Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 5 Layers of Data Lakehouse Architecture Explained

Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
You know what they always say: data lakehouse architecture is like an onion.
…ok, so maybe they don’t say that. But they should!
Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructured data.
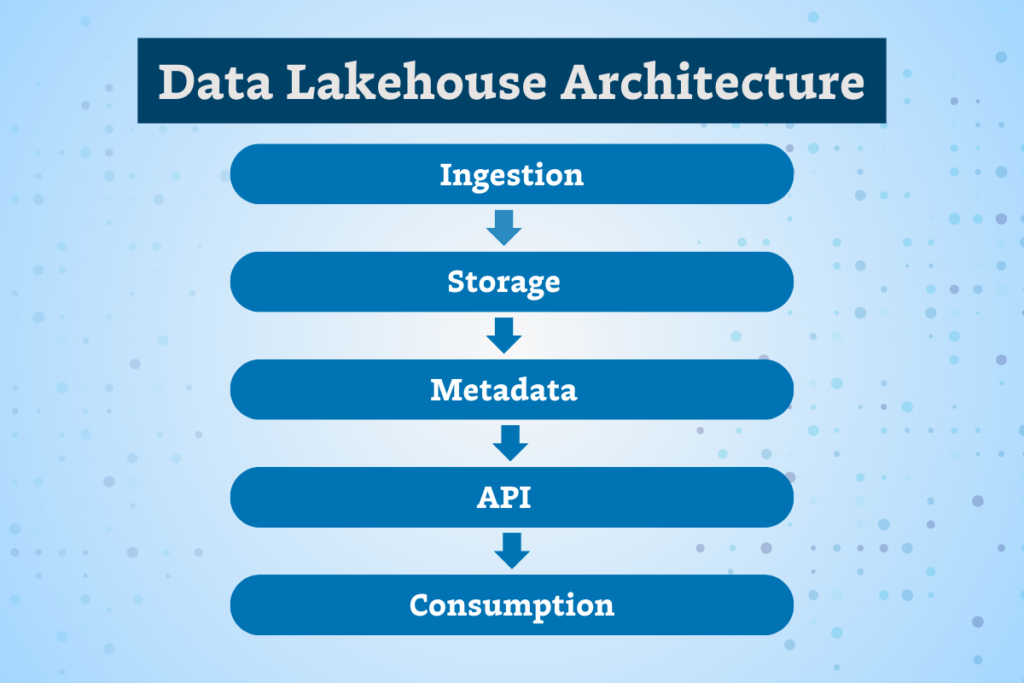
In this article, we’ll peel back the 5 layers that make up data lakehouse architecture: data ingestion, data storage, metadata, API, and data consumption, understand the expanded opportunities a data lakehouse opens up for generative AI, and how to maintain data quality throughout the pipeline with data observability.
Table of Contents
What is data lakehouse architecture?
Data lakehouse architecture is an increasingly popular choice for many businesses because it supports interoperability between data lake formats. It supports ACID transactions and can run fast queries, typically through SQL commands, directly on object storage in the cloud or on-prem on structured and unstructured data.
The data lakehouse’s semantic layer also helps to simplify and open data access in an organization. Data consumers downstream, like data analysts and data scientists, can try new analytical approaches and run their own reports without needing to move or copy data – reducing the workload for data engineers.
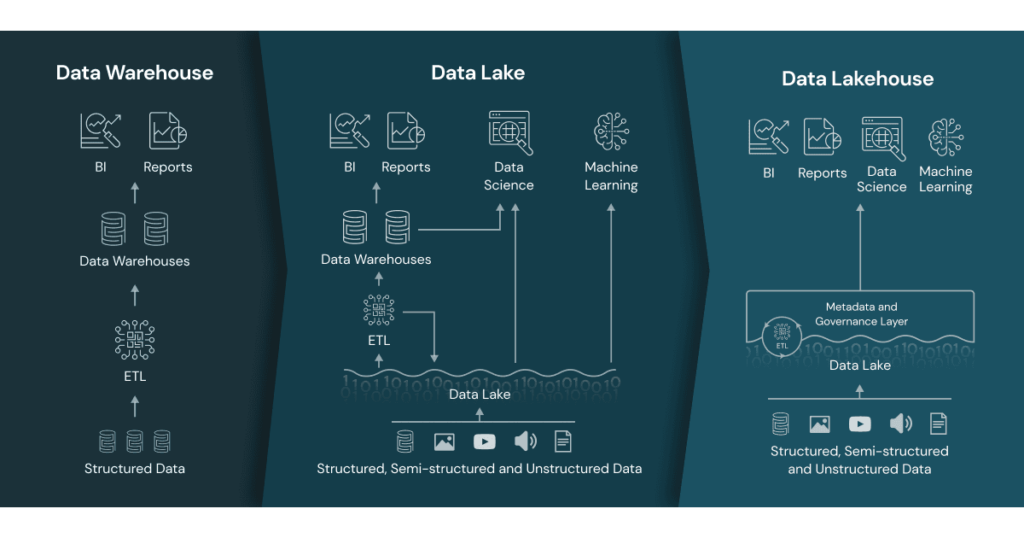
Innovations in data lakehouse architecture have been an important step toward more flexible and powerful data management systems. Data lakehouses, like Databricks’ Delta Lake, Amazon Redshift Spectrum, and now Snowflake for Data Lakehouse, help to unify data warehousing, machine learning, and analytics.
Increasingly, data warehouses and data lakes are moving toward each other in a general shift toward data lakehouse architecture. Snowflake announced Snowpipe for streaming and refactored their Kafka connector, and Google announced Pub/Sub could now be streamed directly into the BigQuery. Databricks announced Unity Catalog to enable teams to more easily add structure like metadata to their data assets.
It seems that the lines between data warehouses and data lakes are continuing to blur, melding into architecture that looks more and more like that of data lakehouses every day.
The 5 key layers of data lakehouse architecture
Storing structured and unstructured data in a data lakehouse presents many benefits to a data organization, namely making it easier and more seamless to support both business intelligence and data science workloads. This starts at the data source.
1. Ingestion layer
The ingestion layer in data lakehouse architecture extracts data from various sources, including transactional and relational databases, APIs, real-time data streams, CRM applications, NoSQL databases, and more, and brings them into the data lake.
At this layer, an organization might use tools like Amazon Data Migration Service (Amazon DMS) for importing data from RDBMSs and NoSQL databases, Apache Kafka for data streaming, and many more.
2. Storage layer
The storage layer in data lakehouse architecture is–you guessed it–the layer that stores the ingested data in low-cost stores, like Amazon S3.
With object storage decoupled from compute, organizations can use their preferred tool or APIs to read objects directly from the storage layer using open file formats, like Parquet, and metadata, where the schemas of structured and unstructured datasets are kept.
3. Metadata layer
The metadata layer manages and organizes the metadata associated with the data that’s been ingested and stored. Metadata includes various information and insights about data, including orchestration jobs, transformation models, field profile, recent users and changes, past data quality incidents, and more.
The metadata layer also allows for the implementation of features like ACID transactions, caching, indexing, zero-copy cloning, and data versioning. And schema management and enforcement allows data teams to preserve data integrity and quality by declining writes that don’t fit the table’s schema and changing a table’s current schema to ensure it’s compliant with dynamic data. Data lineage also enables a data team to track the provenance and transformation of data to understand how it has evolved.
4. API layer
APIs (application programming interfaces) enable analytics tools and third-party applications to query the data stored in the data lakehouse architecture. With an API call or integration, an analytic tool understands what datasets are required for a particular application and how to retrieve them, transform them, or write complex queries on the data.
In addition, APIs also allow applications to consume and process real-time data, like streaming data, immediately. This means teams can process data to derive analytics in real-time, especially for data streams that are constantly updated, refreshed, and changing.
5. Data Consumption Layer
The consumption layer enables downstream consumers, like data scientists, data analysts, and other business users to leverage various tools, like Power BI, Tableau, and more to use their client apps to access the data stored in the data lake and all of its metadata.
All users can utilize the data in the lakehouse to carry out the analytics tasks they need, like building dashboards, visualizing data, running SQL queries, running machine learning jobs, and more.
Maximizing GenAI potential with data lakehouse architecture
Data lakehouses open up key opportunities for enhancing generative AI. The capabilities and structure of a data lakehouse can enable data teams to leverage the full scope of the data resources for their generative AI applications, allowing them to more effectively generate content, insights, and dynamic prompt responses.
To get the most out of their generative AI applications, there are several tools data teams use to employ on top of their data lakehouse, including vector databases to aid in reducing hallucinations, AutoML to streamline machine learning deployment, LLM gateways for integration, prompt engineering tools to improve stakeholder engagement and communication, and robust data monitoring capabilities, like data observability tools, to ensure high-quality data is going into the GenAI model–and as a result, high-quality responses are being generated.
Data observability in the data lakehouse
Data lakehouse architecture is a prominent innovation in data management that continues to evolve. There are many benefits for organizations, including a unified access layer for analysts, data warehouse and lake consolidation, an opportunity for departmental lake houses, support for FinOps, data mesh support, and much more.
As data lakehouse architecture continues to become more widely adopted, teams will need to ensure they have the tools in place to monitor the data that’s stored, transformed, and queried in the lakehouse. Data observability will play a key role in monitoring and maintaining the data quality of the datasets within the lakehouse. Without this security measure in place, data teams can lose all the benefits of the data lakehouse, instead ending up with a well-managed lakehouse of low-quality data… and that’s not useful for any data consumer.
To learn more about the value of data observability for data lakehouse architectures, talk to our team.
Our promise: we will show you the product.
Read more posts.