Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage End-to-End Data Observability and Our Rapidly Expanding Database Support


Michael Segner
Michael writes about data engineering, data quality, and data teams.

Will Robins
Will Robins is a member of the founding team at Monte Carlo.
If you’ve been keeping track of our integrations page you might have noticed Monte Carlo is adding support for different databases faster than a nested loop server crash.
At the start of 2023, we extended our data observability solution’s monitoring capabilities to popular transactional databases like Postgres, MySQL, and Microsoft MySQL Server. By the end of 2023, we added Azure SQL database to the list as well as enterprise databases such as Oracle DB, SAP HANA and Teradata.
Table of Contents
Supporting Multi-Database Architectures
We’ve been aggressively adding these integrations to better support complex data architectures. While a team’s data “center of gravity” or “source of truth” will often revolve around a data warehouse or lakehouse, their data platform will frequently consist of multiple databases.
There are several common reasons for this.
Data teams will incorporate a transactional database (OLTP) like Postgres or a service like AWS S3 to handle raw transactional data before syncing it with their warehouse/lakehouse that serves as the analytical platform (OLAP). Trying to run reports and analytics from a transactional database is just asking for trouble–they are best decoupled and synced.
Another frequent use-case, especially among larger enterprises, is that the organization is in the midst of a data warehouse migration and frequently syncing some or all of their data until they are fully unpacked in their new home.
With these and other similar scenarios, data teams want to know:
- If they got bad data from the source; or
- If problems resulted from moving data from a database to their source of truth.
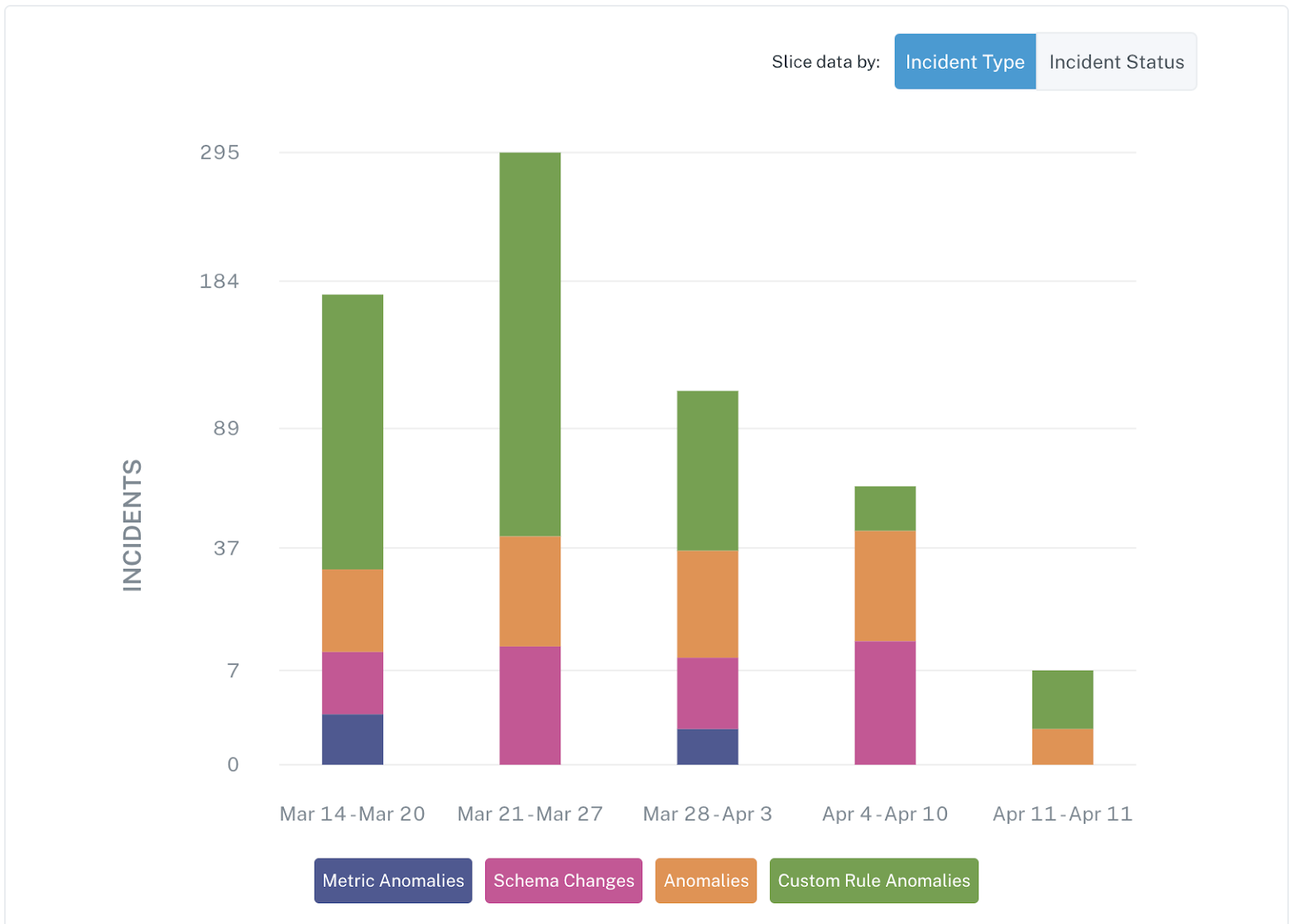
Using Monte Carlo, data teams can leverage machine learning driven monitors to identify data incidents (say for example a spike in NULL rate) within the data warehouse/lakehouse or create data tests with set thresholds within the transactional or enterprise database. End-to-end data lineage then helps trace these issues to their point of origin.
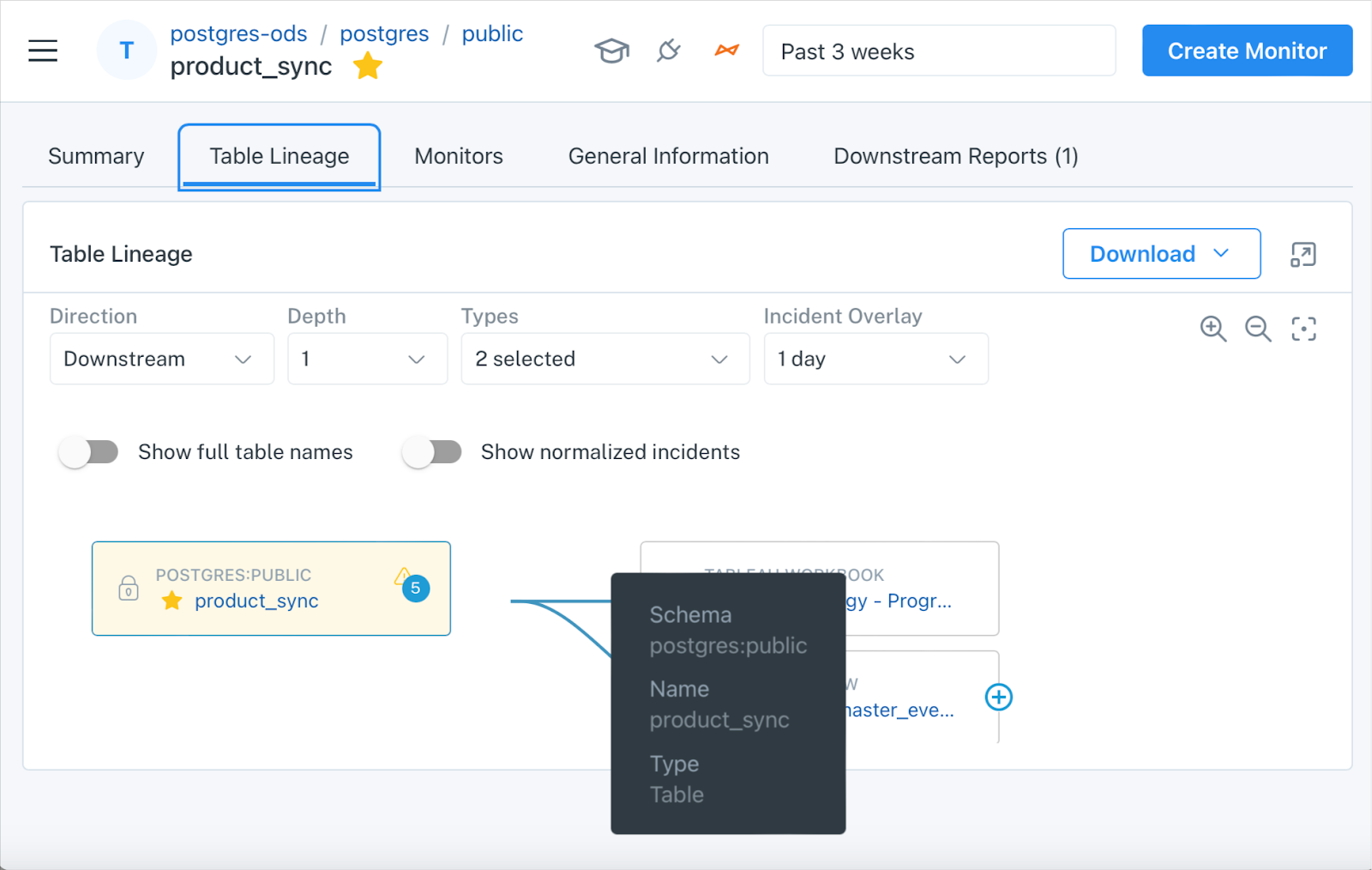
Monte Carlo has detected 5 incidents on this Postgres table upstream of a key Tableau report.
Monte Carlo also provides a flexible framework for creating cross database rules to ensure data consistency. These rules alert to instances where databases begin to drift apart in unexpected ways.
This could be the result of an orchestration issue where data was delayed, a schema change in the transactional database that didn’t align with a hardcoded pipeline, or one of many other possibilities. In any case, teams need to prevent multiple values for the same metric from propagating across the organization.
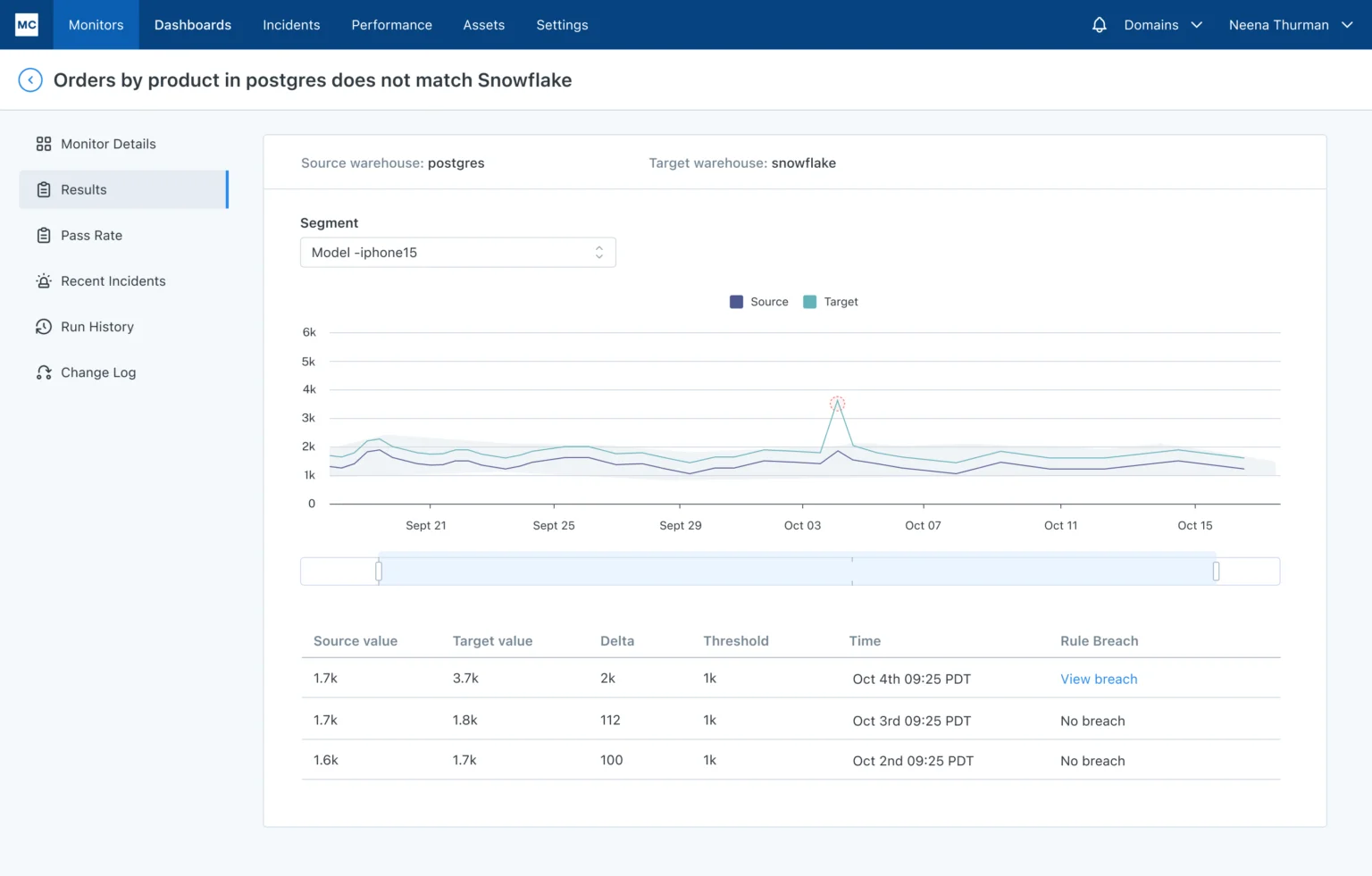
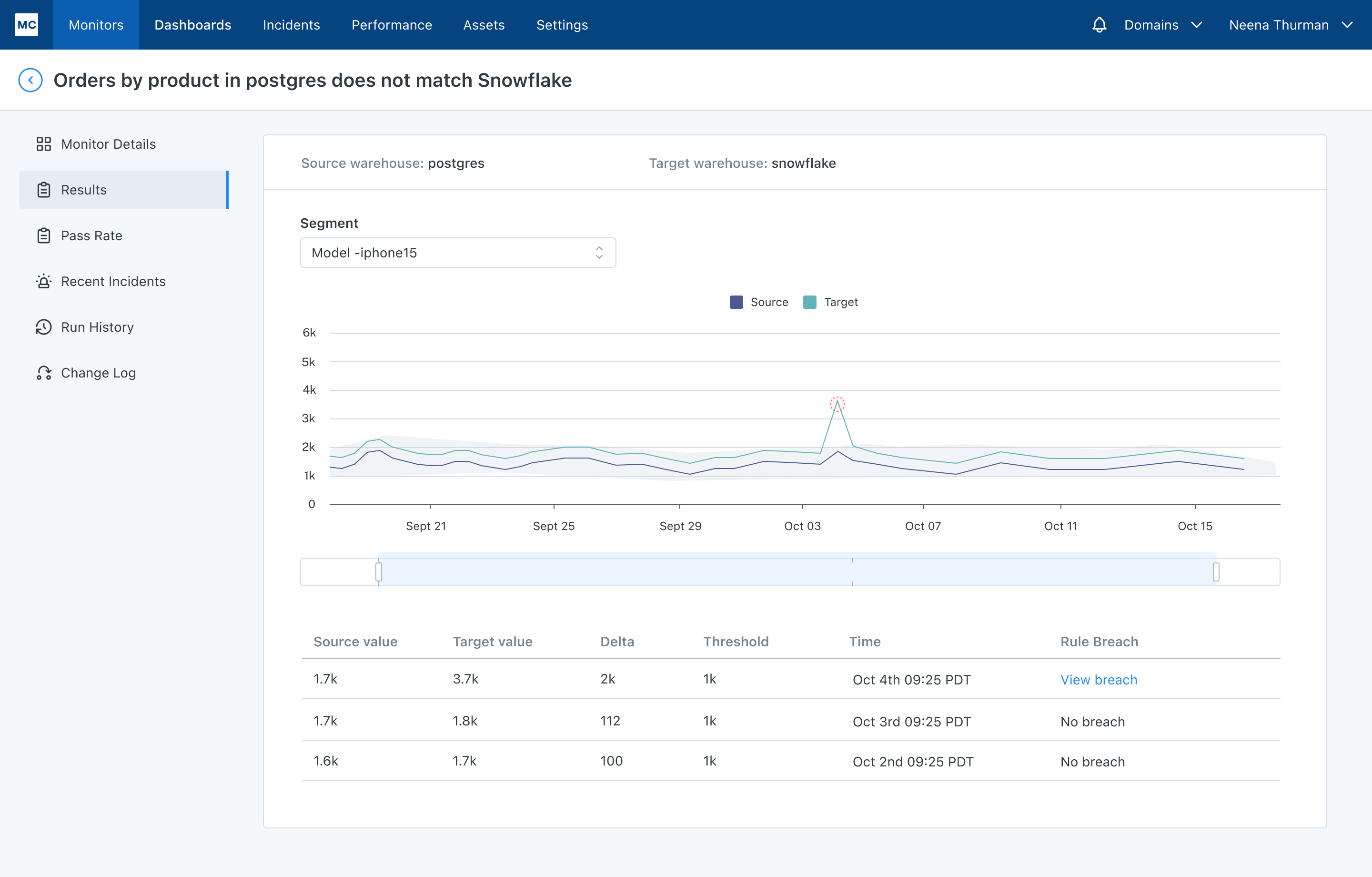
There is a discrepancy between the source (Postgres) and target (Snowflake) detected by a cross-database monitor or “comparison rule.”
Circuit breakers can also be created to stop bad data from entering the data warehouse or lakehouse in the first place.
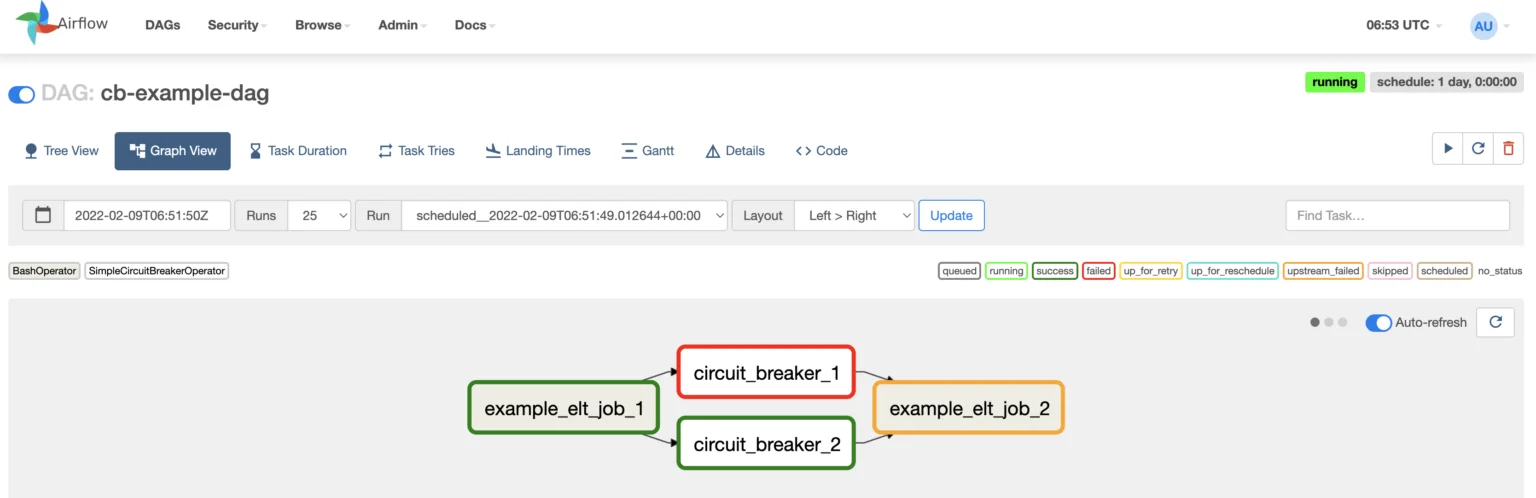
Keep An Eye On This Space
Monte Carlo will continue to prioritize helping data teams increase their data reliability by providing end-to-end visibility across their data and data systems.
If there is any prediction that can be made in the fast moving world of data engineering, it’s that you can expect to see more database support announcements coming soon.
Curious about how data observability can help make your data platform more reliable? Talk to us!
Our promise: we will show you the product.
Read more posts.