Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How to Fix Your Data Quality Problem


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Data quality management is top of mind for every data professional — and for good reason. Bad data costs companies valuable time, resources, and most of all, revenue. So why are so many of us struggling with trusting our data? Isn’t there a better way?
The data landscape is constantly evolving, creating new opportunities for richer insights at every turn. Data sources old and new mingle in the same data lakes and warehouses, and there are vendors to serve your every need, from helping you build better data catalogs to generating mouthwatering visualizations (leave it to the NYT to make mortgages look sexy).
Not surprisingly, one of the most common questions customers ask me is “what data tools do you recommend?”
More data means more insight into your business. At the same time, more data introduces a heightened risk of errors and uncertainty. It’s no wonder data leaders are scrambling to purchase solutions and build teams that both empower smarter decision making and manage data’s inherent complexities.
But I think it’s worth asking ourselves a slightly different question. Instead, consider: “what is required for our organization to make the best use of — and trust — our data?”
Data quality does not always solve for bad data
It’s a scary prospect to make decisions with data you can’t trust, and yet it’s an all-too-common practice of even the most competent and experienced data teams. Many teams first look to data quality as an anecdote for data health and reliability. We like to say “garbage in, garbage out.” It’s a true statement — but in today’s world, is that sufficient?
Businesses spend time, money, and resources buying solutions and building teams to manage all this infrastructure with the pipe(line) dream of one day being a well-oiled, data-driven machine — but data issues can occur at any stage of the pipeline, from ingestion to insights. And simple row counts, ad hoc scripts, and even standard data quality conventions at ingestion just won’t cut it.
One data leader I spoke with at a major transportation company told me that, on average, it took his team of 45 engineers and analysts 140 hours per week to manually check for data issues in their pipelines. Even if you have a data team of 10 people, that’s five whole days that could have spent on revenue-generating activities.
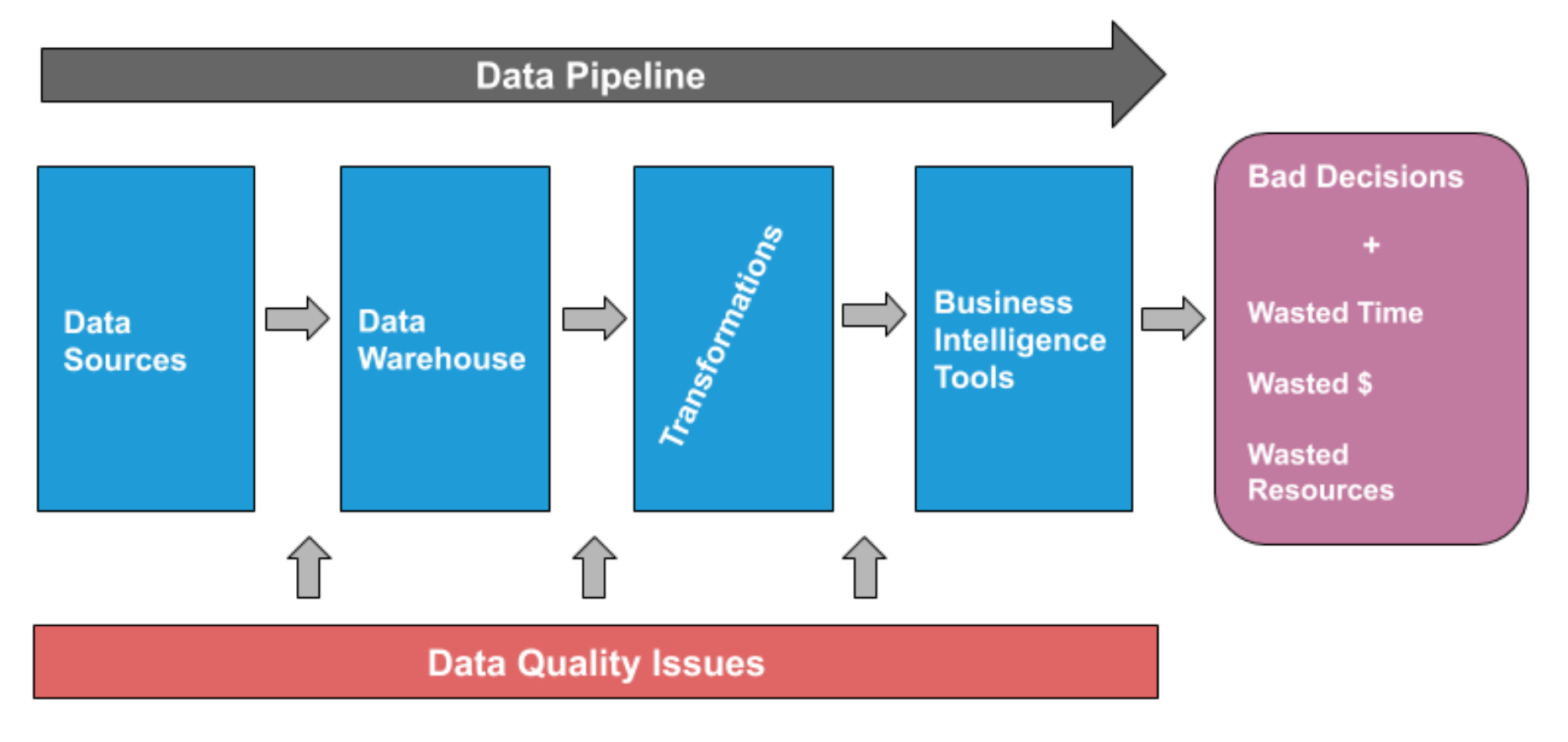
No amount of fancy tools, well-trained engineers, and executive buy-in can prevent bad data from breaking your pipelines. While organizations invest so much in building great infrastructure, they often find themselves at a loss when it comes to the integrity of the system overall, or: data downtime.
Data downtime, in other words, moments where your data is missing, erroneous, or otherwise compromised, is both your data ecosystem’s biggest pain point and the key to fully understanding your data quality. Data downtime can lead to wasted time, poor decision making, and, perhaps most significantly, loss of revenue and customer trust.
It doesn’t matter how advanced your tooling is if you don’t track data downtime. (To help my customers tackle this issue, I created a simple KPI that measures data downtime as a function of better understanding the reliability of your data.
While gut-based decision making is useful at times, it’s my firm believe that using bad or broken data is worse than having no data at all.
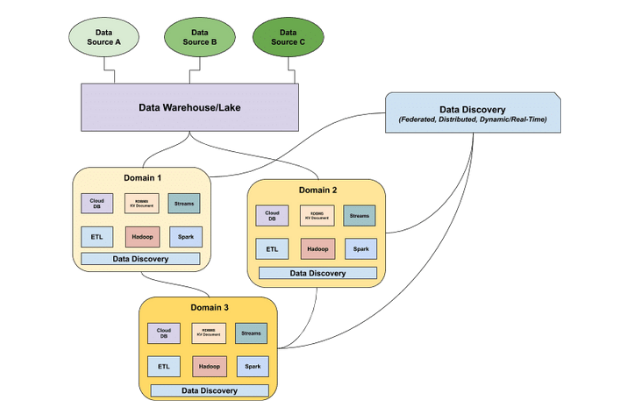
Data observability is data quality 2.0
There are a lot of solutions that market themselves as a magic box, effortlessly consuming raw data to spit out actionable insights, but in my opinion, “data” and “magic” are two terms that should never be in the same sentence (okay, maybe only in some cases…). Instead, it’s important to think of data as something that should be frequently tracked and monitored as part of a “pane of glass” approach to data management.
To unlock the true value of your data, we need to go beyond data quality. We need to ensure our data is reliable and trustworthy wherever it is. And the only way to get there is by creating observability — all the way from source to consumption. Data observability, an organization’s ability to fully understand the health of the data in their system, eliminates this perception of magic by applying best practices of DevOps to data pipelines.
And yes, data can be “bad” for a million different reasons. But in my experience, by focusing on the 5 pillars of data observability— freshness, volume, schema, distribution, and lineage — you can not only proactively find the issues in your data, but actually prevent them from occurring in the first place. (Check out my recent article on data observability for some actionable tactics, as well as a more thorough explanation of these 5 pillars.)
Data observability may not tell you which fancy new data tools to buy next, but it can save you from making bad (and potentially costly) decisions with your data.
Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.