Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 5 Ways to Use Column Level Data Lineage

Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Schema changes, null values, distribution errors. Data quality issues plague even the healthiest data systems. And as pipelines become increasingly complex with the adoption of distributed platform architectures, you can bet that data quality issues are destined to multiply right along with them.
Uncovering data quality issues is critical to the success of any data platform. But discovering issues is only half the challenge. The real question is, what do you do once you find them? That’s where column level data lineage comes in. In this article, we’ll discuss column level data lineage in detail, including what it is, how it relates to table-level lineage, and the primary use cases for a column level data lineage tool.
Ready? Let’s get started.
What is column level data lineage?
When it comes to your analytics motion, your insights are only as good as the data that informs them. So, creating a reliable data platform that delivers bankable business value involves two critical components:
- Discovering data quality issues,
- And resolving data quality issues.
Data testing is the first step in that equation. Data testing enables data engineers to uncover the data anomalies that are hiding in their data—like null values and distribution errors. While this is a critical step in preventing larger data incidents—it doesn’t tell you how to fix an issue once you find it.
Traditionally, root-causing data quality issues required manually parsing through datasets—sometimes for weeks at a time—to discover the source of a particular data anomaly. And discovering the impact of a data anomaly or change in the source data was just as tedious. Enter column level data lineage.
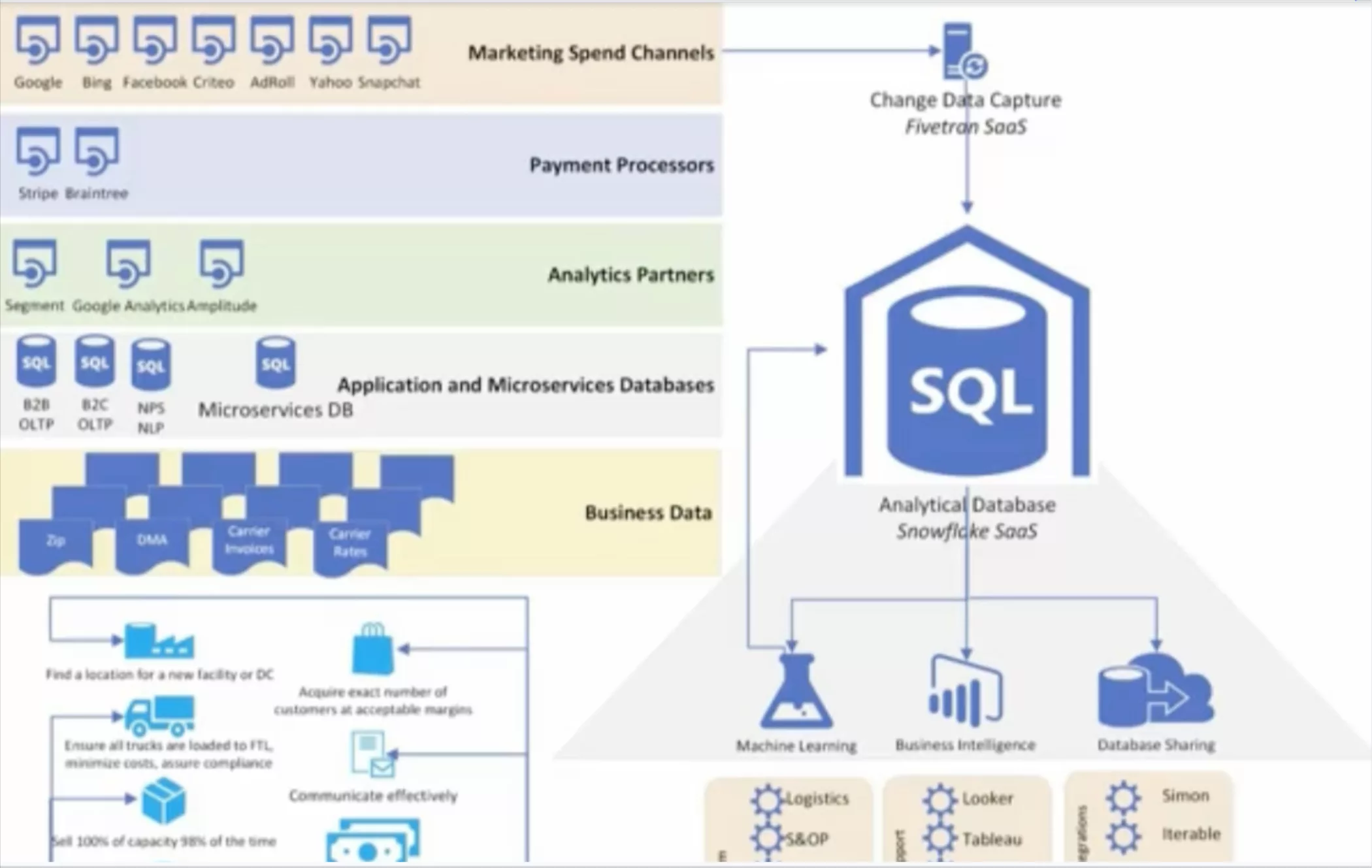
Column level data lineage is a map of a dataset’s path from ingestion to visualization that empowers data engineers to quickly trace the root cause of a data quality incident back to its source and conduct impact analysis to discover what downstream dependencies might be affected.
In short, it’s a record of how data gets from point A to point B. Column level data lineage is just one critical component of a larger data observability framework that seeks to give data engineers both visibility and understanding into the ins and outs of broken data. Taken together, column level data lineage helps data engineers or a data quality analyst trust their data and accelerate the adoption of data products across their organization.
Why do data teams use column level data lineage to root-cause data quality issues?
In the past, data teams have relied on table-level lineage to understand the cause of data incidents and their impact on downstream dependencies. But, while this can provide some much-needed context, it doesn’t provide the granularity data teams need to remediate the data problems they uncover—or prevent them from happening again in the future.
In the context of data pipelines, column level lineage traces the relationships across and between upstream source systems (i.e., data warehouses and data lakes) and downstream dependencies (e.g., analytics reports and dashboards) to illustrate how the data changes—and the effect systems changes will have at the column level.
Column level lineage can be used to massively reduce both time-to-detection and time-to-resolution of data quality issues, reducing the time to root-cause data pipeline and helping data engineers spend more time working on their data platform and less time working on their data problems.
Should I build or buy column level data lineage?
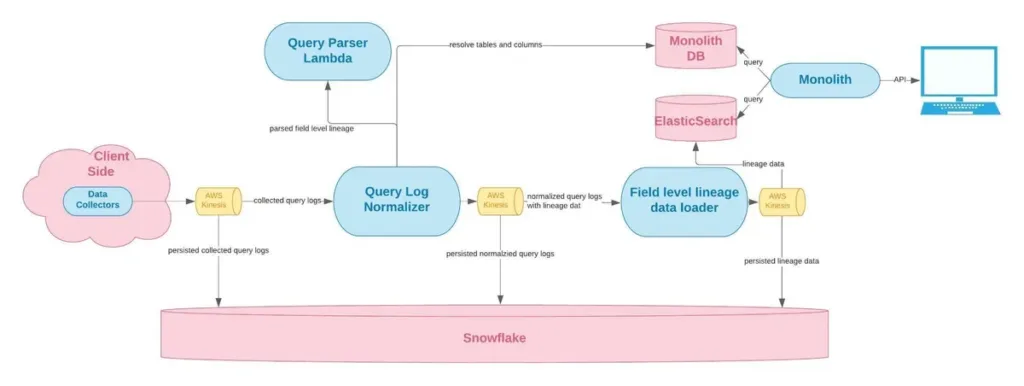
Due to the complexity of even the most basic SQL queries, building any data lineage solution is a challenge to say the least—and that goes double for column level data lineage.
Lineage is traditionally parsed manually, which requires an effectively encyclopedic knowledge of a company’s data environment and dependencies—something very few people (data engineers included) are likely to have.
And getting it up and running is only half the battle. Once it’s built, you’ve still got years of maintenance on the other side—maintenance that will become increasingly complex as your organization matures. As companies ingest more data, augment their data stack, and increase accessibility across business users, keeping a manual lineage up to date becomes unrealistic for most data teams.
For an in depth discussion of the build versus buy debate and what you should consider, check out our Build vs Buy Guide.
Column level data lineage use cases
Whether you’re a data engineer, a BI analyst, or you just look at dashboards from time to time, chances are that you’ve been asked one (or all) of these questions at some point.
- What’s the most reliable field to use for this query?
- When was the last time this table was updated?
- What the heck is wrong with my dashboard?!
Enabling data teams to more easily answer these questions is one of the key reasons why Monte Carlo built a column level data lineage tool as part of our data observability platform.
So, now let’s take a look at some of the use cases in a bit more detail.
1. Reduce data debt
Deprecating columns in frequently used data sets is important to ensure outdated objects aren’t used to generate reports. Using column level data lineage, data teams can easily identify if a column is linked to a downstream report before making changes to the system that will impact dependencies.
2. Data exploration and onboarding
When it comes to empowering your business users, data exploration tooling is key. But what happens when a reliable data exploration tool isn’t available. No data catalogs. No data dictionaries. You could tell your business users to write a SELECT TOP 5 query to explore the tables and find a few fields they can use. Or you could leverage column level data lineage.
With a robust lineage tool, analysts can easily review the upstream tables and sources for critical dashboards to develop an understanding of which fields and tables are most relevant for their analyses—information like what fields are being updated and which transformations generated the table.
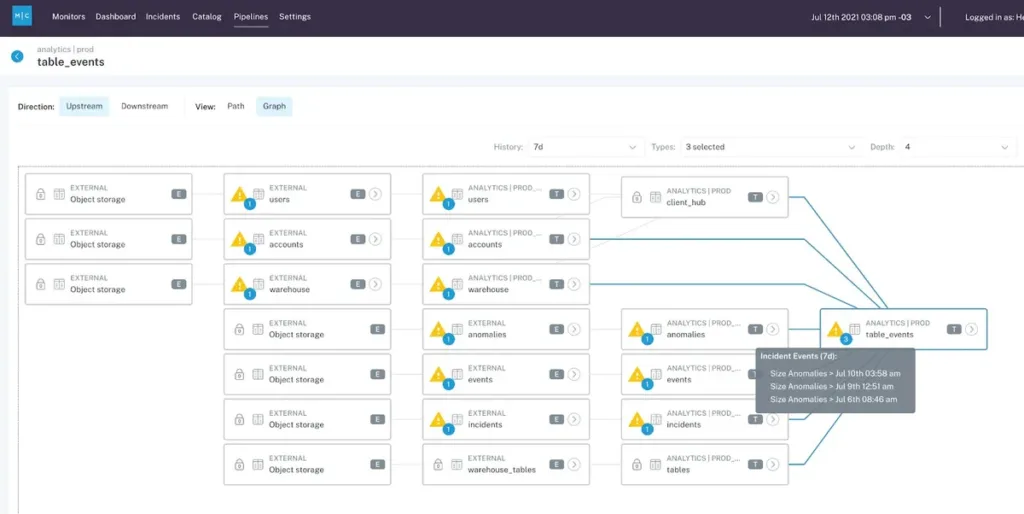
3. Data validation
When it comes to developing new dashboards and insights, it’s critical to ensure your tables are complete, current, and as-expected before conducting your analysis.
For example: when assessing historical transactions to conduct a pricing analysis, you might first want to verify the total count of transactions and cumulative revenue match the expectations of business owners or financial reports for a given period.
Instead of validating all that data manually before building your dashboards, column level data lineage empowers you to build those new dashboards with confidence by simply confirming the upstream fields (in Snowflake, for instance) are free from freshness, volume, or distribution errors.
4. Troubleshooting fields
One of the biggest bottlenecks for business users is knowing who to talk to when they encounter an issue. With column level data lineage, business users and analysts can easily identify upstream sources for fields they intend to use and who to contact if they need support.
While table lineage might reveal a few upstream tales and field dependencies, column level lineage will pinpoint the singular field in the singular table that impacts the one data point in your report. This significantly narrows the scope of your analysis.
And with solutions like Monte Carlo’s machine learning powered anomaly detection, data consumers can even be notified as soon as their dashboard has an incident—as well as staying informed of the incident’s resolution status to know when it’s resolved.
And column level data lineage isn’t just a win for business analysts either. Data engineering teams will be empowered to proactively promote data reliability by understanding exactly which dashboards and reports are impacted by changes to a field, table, or schema—even during major migration projects.
5. Managing personally identifiable information (PII)
Dealing with sensitive data brings with it a bevy of new regulatory and security challenges for data engineers. At Monte Carlo, several of our customers deal with personally identifiable information (PII), and knowing which columns with PII are linked to destination tables in downstream dashboards is essential.
Being able to efficiently trace the columns with PII down to data products and dashboards allows their data teams and data consumers to quickly remove or hide the information as-needed.
Column level data lineage improves data trust
From data validation to impact analysis, we’ve only scratched the surface of what column level data lineage can do for your data platform.
By integrating column level data lineage as part of a comprehensive data observability framework like Monte Carlo, data engineers will be empowered to root-cause and resolve issues faster, optimize engineering hours, improve data reliability, and increase value to consumers across their organizations.
Reliable data that increases institutional trust in your data platform is the ignition to accelerating data adoption across your organization. And accelerating data adoption means accelerating data development.
Column level data lineage sounds like a win-win to us.
Ready to supercharge your root-cause analyses with column level data lineage? Let's talk!
Our promise: we will show you the product.
Read more posts.