 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Organizing Generative AI Teams: 5 Lessons Learned From Data Science

Shane Murray
Shane is Field CTO of Monte Carlo. Previously, he served as the SVP of Data & Insights at The New York Times.

Michael Segner
Michael writes about data engineering, data quality, and data teams.
You did it!
After executive leadership vaguely promised stakeholders that new Gen AI features would be incorporated across the organization, your tiger team sprinted to produce a MVP that checks the box. Integrating that OpenAI API into your application wasn’t that difficult and it may even turn out to be useful.
But now what happens? Tiger teams can’t sprint forever. Each member has another role within the organization that will once again require the majority of their time and focus.
Not to mention, there is a reason for the typical processes and structures that were ignored expedited for this project. It turns out they are pretty critical to ensuring product fit, the transition from development to operations, and cost optimization (among other things).
Come to think of it, now that the project is complete there really isn’t any platform infrastructure that can help scale the next round of LLM models or other Gen AI product features.

It looks like it’s time to start thinking about how to structure and support generative AI teams within your data organization. And as easy as those slick product demos make the process look, there are signs of choppy waters ahead:
- Unless you are one of a half dozen major tech behemoths, data science and Gen AI expertise is a scarce commodity. At this point, no one really has any significant experience either. It’s new to everyone.
- The business knows it wants Gen AI, but it doesn’t really know why just yet. The technology is exciting, but specific use cases are fuzzy. No one has much experience with maintaining a deployment.
- The ecosystem has sprouted up overnight, but supporting technologies and best practices haven’t ripened just yet. Risks are generally unforeseen and uncertainty is high.
If this sounds familiar, that’s because it is. Data science teams have encountered all of these issues with their machine learning algorithms and applications over the last five years or so.
It was a painful experience. In 2020, Gartner reported only 53% of machine learning projects made it from prototype to production—and that’s at organizations with some level of AI experience. For companies still working to develop a data-driven culture, that number is likely far higher, with some failure-rate estimates soaring to nearly 90%.
As someone who led data teams at the New York Times and encountered many of these challenges, I can attest to how important organizational structure, process, and platforms are to the success of these initiatives.
I’ve also talked with hundreds of data leaders across a wide array of company sizes and industries who have expressed a common set of lessons learned. These best practices–earned through the blood, sweat, and tears of data science teams–should be top of mind for every data leader thinking about their long-term Gen AI strategy and team structure.
In This Article
Lesson 1: Understand structural trade-offs and maturity curve
Just like you can’t wake up without any training and go run a marathon, your organization can’t create a Gen AI organizational structure that mirrors leading data teams until it has strengthened its operational muscles.
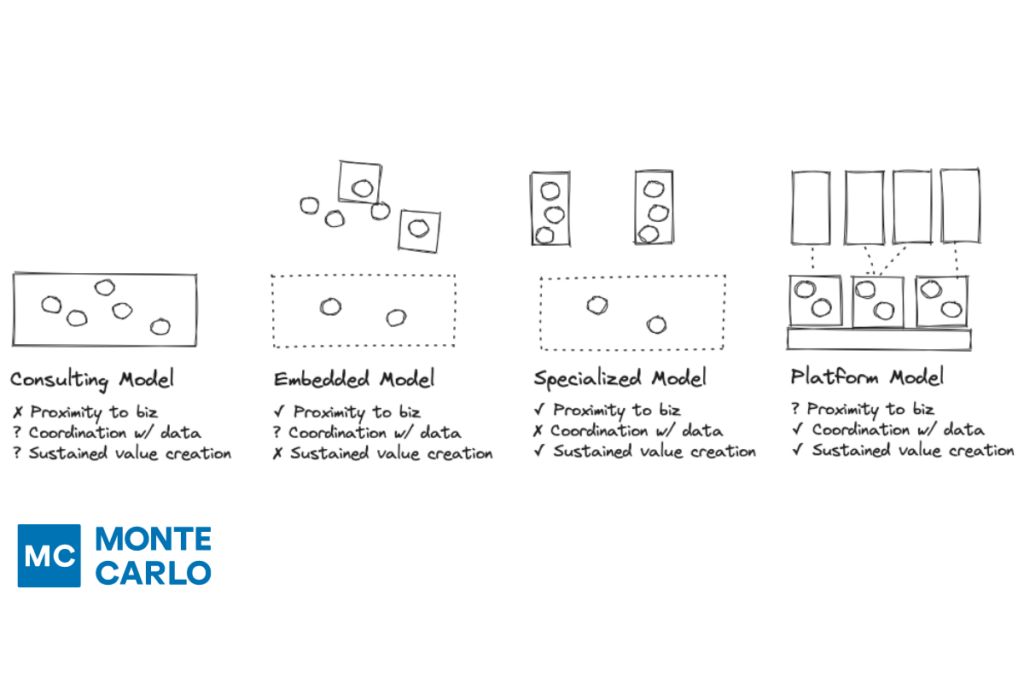
One of the most common mistakes I have seen in this regard is stretching your talent pool too thin in a rush to decentralize and embed across the company (perhaps within a data mesh). While you gain a better understanding and proximity to the business, sustained value creation is difficult.
There can be pockets of success, but these are often tied to and dependent on the talent of one or two self-starters. Data science talent is scarce, senior data science talent that can independently identify, prioritize, communicate, and execute high value projects is even more rare.
When those talented individuals depart, the institutional knowledge, code base, and project momentum often leave with them. Their surviving team members are forced to take on the role of an archeologist, attempting to discern the purpose and meaning of the artifacts left behind by these abandoned projects. Most times restarting from near scratch.
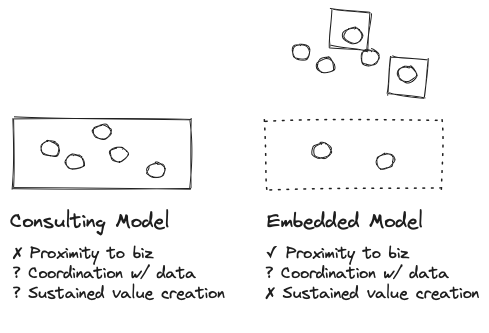
The consulting model has often been a more successful approach for smaller data science and machine learning teams. This consolidates a critical mass of talent that can be aimed at the highest priority projects. The potential downside to mitigate is you want to prevent the center of excellence from becoming a lab that produces gold plated models that a professor might love, but are not aligned to the business challenge at hand.
As a team grows bigger and ascends the maturity curve, slightly different organizational structures become more appropriate. The “specialized” model will typically focus data science and machine learning resources around a couple of high-valued problems, with teams deployed within the relevant business domain.
The most common expression of this occurs when machine learning is a core part of the product (perhaps personalization or fraud detection) and the association with the product or engineering team is more important than the association with the core data team. Often the core data team has its own investment in data science, largely independent from the specialized teams.
This model can be successful, but it does create inefficiencies and silos. For example, both central and specialized teams will typically have customized platforms with few shared services. The streaming event data within the product domain might benefit from being enriched by the custom data collected by the centralized team, but that connection might never be made.
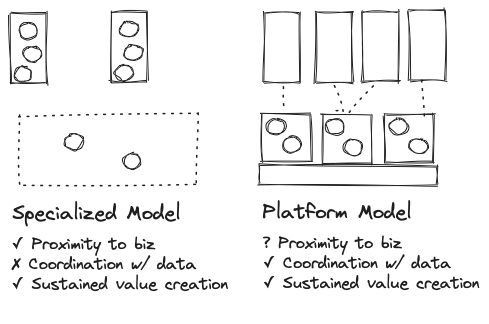
The other later stage organizational structure could be described as the “platform” model. Embedded and specialized models can suffer from a lack of visibility and cohesion across business domains, treating each data science problem with its own full-stack solution, despite inherent similarities in the type of problems being solved across domains.
The solution is to create some deliberate separation from business domains or verticals, so as to not overfit their operating model, as you would do with other horizontal platform teams.
A major benefit of treating machine learning as a platform pursuit is the capacity to invest in a shared platform infrastructure once you have demonstrated the value from each ML application, as it lowers the resource and cost to deploying and maintaining new applications. This investment should initially be small relative to the investment in applied teams, allowing them to operate relatively independently and pursue the long-term goals of their business partners.
In this platform model, a GenAI team could be created as one of the applied teams, with the mandate and engineering resources to tailor their stack as needed to deliver value, while coordinating with other platform teams to reuse infrastructure and standards that will deliver sustained value for the organization. I’d strongly recommend this model over trying to spread GenAI across many teams. Critical mass matters.
Lesson 2: Organize generative AI teams by use case not by business function
Recently, I had a conversation with a data leader at a media company that was the inspiration for this post. They told me their data science teams were organized by domain (media properties in this case).
Data science teams were working on the same types of projects within each domain, namely article recommendation algorithms. No doubt each domain benefits from the dedicated focus on their specific problems and each data science team benefits from the proximity to their respective business and editorial partners. But it helped highlight some of the downsides of this organizational structure; inefficient deployment of talent and a lack of shared infrastructure despite many teams solving the same types of content ranking problems.
At the New York Times, we found it effective to organize our data science teams around common problems. Once the model had been proven in one domain, it was generally more efficient to tweak and modify it to the unique inputs and constraints of another rather than having two teams create two models in parallel. It makes sense from a logical perspective as well, it always takes more time to build the prototype than the subsequent product.
Generative ai teams should be considered in the same vein. Have a team focus on a high value use case appropriate for the technology, perhaps personalized seat suggestions for an event marketplace, or language localization for a media site, then apply that solution to other domains where it makes sense.
Lesson 3: Focus on long-term value and hard problems
“Long-term” has a unique meaning in the world of tech and data, where the average shelf life of a chief data officer is about the same as a jar of peanut butter.
Will the objective still be a problem when it’s time for the project wrap party? Will it still be a need five years from now during which the new model can be iterated and find additional value?
The reality is, assuming you aren’t leveraging an off-the-shelf model, machine learning and Gen AI initiatives can be expensive (although LLMs are commoditizing rapidly). Developing a well trained and governed model to fit a use case can take months, or in some cases, even years.
The lift compared to other alternatives had better be worth it. For example, a machine learning model designed to optimize Facebook ad spending might sound appealing until you realize this is done natively within the ad platform.
That said, focusing on long-term value does not mean creating a roadmap with the first release scheduled for 2025.
Lesson 4: Partner generative AI teams with a business sponsor
So how can you ensure that your data science and generative AI teams are focused on business problems that matter? Pair them up with a business sponsor.
Finding innovative applications for new technology is unlikely to be a linear journey and detours should be expected. A strong partnership with a business sponsor acts as a compass ensuring the team never wanders too far from business value as they explore the frontier. I’ve found it also broadens the team perspective beyond the horizon to problems that run across teams.

A strong business sponsor will also keep the team well provisioned during their journey, unlocking resources and helping to navigate any difficult terrain involving internal processes or politics. Part of this navigation will likely require aligning roadmaps across teams to deliver a coherent back-end and front-end experience.
Since these initiatives are likely to span quarters, executive involvement is also critical to ensuring these projects aren’t killed prematurely.
Lesson 5: Understand data platform prerequisites
Building the machine that builds the machine is always more difficult than producing the end product. That’s true whether it’s a factory producing a car or a data platform used to develop and productionize large language models.
Business leaders will always have the business objective in mind and will frequently overlook the data platform investments required to get there. They aren’t being malicious, they are just relying on you, the data expert, to tell them what’s required.
For example, machine learning teams have invested in building or buying feature stores and MLops solutions. Not to mention the foundational investment in cloud data environments, data quality, and the surrounding bells and whistles.
For GenAI initiatives, much of the data platform and data pipeline architecture will remain the same (and if you haven’t yet invested in the modern data stack that’s the starting point). You can’t have a Gen AI project without discoverable, high quality data. However, there will be some additional solutions that are specific to LLM engineering like model hosting, caching, AI agent frameworks, and many others that haven’t even been invented yet.
Learn from the past or repeat it
There is no mistake about it Gen AI is a disruptive technology and learning to leverage it at scale will create a new corpus of painful lessons learned. However, there is no need to start from scratch. Structure your data science and generative AI teams for success in the long-run.
Curious about how data observability can help take your generative AI teams to the next level? Talk to us by scheduling a time using the form below!
Our promise: we will show you the product.
Read more posts.





