Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Snowflake and Databricks Summits 2023: Feature Announcement Recaps and Comparisons


Michael Segner
Michael writes about data engineering, data quality, and data teams.
Keep your eyes on this space throughout the week. Thanks to our correspondents in Las Vegas and San Francisco, we will be updating and analyzing all the major announcements across both conferences each day.
Table of Contents
Setting the stage
To the consternation of SWAG lovers everywhere, the two biggest data conferences are happening the exact same week of June 26th, 2023: Snowflake Summit and Databricks Data + AI Summit. .
The two conferences are happening at a key inflection point for both companies and the data industry at large. Databricks likely has their eye on going public, and targeting Snowflake’s record as largest tech IPO of all time. Snowflake is looking to continue their 2023 momentum and climb to those previously unprecedented heights.
Both companies, and the industry as a whole, are experiencing macroeconomic headwinds in the form of persistently raising interest rates, as well as tailwinds in the form of a GenAI gold rush and continued unsatiated demand for data across the enterprise.
Pre-conference Rumblings
The industry conference has been largely shaped by the consumer technology world where the latest and greatest features of the new iPhone or car take center stage.
It’s not quite as applicable in today’s B2B SaaS era where new features are developed and shipped in an agile manner 24/7/365. Long gone are the days of celebrating the release of Windows ‘95.
Some companies will hold new features back to ensure they have big announcements for their conference while others will use their conference to bring attention to recently shipped features. Last year, Snowflake chose a hybrid approach covering many of their previous announcements such as their Steamlit acquisition but also waiting until the morning of their keynote to announce Python compatibility in Snowpark.
This year, it looks like Databricks may be tipping their hand with some recent pre-conference announcements (see an image from one of their pre-conference emails below) while Snowflake is keeping some cards close to the chest, having not announced a feature update via press release since April 13, 2023.

Either way, we can start to read the tea leaves of some of the upcoming feature announcements below.
Thoughtspot Acquires Mode
In what could be an omen for the industry, Thoughtspot announced its acquisition of Mode for $200 million on the Monday prior to both conferences officially kicking things off. It is interesting to note Thoughtspot is well positioned as a potential solution for providing additional semantic meaning that may enhance the performance of LLMs and GenAI (it’s not a coincidence that AI is mentioned in the press release 18 times).
Many data pundits, including Mode’s own co-founder Benn Stancil, predicted a wave of consolidation would wash across data vendors orbiting the Snowflake and Databricks worlds. It remains to be seen if this event is a harbinger of more to come or as one of my colleagues said with tongue in cheek, “the great BI consolidation wave of 2019 is finally complete.”
GenAI Strategies: Databricks Acquires MosaicML & Snowflake Announces Microsoft Partnership
The Wall Street Journal got the exclusive scoop that Databricks acquired AI startup MosaicML for $1.3 billion on Monday as well.
This big news highlights the opening move of Databricks’ GenAI strategy, which is to enable its customers to more cost-effectively build their own large language models (LLMs) on its platform. It’s also a natural and smart extension of their Marketplace strategy that will not only help customers share machine learning apps, but LLM models as well.
Databricks is betting that its core users–which have leaned more data science than data analytics and more build vs buy–will be more interested in building and fine tuning their own models for specific use cases rather than leveraging the services of larger models such as OpenAI’s ChatGPT or Google’s Bard.
Snowflake may be giving early signals that it will be mainly focused on an alternative bet–one where the advantages of large pre-built LLM models overcome the desire to build and customize. On Monday it announced an expanded partnership with Microsoft, which has made significant investments in OpenAI.
While much of the release focuses on joint go-to-market strategy, this section seems particularly relevant:
“The partnership aims to enable seamless integration between Snowflake’s Data Cloud and Microsoft’s Azure ML and leverage the capabilities of Azure OpenAI and Microsoft Cognitive Services. By integrating Azure ML, joint customers will have access to the latest frameworks, streamlined development to production workflow for machine learning, and integrated CI/CD processes.”
This Medium post earlier this month discussing how to leverage Snowflake Tasks and LLM’s to transform JSON at scale, also seems apropos to how Snowflake might integrate LLM offerings directly within its platform.
Lakehouse Apps = Steamlit Apps?
Speaking of Marketplace, the week prior to the conference Databricks announced Lakehouse Apps, a new way for developers to build native secure applications for Databricks. This can be seen as a new quiver in their arrow in their battle to become the central “data app” store.
At first glance, this announcement seems to be equivalent in purpose to Snowflake’s March 2022 Streamlit acquisition and a way to reach feature parity– whereas the MosaicML acquisition is an effort to get a step ahead.
Movements in Data Sharing
As fun as it is to dissect the differences in the strategy and innovations unveiled by Snowflake and Databricks, what’s most striking are the similarities. The future of these companies will feature a foundation built on GenAI integration, data app builders/marketplaces, and data sharing.

Data sharing was a large focus of both companies last year. Snowflake’s keynote focused on how Secure Data Sharing and their Marketplace would disrupt app development, while Databricks unveiled Delta Sharing.
Snowflake is developing industry specific “data clouds” to increase usage of this sharing feature by combining industry relevant data with participation of key players within the vertical supply chain. Databricks is also trying to build critical mass for their sharing service, announcing the week prior to the conference that Delta Sharing will be open and available across services external to Databricks.

Of course, a look at the fine print will reveal that these users still need to be on Delta tables and leveraging Unity Catalog, but it’s a welcome announcement for many data engineers.
First Up: Snowflake Keynote
Snowflake’s keynote and feature blitz started on Tuesday, a day earlier than Databricks.
This year’s Snowflake Summit is a bit more spread out than last, with the main keynotes taking place across the way in Ceasar’s Palace. While not far as the crow flies, it’s a scientific fact that each Vegas meter takes four times longer to walk.

That didn’t stop conference attendees from locating, descending, and swarming Ceasar’s. The line for the keynote started early and the buzz of anticipation was palpable, and only grew as people began talking their seats.
Frank Slootman: An AI Strategy Requires a Data Strategy
Snowflake CEO Frank Slootman kicked off the keynote and immediately disarmed the audience of AI skepticism/weariness like a pro: “There is a drinking game, every time I say AI you have to do a shot.”
He then launched into his latest stump speech positioning Snowflake’s role in the era of Gen AI.
“We always say in order to have an AI strategy you have to have a data strategy….If you don’t have your data strategy wired in, you can’t just keep going with the past. Real choices have to be made – you can perpetuate what you’ve been doing in the past…or fundamentally shift,” he said.
The Snowflake CEO wasted no time outlining Snowflake’s evolution and expanded ambition, “Most in this room are doing data warehousing. These days we view data warehousing as a particular kind of workload.” He then went on to list Snowflake’s data lake, transactional (Unistore), hybrid, and collaborative (Data Sharing) capabilities.
Of course, he couldn’t resist adding a jab at a competitor as well saying, “A lot of efforts in Snowpark have been focused on retiring legacy Spark jobs. If you’re looking to save some money, save 2-4x on data engineering because our interpretation of Spark in Snowpark, it will run it cheaper, simpler, and more secure. Free money to be had.”
He then quickly outlined the three big announcements we would be seeing and how they tied back to the conference theme of “No Limits On Data” (which come to think of it might have been my cellphone carriers tagline for a while too). These were:
- Data: Expanded Iceberg table support.
- Applications: Snowflake native apps in their Marketplace.
- Workloads: Snowpark Container Services, a huge expansion of Snowpark where containerization will help “scoop up” any function that already exists and run it in Snowflake. These containers will also host LLM models to be addressed by the applications themselves.
Notably, the data and application announcements are expanded functionality to build critical mass around some of last year’s major announcements, but Snowpark Container Services sticks out right away as exciting new capabilities that will have an immediate impact on the data world.
Also interestingly, Snowflake seemed to learn their lesson from last year’s keynote. Rather than have co-founder, Benoit Dageville, come out to repeat many of the announcements made by Frank, he made a quick panel appearance with Sridhar Ramaswamy, SVP Snowflake, Founder of Neeva, and Mona Attariyan, Director of AI/ML, to simply reiterate and reinforce the implications of those announcements.
From this point forward it became the Christian Kleinerman show (and no complaints here), as the Snowflake senior vice president of product took us from compelling demo to compelling demo.

Unified Iceberg Tables
Christian started with a quick overview, and reminder really, of Snowflake’s support of Iceberg tables. He discussed how customer feedback was focused on not having any tradeoffs in terms of performance between managed and unmanaged Iceberg tables.
He then announced Unified Iceberg Tables: a single mode to interact with external data with no tradeoffs whether or not the coordination of writes happens by Snowflake or a different system.
Document AI
Christian’s next announcement may have been the buzziest of the buzzy: Snowflake’s Document AI. The new service combines technology from Applica, which Snowflake acquired in 2022, with a proprietary large language model to extract and better understand the unstructured data (text) within documents.
Christian showed the power of this feature by discussing a fictional snow goggle company that uses forms to inspect equipment. They can use Document AI to run queries on the data to determine what inspections passed or failed, who completed the inspection, and more. The data can then start being used to train the AI model.
What stands out about Document AI in a sea of Gen AI announcements is its ruthless practicality. This is not a SaaS vendor quickly smashing a square GenAI feature into a round hole to launch their cool marketing campaign. The applications for documents like invoices and contracts seems particularly exciting.
Some Governance Stuff
New governance features got quick lip service almost like an announcement amuse-bouche. So we too will list them quickly. They were:
- Query Constraints: Snowflake administrators can now define constraints top control which datasets can be accessed and leveraged for analytics and when.
- Improved Data Clean Room with Differential Privacy in SQL and Python: for Snowflake users with more extensive privacy needs, Snowflake announced an all-new differential privacy feature to boost data security during collaboration within Snowflake clean rooms.
Core Engine Updates
Just like last year, VP of Engineering, Alison Lee, took the stage to discuss updates to Snowflake’s core engine.
Last year, I mentioned how these updates are often overshadowed by flashier new features but often have a bigger impact on customers. This year, I can say these updates weren’t overshadowed.
The expanded geospatial support and 15% improvement in query duration was cool, but the talk around new warehouse utilization metrics got an audible excited reaction from the crowd and it wasn’t hard to see why. We’ve written about Snowflake cost optimization strategies previously, and made note about how selecting the most cost efficient virtual warehouse for each workload was a process of trial and erorr.
Mihir Shah, CIO and Enterprise Head of Data, Fidelity took the stage to discuss how they have optimized costs in their envirionment of 800 datasets and 7,500 users by ingesting data once and sharing multiple views from there. That way multiple databases are eliminated. “So finance still gets view what they used to see and so does marketing but everybody’s looking at the one single data set.”
Streaming Pipelines and Dynamic Tables
As little as two years ago you might say that Snowflake is designed for analytical workloads while data lakes are more geared towards real-time and streaming use cases. That is clearly no longer the case as Christian highlighted Snowflake’s Snowpipe streaming capabilities, the ability to ingest data using a Kafka connector, entering general availabillity.
As part of this discussion Christian also introduced the concept of Dynamic Tables. These were introduced last year as “Materialized Tables.” These tables seek to solve many of the problems within modern data pipeline architecture: namely the issues that can be introduced through complicated data orchestration and transformation processes.
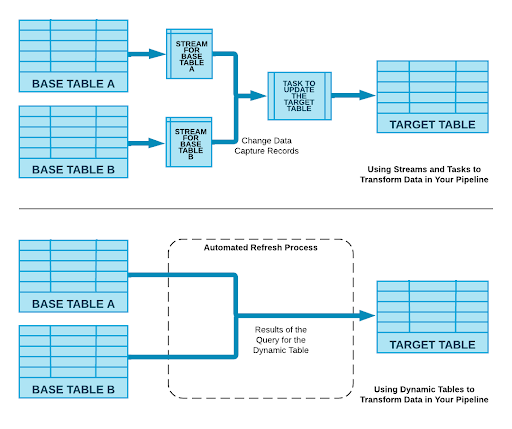
You can think of Dynamic Tables as a table combined with SQL transformation code run regularly with Snowflake task. So unlike other transformation tools, this option still requires a level of SQL expertise. However, Christian did discuss text to code capabillities currently in development where a large language model will automatically create the SQL code required.
The Finale: Native Applications and Snowpark Container Services
The final announcements focused on what might be Snowflake’s biggest bet: becoming the iPhone app store but for data. Their marketplace and concept of native snowflake apps (hello Steamlit!) was unveiled last year, but this is clearly a multi-year effort that will require multiple pushes to reach critical mass.
To that end the press release mentions:
“Snowflake Marketplace continues to scale as the first cross-cloud marketplace for data and apps in the industry with over 36,000 unique visitors every month. Over the past year, Snowflake Marketplace has increased providers with publicly discoverable listings by 66 percent (year-over-year as of April 30, 2023), with over 430 providers publicly discoverable (as of April 30, 2023) and more collaborating privately.”
This year, Snowflake highlighted their new model registry designed to help store, publish, discover, and deploy ML models. But the main event was clearly Snowpark Container Services.
As Christian described the genesis of the service: “When we did Snowpark, we learned a lot about programming languages in the world. What we wanted to do is accelerate time to value. More run times. More languages. More libraries. The fastest way to do it was by introducing Snowpark Container Services.”
Snowpark Container Services essentially expands the types of workloads that can be brought to data including data apps and hosted LLMs but within a governed container with multiple related services from partners such as NVIDIA, Alteryx, Astronomer, Dataiku, Hex, SAS, and more.

At this point, we were starting to wonder how Snowflake was going to end with anything flashier than what they had previously announced. Christian did not disappoint by introducing what was one of the most interesting and unique tech keynote moments we’ve seen.

Ten demo engineers ran 10 live demos on Snowpark Container Services running concurrently behind a translucent screen (as you can see in the image above).
While it was impossible to fully track and understand each story being told, that wasn’t the point. The power and extensibility of the service was on full display leaving attendees to file out with an inspired sense of what might be possible.
Next Up: The Databricks Keynote

Now let’s go from the dry Vegas heat to the overcast San Francisco drizzle. Following a puff of smoke and a red lazer light show, Databricks CEO, Ali Ghodsi, stormed the stage.
The start included a few stumbles and over-promises about how the audience was going to use technology to “make everyone smarter, cure diseases, and raise the standard of living,” before the executive caught his stride. The opening message was that the audience didn’t need to fear the far reaching and unpredictable impacts of AI because we are part of Generation AI. We are going to lead the revolution.
Ali then paid homage to Databricks and the conferences open source origins. He thanked the community for their participation in making Spark, Delta, and MLflow a success. That got an applause line that reminded you that there still is a real sense of community and higher level of loyalty than you might find with other data vendors.
Ali then brought Microsoft CEO, Satya Nadella, onto the stage virtually, “via Skype.” The crowd was clearly excited, showing just what a rockstar Satya has become within tech circles.
Satya Nadella: The Importance of Responsible AI

Satya loomed large over the stage and continued the theme of the power of AI for good. You know a technology is powerful when the first two portions of the keynote are dedicated to easing anxieties and concerns before the specific applications and features are unveiled.
Satya discussed how Microsoft has been working on AI for a long time and was quick to jump on the AI revolution in part due to observations about its workload structure. AI training workloads are very data heavy and synchronous, so from an infrastructure perspective, Satya wanted to ensure that Azure was the best place for those profitable workloads.
He also talked about how he thinks about mitigating the possible negative impacts of Gen AI in three separate tracks.
- An immediate track focused on combating misinformation with technologies like watermarking and regulation around distribution.
- A medium term track focused on how to ground models to prevent issues with cyber security and bio risks.
- A long-term track focused on making sure we don’t lose control of AI.
It was an avuncular discussion that positioned these issues largely as alignment challenges that can be solved in part by technology and the people in attending the keynote.
Democratizing AI with the Lakehouse
Our MC, Ali, then returned to the stage to focus on the question of how AI can best be democratized. We heard the traditional Databricks thesis (which doesn’t make it any less revolutionary or insightful), that AI has been held back by two separate parallel worlds.
These are the world of data and the data warehouse that is focused on using structured data to answer questions about the past and the world of AI that needs more unstructured data to train models to predict the future. Databricks believes these worlds need to merge (and their strong preference would be that merger takes place in the Databricks Lakehouse).
He then provided the number of Lakehouse customers, 10,000 active users, for the first time in the company’s history. Again, the surprising applause break was a reminder that the audience really feels a bond of community thanks to Databricks’ open source roots.
JP Morgan Chase: Leveraging ML at Scale

Ali then welcomed Larry Feinsmith, head of global tech strategy at JPMC, to the stage for what felt like a relatively spontaneous fireside chat (for a major keynote that is).
Larry focused on a really important point that would be echoed by other Databricks speakers: the competitive advantage of ML and AI will be a company’s proprietary first party data (and intellectual property). Or as he put it, “What’s additive of [AI] is training it on our 500 petabytes, using our Mount Everest [of data] to put it to work for our customers.”
He also made some insightful points of cost efficiencies at scale, specifically a scale of 300 AI production use cases, 65 million digital customers, and 10 trillion transactions. From his perspective, this can only be done efficiently with platforms. At JPMC they leverage a ML platform called Jade for managed data and InfiniteAI platform for data scientists.
Larry’s point was that the Lakehouse architecture is transformational because of the capabilities it brought of the data it allowed JPMC to not have to support two stacks and move data around as little as possible.
Larry’s portion of the keynote also featured the biggest laugh of the day. He created a bit of tension in the room from claiming ChatGPT has made him the same as all of the Python, Scala, and SQL developers present, which was expertly diffused by Ali later with a quick quip after Larry’s pitch for developer talent to join his team at JPMC: “You don’t even have to know programming, you only have to know English.” It was a nice line that reassured folks their programming skills weren’t obsolete just yet.
LakehouseIQ: Querying Data In English Via An LLM

Then came one of Databricks’ most ambitious feature announcements: LakehouseIQ.
Ali showed the evolution of how the Lakehouse started with technical users with Scala, then Python, and then SQL. The next step was all enterprise users in their native language.
He then passed the mic to Databricks CTO, Matei Zaharia, to introduce LakehouseIQ, which likely made the cornucopia of startups working on the same problem immediately start squirming.
Matei was incredibly effective at pointing out how incredibly difficult the problem of query data with natural language was because each company has its own jargon, data, and domain structures. For a Databricks employe to ask the data “how many DBUs were sold in Europe last quarter,” the LLM needs to understand that a DBU is a unit Databircks uses to price, that Europe might be broken up into two sales regions, and when exactly Databricks has its quarters.
LakehouseIQ solves this by taking signals from organizational usage (how popular is this asset?), which it can do because of the information Databricks can pull from dashboards and notebooks of end users. It works through Unity Catalog to understand these signals and build models to return a response. At the moment, LakehouseIQ works best as an interface that goes back and forth between English prompts and refining prompts and the SQL/Python query that generates the data–but the end goal of only requiring English was clear.
Both Matei and Ali stressed that LakehouseIQ is in its infancy and something Databricks is actively working on to improve, but the future of querying your data similar to how you might Google a question didn’t seem as far away as it did yesterday.
MosaicML: The Machine To Build Your GenAI Models

Ali then introduced MosaicML, the $1.3 billion dollar acquisition Databricks announced earlier in the week, and its CEO Naveen Rao.
Naveen painted an exciting picture of just how accessible and affordable it is for companies to build their own Gen AI models. To Naveen (and Databricks), the future of Gen AI belongs to private models rather than the Chat-GPT and Bard’s of the world for three reasons: control, privacy, and cost.
To that end he showed how an effective model of 7 billion parameters can be created in days for around $250,000 or a 30 billion parameter model for around $875,000. He then shared the story of Replit, the shared IDE, and how it produced their own state of the art model in 3 days that acts as a coding co-pilot. As a recent Replit user, I can attest that the auto-complete and error highlights are very helpful.
The bigger picture here is that just like Databricks and Snowflake needed an easy way for users to create data applications in order to use their application store, they need an easy way for their users to create GenAI models to now host and monetize those on their marketplaces (but more on that later).
LakehouseAI: Vector Search, Feature Serving, MLFlow Gateway

Databricks introduced cool new functionality as part of their new LakehouseAI feature. The technical labels might be a miss, as Databricks co-founder and speaker for this portion of the event, Patrick Wendell remarked, “Let me explain what they mean and then the rest of you can clap.”
In a nutshell, LakehouseAI will help users solve three of the most difficult challenges in deploying AI models:
- Prepare the datasets for ML
- Tuning and curating the models
- Deploying and serving those models
The vector search and feature serving components will help unlock the value from unstructured data within an organization by auto-updating search indexes in unity catalog and accessing pre-computed features in realtime to feed the model.
He then used the example of a customer support bot who would get the request to “Please return my last order,” and understand when the order took place and the rules for returns so it could then say, “You made this order in the last 30 minutes, would you like me to cancel it for you?”
Patrick also talked about Databricks LakehouseAI features to allow users to easily compare and evaluate Gen AI models for specific use cases–pointing out that about 50% of Databricks customers are exploring SaaS models and 65% are exploring open source (meaning a decent percentage are exploring both types).
He then wrapped up by talking how Databricks also supported the deployment of these models with GPU support for fine tuning AI models and Lakehouse Monitoring for monitoring the drift and model quality. (Of course it’s important to note the data observability platforms like Monte Carlo will play helpful roles in monitoring the underlying data quality and data pipeline performance).
Following Patrick was a quick customer story vignette featuring JetBlue, one of the best data teams on the planet. Sai Ravuru, senior manager of data science and analytics, talked through how the company has used governance capabilities to govern how its chatbot will provide different answers based on the person’s role within the company.
He also discussed the critical operational decision support their BlueSky model is able to provide their front-line operational staff by simulating the possible outcomes of a decision over a 24 to 48 period in the future. Very cool stuff.
Better Queries With LakehouseAI

Ali returned to the stage in a brief interlude to provide some updates on usage across the Lakehouse:
- Delta Live Tables have grown 177% in the last 12 months. The momentum of streaming applications is lost a bit in the hype of Gen AI.
- Databricks Workflows reached 100m weekly jobs and are processing 2 excabytes of data per day.
- Databricks SQL or data warehouse has 4,600 customers actively using it since General Availability and is reaching about 10 percent of their revenue.
This was a nice transition to bringing Reynold Xin, another Databricks cofounder, to the stage to talk about how the lakehouse is also actually an awesome data warehouse thanks to LakehouseAI.
Reynold started with a warning that it was about to get technical, but he did a good job of not getting too deep in the weeds. He framed the problem LakehouseAI Engine can solve very well with a quote from a 1979 paper on data warehouse technology (OK maybe it did get a little technical):
“Future users of large data banks must be protected from having to know how the data is organized in the machine.”
He then asked who had to partition or cluster a table and if that work actually led to an increase rather than decrease in cost. Naturally, most of the room raised their hands.
He then discussed the tradeoffs implicity in data warehouse query optimizers that can choose two of the three between fast, easy, or cheap. He walked through a quick explainer of how data warehouse queries worked, but the punchline was that the process was overly simplistic and problematic…but also a great problem to be solved by AI.
He then pointed out how Databricks has more data on more diverse workloads than any other company. Databricks took this huge amount of query patterns to train what they call PredictiveIO to “reinvent data warehousing.” Essentially, their model predicts where the data might be and speeds up queries without manual tuning. The numbers Reyond cited were Merge 2-6x faster and Delete 2-10x faster than other services.
There is also an automatic data layout optimization component that thinks about how to cluster and partition based on your workloads nad picks the right cluster for you with automatic file size selection, clustering, run optimization, and more. The numbers here were 2x faster queries and 50% storage savings.
Finally, Reynold talked about smart workload management and how AI can help ensure that when a small job and large workload are running at the same endpoint, users wouldn’t have to worry about large workloads slowing down the smaller.
Delta Lake 3.0 and Uniform

Ali came back on stage to share what was one of the most surprising announcements. Yesterday, the data world (outside of data warehouses) essentially had to choose between Delta, Hudi, or Iceberg table formats. Your choice essentially locked you into that table’s ecosystem, despite the fact that under the hood all of those table formats are run on Parquet.
Today, with Delta Lake 3.0, when you write in a Delta table you will now create the underlying metadata in all three formats: Delta, Hudi, and Iceberg. It’s a big step forward that the community will love. Ali hinted at Databricks motivation, “Now everyone can just store their data and do AI and all these things with it,” i.e. let’s get rid of the friction and get to the cool stuff!
The New Public Preview Features For Unity Catalog
This time Matei returned to the stage to talk about the new features of Unity Catalog including Lakehouse Federation, Lakehouse Monitoring, and a MLFlow model registry. These were described in the buckets of: enterprise wide reach, governance for AI, and AI for governance.
In summary, Lakehouse Federation will help you discover, query and govern your data wherever it lives. It will connect the data source’s unit catalog and set policies across them. In the near future, it will even push those policies down into warehouses like MySQL.
The MLFlow model registry is self-explanatory, and Lakehouse Monitoring will make data governance simpler with AI for quality profiling, drift detection, and data classification.
The Conclusion: Delta Sharing and Lakehouse Apps
Delta Sharing and Lakehouse Apps, the stars of last year’s show, were also quickly highlighted. Creating the “iphone app store” but for data is a key foundation for Databricks go-to-market strategy.
The typical benefits of not having to move data and avoiding security reviews were extolled, but the big news here was the ability to not only offer/monetize datasets and notebooks, but now AI models (thanks to MosasicML).
Rivian then essentially wrapped up the Databricks keynote, which was an interesting choice. They discussed how data and AI revolutionized their business model and will help them create more reliable cars and help their customers predict needed maintenance.
Finally, after more than two hours, Ali returned to the stage a final time for a quick recap along with a plug for attendees to “go out and get our electric venture vehicle.”
Interested in how data observability can help your data quality on BOTH Snowflake and Databricks? Talk to us!
Our promise: we will show you the product.
Read more posts.