Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is Data Observability vs. DataOps?


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Actually, that’s a trick question.
Why? Well, we can liken the Data Observability vs. DataOps relationship to Beyonce (there’s a sentence I never expected to write!). Just as every Beyonce song is a hit, but not every hit song is by Beyonce, data observability is one key component of DataOps, but DataOps is more than just data observability.
So, the more apt question(s) may actually be: How does data observability fit into DataOps? And why does it matter? (And when is Beyonce’s next album coming out anyway?)
This article will define DataOps and the DataOps lifecycle, and dive into how data observability fits into DataOps for comprehensive data pipeline management.
Table of Contents
At-a-glance: Data observability vs. DataOps
The difference between data observability vs. DataOps is that DataOps supports the process of quick deployment of data pipelines, whereas data observability is the tool that ensures the data is reliable across those data pipelines.
DataOps is a strategic initiative comprising the full data engineering and data science lifecycle to build and manage data pipelines, including data testing, integration, deployment, and orchestration. On the other hand, data observability is the tool that ensures that all of the data moving through these stages is accurate, fresh, timely, and up-to-date.
Let’s dive into the nitty-gritty of DataOps, data observability, and how they work together.
What is DataOps?
DataOps is a strategic initiative that merges data engineering and data science teams to build and manage data pipelines.
In the same way that DevOps enables organizations to scale software engineering, DataOps helps an organization better support their data pipelines by delivering timely, fresh, and accurate data to downstream business consumers.
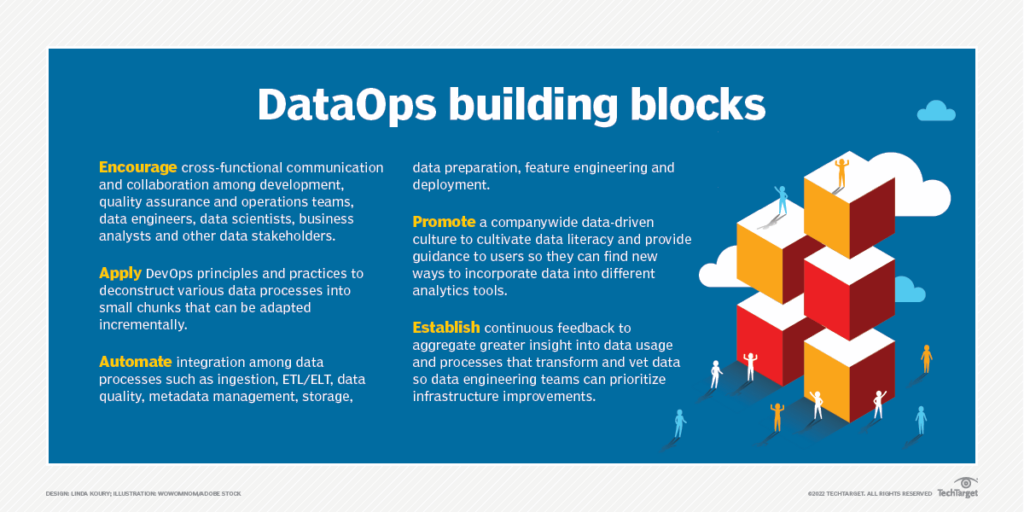
DataOps includes testing, integration, deployment, and orchestration. And data observability brings reliable data to all of these stages of a data pipeline – making it a crucial tenet of a DataOps strategy.
The benefits of DataOps
DataOps enables quick deployment of data pipelines while delivering reliable and readily available data.
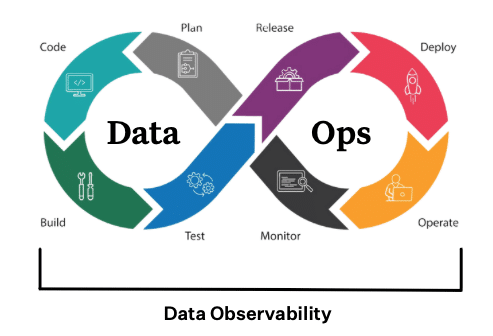
DataOps teams typically employ a feedback loop framework consisting of the following steps:
- Planning
- Development
- Integration
- Testing
- Release
- Deployment
- Operate
- Monitor
Typically, DataOps teams repeat this cycle over and over again, allowing both data teams and business stakeholders to work together to deliver more reliable data and analytics to the entire organization.
Data observability – an organization’s ability to understand the health of their data systems – sits at the foundation of the DataOps feedback loop. It ensures that all of the data moving through the DataOps cycle is fresh, timely, and up-to-date.
Data observability vs. DataOps: The difference
Data observability is a key tool for reducing data downtime, or periods of time with a team’s data is partial, erroneous, missing or otherwise inaccurate. The right data observability tool automatically monitors data and AI pipelines for anomalies and incidents, and then alerts the appropriate stakeholders right away – reducing time to detection and time to resolution.
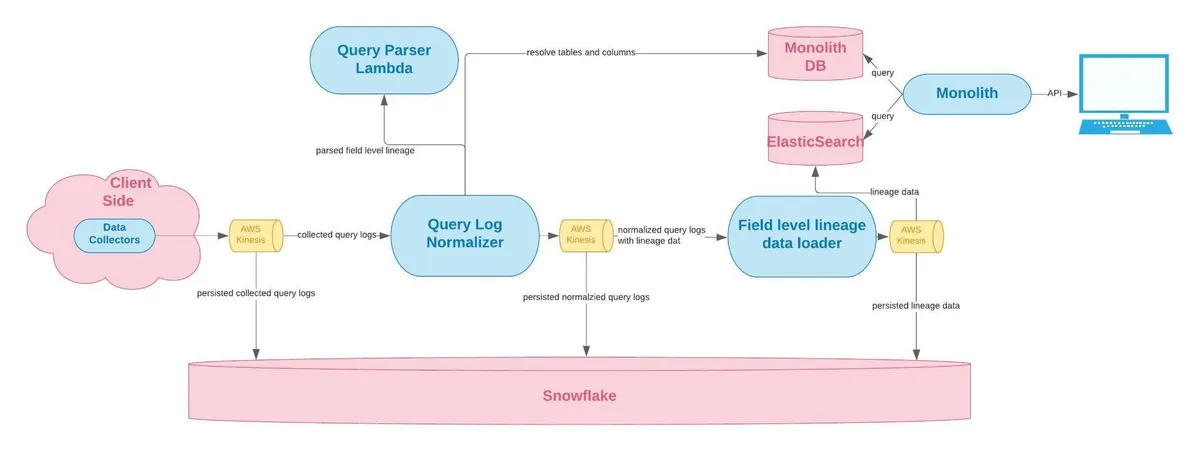
This data pipeline monitoring is crucial for DataOps to function. Data observability is fundamental to DataOps because it monitors and detects anomalies across the DataOps continuous lifecycle. The most effective data observability tools, like Monte Carlo, include automated data lineage. This feature enables DataOps engineers to perform more efficient root-cause analysis (RCA) and maintain a comprehensive view of your data’s health at every point in the lifecycle. Monte Carlo provides each of these solutions out-of-the-box, as well as dashboards and CI/CD integrations like GitHub to improve data quality workflows across teams.
If data incidents occur without being noticed or with unclear RCA, then the entire DataOps framework is operating in error via unreliable data – ultimately resulting in incorrect insights and reduced data trust downstream.
Put simply, without a data observability tool to ensure that your data is reliable, your DataOps organization can’t exist.
Why data observability matters for DataOps
With data observability at the foundation, DataOps can be a key value driver for an organization. There are many benefits of comprehensive DataOps with data observability, including:
- Better data quality, monitored by automated end-to-end data observability
- Happier and more productive data teams, with less time spent firefighting data issues
- Faster access to analytic insights, when anomaly detection and RCA is automatically handled by a data observability tool
- Reduced operational and legal risk, with more transparency and visibility into data’s lifecycle via data lineage
With a data observability tool’s automated monitoring, alerting, and triaging to identify data quality issues, your DataOps team can manage healthier pipelines – and in turn, healthier customers.
To learn more about how to implement data observability for DataOps, speak to our team.
Our promise: we will show you the product.
Read more posts.