randy to chart Best Egg’s course from siloed SQL databases to domain-driven data mesh—and hear the hard-won tips he learned along the way.
The early days of the data mesh journey
Long before Best Egg established their data mesh, data was siloed and owned by disparate teams managing their own data stores across tools like Excel and SQL servers. As Randy’s dedicated data team grew and matured, they wanted to remove data silos, modernize the data stack, and migrate to a cloud-based platform.
“We as the central data team said, ‘Hey, we want to inherit all of these siloed data marts’,” Randy said. “Our focus for the first couple of years was inheriting those and standardizing how we loaded data. Then we migrated to a more modern data stack, developing our Python skill set and leveraging AWS technologies.”
Today, Best Egg’s data stack is built primarily on AWS and leverages tools like Kafka, Sagemaker, dbt, and Terraform. Randy’s team also uses custom code to ingest specific types of third-party data, like their bank processor’s EBCDICfiles. The analytics users across the company access most data through Snowflake and PowerBI.
As Best Egg’s data capabilities expanded, they added more vendors, launched more products, and needed an even more robust approach to distribute quality information across the data-hungry organization.
“The scale and the breadth of data felt like it was not going to continue to be manageable,” said Randy.
The challenge: More data use cases, lack of clear ownership
While data ownership had long been distributed across multiple business functions at Best Egg, domains were not well-defined, and there were no governance standards established. As Randy researched possible ways to solve these issues, the data mesh framework emerged as a clear winner.
“We sort of had the domain box checked, but not all the other good pieces of data mesh in terms of the interoperability—because literally, they weren’t on the same platform,” said Randy.
The team’s adoption of a modern, serverless data stack, “led to the ability to move to this more domain-oriented structure. Now, it’s not necessarily worrying about how we are going to get the data from server A to server B, because it’s all connected in the cloud. Now it’s more about we have such a breadth of data—how do we manage it and make it more easily discoverable and more easily searchable? How do we instill the sense of quality and timeliness in the data?”
As a startup, Best Egg had been focused on proving its business model, not establishing organization-wide data governance. Now, the team needed to address unclear ownership and a lack of federated governance standards to achieve one of Randy’s primary goals for a data mesh: the mentality of treating data as a product.
“Imagine your data team is going up against a competing data team within your own company—more like putting an offering out into the open market, versus the relative monopoly of your internal company,” said Randy. “How will you build a data product that’s superior to any other data team?”
As Randy and his team worked to define domain ownership and start distributing accountability across the organization, they needed to holistically address data reliability in order to deliver a quality product to their internal consumers.
The solution: Data observability with Monte Carlo
To ensure the data populating their products was trustworthy and reliable, Randy and his team needed to improve their visibility into data health across every domain. They decided to adopt the Monte Carlo data observability platform.
Randy’s team implemented Monte Carlo to automate monitoring and alerting for known and unknown data issues, such as freshness, volume, and dimension changes. The central data team is now the first to know when data issues occur, and domain owners are automatically looped in to be aware of the impact and have accountability to help resolve any problems that may arise.
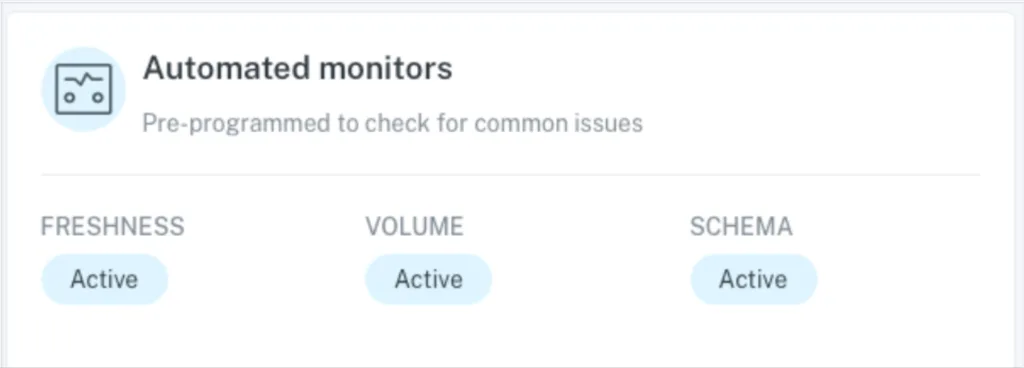
Best Egg automatically has all of their tables covered by freshness, volume, and schema monitors without having to set any thresholds or manual rules.
“People outside of our team who are part of the data mesh and might maintain their own side table or schema for a very purpose-driven thing are able to use Monte Carlo,” said Randy. “For example, an analyst wrote a rule in Monte Carlo to sniff out and understand how an issue with malformed phone numbers was happening. And we’ve seen it decrease over time as we’ve been taking care of it.”
Users can create custom rules using SQL.
Monte Carlo integrates with existing tools in Best Egg’s platform to ensure quick resolution of incidents within domains. Alerts can be routed via Slack channels to the right domain owners, assigning accountability for each domain’s source data and having the right people involved to resolve issues.
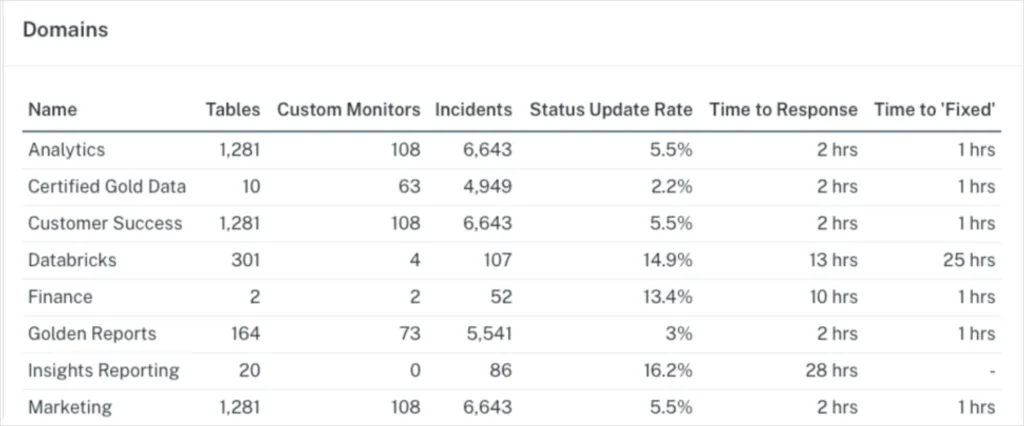
While domain owners are accountable for resolution, Monte Carlo helps the central data team become proactive about identifying when downtime occurs. “Before, it might be a Slack message saying, ‘Hey, it seems like today’s data is missing from this table,’,” said Randy. “And it causes that ‘oh crap’ moment and scrambling to fix it. Whereas now, we’ll generally know ahead of time—because if that load was supposed to run at two in the morning, we’ll have an alert sitting there and we can figure it out.”
With Monte Carlo, data consumers across the company can trust the quality of the data they’re working with. “It’s huge because otherwise there’s a constant fear or worry about whether things are running okay,” said Randy. “We can share screenshots from Monte Carlo and talk to folks about what it’s doing and how we receive notification and respond to anomalies. It gives everyone confidence.”
Key takeaways for implementing a data mesh
Of course, implementing data observability is only one piece of the data mesh puzzle. Randy shared a few additional takeaways from his experience at Best Egg.
Gain stakeholder buy-in with a few quick wins
According to Randy, when it comes to adopting a data mesh, the people and organizational change is the hardest part. “Getting everyone who is busy with their day jobs to connect the dots around how the investment in this methodology will benefit them is the biggest challenge.”
Randy’s advice is to stay flexible and remember that business users, software engineers, and platform engineers all have their own jobs and priorities. Have early conversations about changes that will impact analytics, and get them involved.
“I don’t want to call it a Jedi mind trick,” said Randy. “But there were folks that had been a little more vocal over time around things like quality, discoverability, and ease of use. And I had to turn that energy in a different direction to work with those folks to get them to share not just the issues, but what success looks like if we built a complete data product. I know it’s a cliche thing, but finding those things that we can build out really quickly that benefit everybody has been important for us.”
Establish a data governance council to drive consensus
Get those key stakeholders involved in a data governance council, Randy advises. “Finding a couple key allies in the business that you can work with has helped me,” he said. “We’ve built out a data governance council, with a person from the business side functioning as the head to be on board with the concept and be an ally.”
Partner with like-minded peers to establish domains
Even in a company like Best Egg, which had a history of distributed data ownership, defining the data domains was a challenge. Randy found it was essential to work with his counterparts in software engineering, who had already adopted a similar model.
“We worked very closely with our software engineering and platform teams,” Randy said. “The software engineering team was basically operating in this model—a more distributed, microservice-driven model and aligned around the customer journey of different phases of the customer’s interaction with Best Egg.”
The data team aligned their data domains around the five journeys in the business that were already being used to align microservices and source systems. Since the structure was already familiar to stakeholders, and software engineers were on board as allies, it simplified the process of defining data ownership.
Remember that adopting a data mesh is a marathon—not a sprint
“Don’t be afraid that the data mesh is going to take some time,” said Randy. “I started reading about it a year and a half ago, took a while to get my own head wrapped around it, and then started to socialize it internally to get some buy-in. That piece is difficult. But we aspire to be a company that really leverages our data for our customers’ benefit, and to achieve that mission, we needed to make a change.”
What’s next for data mesh at Best Egg?
As Randy and his team continue to refine their data mesh approach, they have a few priorities on the roadmap for the coming year. They plan to use their data catalog provider, Atlan, to house the data definitions set by domain owners.
In order to increase participation in the project, Randy and his team are using gamification in the spring. They hope playing “March Metadata Madness” will get people used to going to the shared data catalog tool.
Randy also plans to increase adoption of dbt and centralize their metrics layer of definitions (one of our predictions for data engineering trends in 2023). This will help them avoid issues that come up when different teams use different definitions for concepts like customer activation or customer attrition, and continue to standardize and improve data quality across the organization.
Inspired by Best Egg and ready to start your own data mesh journey? Contact our team using the form below to learn how data observability can help ensure your data is reliable and trustworthy across every domain.
Our promise: we will show you the product.
Read more posts.