Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Provenance vs. Data Lineage: What’s the Difference?


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
What’s something you never want your data to be? Mysterious.
The best starting place to make sure you really know your data is, well, your data’s starting place – wherever that may be. For data teams, it’s essential to know your data from the source throughout its entire lifecycle. But, as data moves and is transformed through the pipeline, it can become increasingly complex to trace its journey. So, how can data teams know this information?
Enter: data provenance and data lineage.
Data lineage is a visual tool that tracks the movement and transformations of data through various systems, processes, and applications.
Data provenance is the record of metadata from data’s original sources, providing the historical context and authenticity of data.
While both data provenance vs. data lineage are mechanisms for understanding data at early stages, they differ in use cases. Data provenance is useful for validating and auditing data. Data lineage is useful for optimizing and troubleshooting data pipelines.
Let’s dive deeper into the definitions of data provenance and data lineage, what they’re used for, and why they’re so important for data teams.
Table of Contents
What is data provenance?
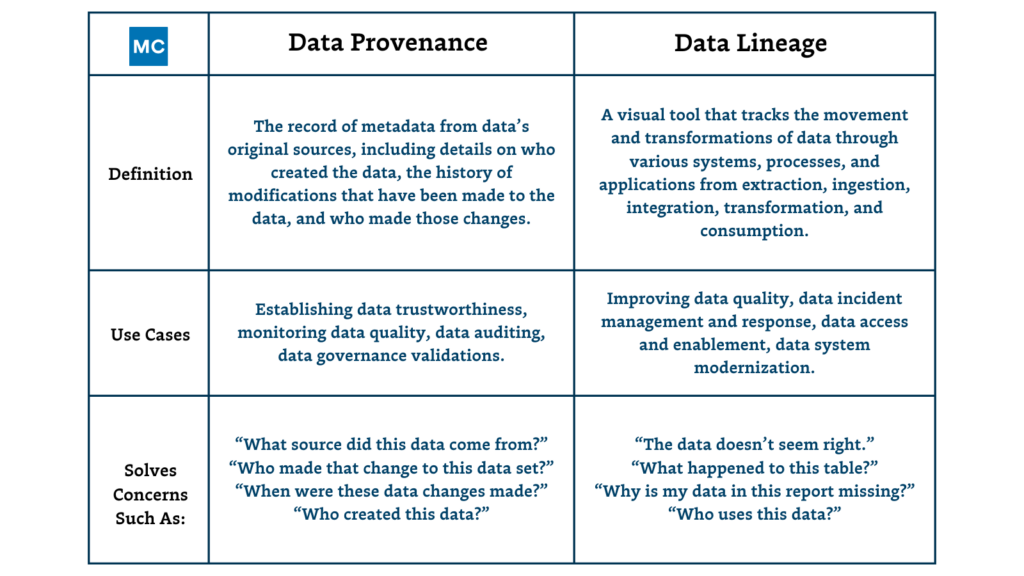
Data provenance is the historical record of data from its original sources by capturing metadata of data’s changes throughout the lifecycle. Data provenance is concerned with authenticity; it provides details such as who created the data, the history of modifications that have been made to the data, and who made those changes.
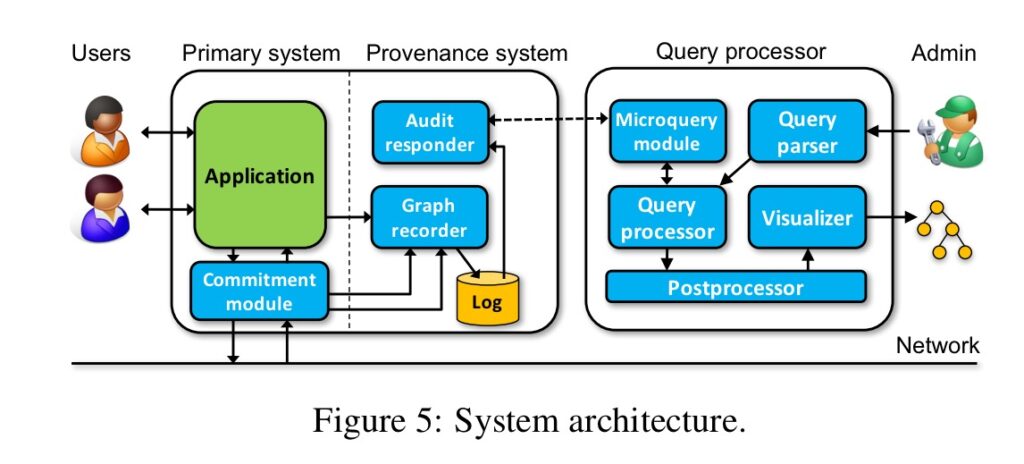
The role of data provenance in ensuring data integrity and authenticity
Understanding data provenance is key to verifying the authenticity of data, capturing and validating data reliability, and maintaining data integrity. When it comes to data provenance vs. data lineage, data lineage is more concerned with the transformations of data, while data provenance is concerned with the original historical data source, making it useful for auditing and validating data.
Data provenance use cases
Let’s look at some common data provenance use cases:
- Building data trust: Data provenance helps establish data trustworthiness. Just as people should validate their sources of information before accepting something they learn as fact, teams across an organization also need to be confident that the source of the data they’re using is reliable and authentic. Data provenance provides that data origination audit. If you can’t trust the data source, chances are you can’t trust the data, even if it’s already been transformed and loaded throughout the pipeline.
- Monitoring data quality: Data provenance is extremely useful when it comes to being able to monitor the data quality “paper trail.” If the data quality in a particular stream has changed or worsened, data provenance can help you pinpoint where the discrepancy originated. For example, maybe a change in the source data is causing a null value in a column.
- Data auditing: No one loves being audited, whether by the IRS or by the finance team. But, if an audit must be done, data provenance makes it easier to understand where data originated from, and what form it took before it was transformed. Especially when it comes to highly secure or regulated data, data provenance can provide data transparency when it’s most valuable.
There are several useful data provenance tools on the market, including CamFlow Project, Kepler scientific workflow system, Linux Provenance Modules, and the Open Provenance Model.
Both data provenance and data lineage are useful for forming a comprehensive view of data. Let’s switch gears to understand data provenance vs. data lineage at a deeper level.
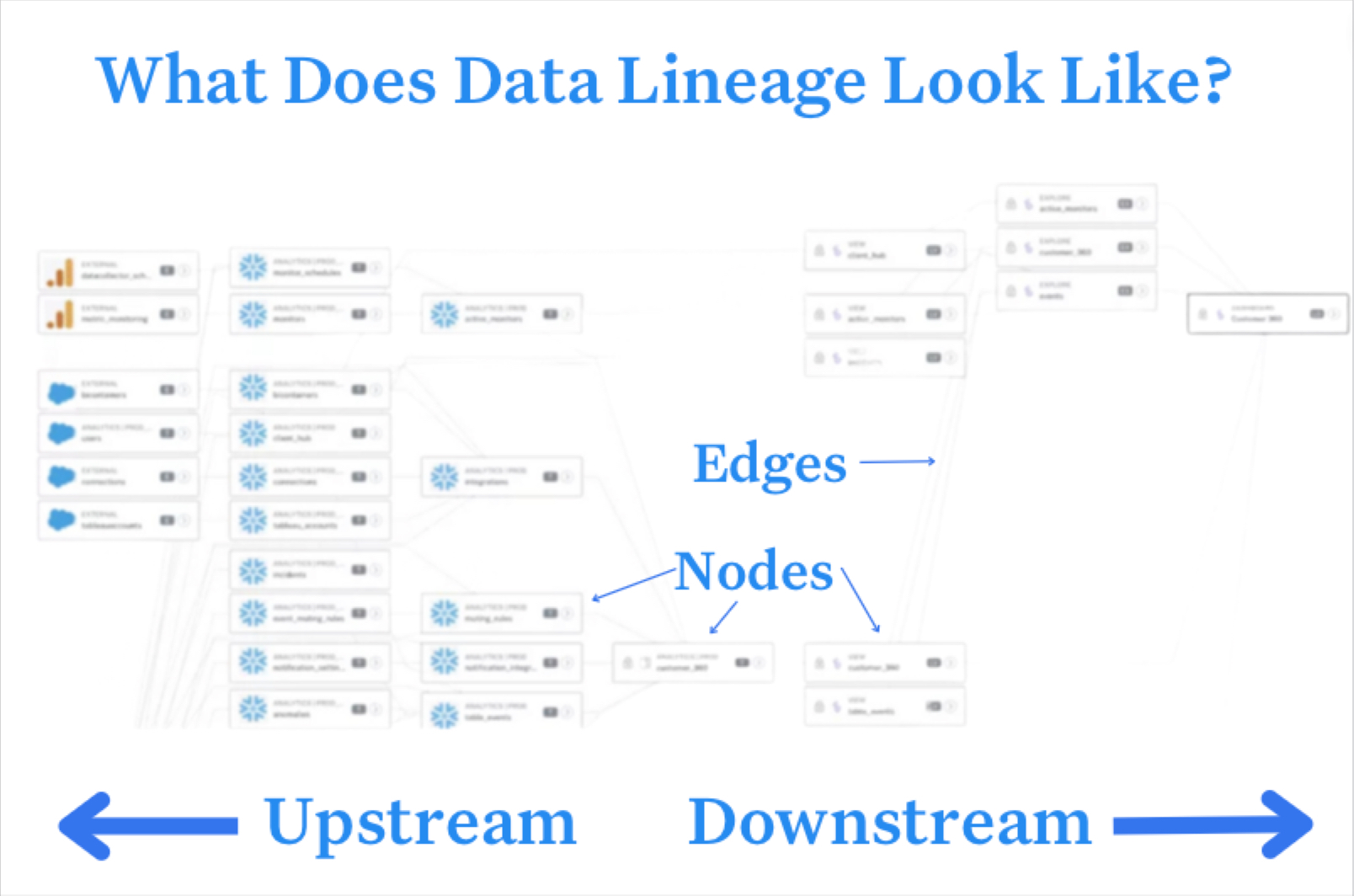
What is data lineage?
Data lineage tools track and map the movement of data through your pipeline, from ingestion to consumption. Compared to data provenance, data lineage is concerned with tracking the full lifecycle of data, including all of its changes over time.
There are several data lineage solutions available on the market, including OpenData, OpenLineage + Marquez, Egeria, Apache Atlas, Spline and more, and they’ve automated what used to be an extremely tedious and manual process. Data teams used to have to track their data assets all the way back to their ingestion sources, document those sources, and then map the entire path data took as it moved through its lifecycle. Imagine going back in time for every single piece of data that’s ever flowed through your pipelines – talk about a mystery!
While all data lineage solutions aren’t the same, they do typically all include a few important nodes, including the connectors that ingest the data, the tables in your data warehouse, lake, or lakehouse that store the data, and the analytical dashboards that visualize the data lineage.
Each of those nodes contains metadata about:
- Orchestration jobs
- Transformation models and SQL queries moving data
- Field profile (NULL %, min, max, etc)
- Recent users and changes they’ve made
- Users that access and consume data in dashboards
- Additional documentation
- Past data quality incidents
…just to name a few!
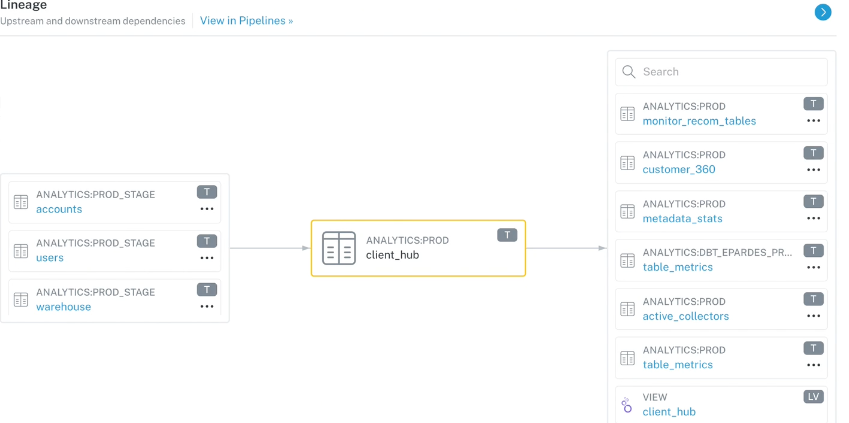
The importance of data lineage in data governance and pipeline management
Data lineage is extremely helpful when it comes to error tracking, accountability, and debugging of data and the systems that process it.
With new data regulations consistently on the horizon, data lineage can help support governance practices. For example, data lineage can enable a data team to provide all the information that might be required by GDPR or CCPA, like personally identifiable information (PII), or provide an audit trail of every user that’s ever accessed a certain set of data.
In addition, data lineage helps establish clear lines of accountability throughout your data architecture as your pipelines evolve. You can know who accessed the data at what point and when, and knowing where data came from and where it is in the pipeline can minimize potential impacts.
Data lineage use cases
Let’s dive into popular data lineage use cases. Data lineage is useful for:
- Improving data quality: The best way to fully understand the quality of your data is to understand everywhere it’s been. Without data lineage to validate the data and ensure its reliability, data can get messy and data teams are left making educated guesses on how or why their data set is the way it is. Rogue changes in schema, volume, and more can occur, worsening data quality and leading to downstream discrepancies. Data lineage can also help to simplify SQL queries by leading data teams to that exact data component they’re looking for.
- Data incident management and response: Data lineage can help a data team understand impact analysis and triage future incidents by understanding the blast radius of all data consumers downstream. Data lineage can surface the root cause of the incident throughout the pipeline, and then alert only the stakeholders that need to know, rather than notifying all users or business-facing consumers. Data lineage helps pinpoint incidents and, subsequently, reduce alert fatigue by narrowing down the location of the event for quicker time to resolution (TTR) – building data trust for your data team.
- Data access and enablement: Data lineage fosters data discovery for upstream users, like analysts reviewing sources for critical dashboards, so they can understand what fields populate the table and how the data had been transformed before arriving there. In addition, this added data access increases data democratization and collaboration, and makes it easier for business-facing users to know who owns which component of the data lifecycle.
- Data system modernization: Data lineage can help your organization scope a potential migration (for example: migration from a data warehouse to a lake or lakehouse or transitioning to a data mesh), to understand how you should group migration waves and prevent regressions and establish clear lines of ownership.
Data provenance vs. data lineage
So, let’s get down to the TL;DR. What’s the difference between data provenance vs. data lineage?
Here it is: Data provenance is concerned with just the historical record of the source of data, while data lineage is concerned with the full evolution of data throughout the pipeline, from the moment it’s ingested through every transformation.
While data provenance vs. data lineage are different in scope, they’re both extremely important to data management. A data engineering team can’t establish data lineage without understanding data provenance, and data provenance is not useful without the added context and understanding of data’s lifecycle that data lineage brings. We can liken it to a human: it’s impossible to become an adult without being a baby first, and knowing only that someone was once a baby and is now an adult, with no information or context about their life in between, gives an incomplete and frankly, useless, understanding of a person!
Successful data teams should employ both data lineage and data provenance to maximize data quality and maintain a comprehensive view of their data’s lifecycle.
Why data observability completes the data provenance vs. data lineage picture
If data lineage and data provenance aren’t handled correctly, there’s a strong chance they’ll be useless to your data organization (apart from adding a few colorful charts). Adding data lineage and data provenance solutions to a data observability platform, however, can do the opposite by providing end-to-end visibility.
Data observability can programmatically combine lineage and monitoring to support data incident detection, resolution, and prevention in a holistic way.
For example, mattress brand Resident was suffering from unreliable and missing data, leading to strained relationships between teams, especially between data engineering and BI and analytics, and the team was attempting to handle those issues manually. In the process of identifying where data was sourced from and its moments of transformation, data downtime was up and data trust was at an all time low.
So, rather than building out a custom system, Resident started using Monte Carlo’s data observability platform to handle real-time monitoring, alerting, and automated data lineage— providing a big map of data relationships she didn’t have before. With lineage, their team could identify concepts and troubleshoot them more effectively, leading to a 90% decrease in data issues.
Whether you’re currently focused on data provenance vs. data lineage or vice versa, both have clear benefits for data teams that are only made stronger within a data observability platform.
To learn more about how your team can restore data trust with data lineage as a part of your data observability strategy, talk to our team.
Our promise: we will show you the product.
Read more posts.