Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What’s Next for Data Engineering in 2023? 10 Predictions

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
What’s next for the future of data engineering? Each year, we chat with one of our industry’s pioneering leaders about their predictions for the modern data stack – and share a few of our own.
A few weeks ago, I had the opportunity to chat with famed venture capitalist, prolific blogger, and friend Tomasz Tunguz about his top 9 data engineering predictions for 2023. It looked like so much fun that I decided to grab my crystal ball and add a few suggestions to the mix.
Before we begin, however, it’s important to understand what exactly we mean by modern data stack:
- It’s cloud-based
- It’s modular and customizable
- It’s best-of-breed first (choosing the best tool for a specific job, versus an all-in-one solution)
- It’s metadata-driven
- It runs on SQL (at least for now)
With these basic concepts in mind, let’s dive into Tomasz’s predictions for the future of the modern data stack.
Pro-tip: be sure to check out his talk from IMPACT: The Data Observability Summit.
Prediction #1: Cloud Manages 75% Of All Data Workloads by 2024 (Tomasz)
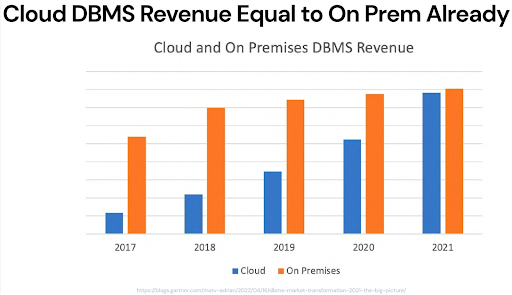
This was Tomasz’s first prediction, and based on an analyst report earlier this year showing the growth of cloud versus on-premises RDBMS revenue.
In 2017, cloud was about 20% of on-prem, and through the course of the last five years, the cloud has basically achieved equality in terms of revenue. If you project three or four years, given the growth rate we’re seeing here, about 75% of all those workloads will be migrating to the cloud.
The other observation he had was that on-prem spend has basically been flat throughout that period. That gives a lot of credence to the idea you can look at Snowflake’s revenues as a proxy for what’s happening in the larger data ecosystem.
Snowflake went from a hundred million in revenue to about 1.2 billion in four years, which underscores the terrific demand there is for cloud data warehouses.
Prediction #2: Data Engineering Teams Will Spend 30% More Time On FinOps / Data Cloud Cost Optimization (Barr)
My first prediction is a corollary to Tomasz’s prophecy on the rapid growth of data cloud spend. As more data workloads move to the cloud, I foresee that data will become a larger portion of a company’s spend and draw more scrutiny from finance.
It’s no secret that the macro economic environment is starting to transition from a period of rapid growth and revenue acquisition to a more restrained focus on optimizing operations and profitability. We’re seeing more financial officers play increasing roles in deals with data teams and it stands to reason this partnership will also include recurring costs as well.
Data teams will still need to primarily add value to the business by acting as a force multiplier on the efficiency of other teams and by increasing revenue through data monetization, but cost optimization will become an increasingly important third avenue.
This is an area where best practices are still very nascent as data engineering teams have focused on speed and agility to meet the extraordinary demands placed on them. Most of their time is spent writing new queries or piping in more data vs. optimizing heavy/deteriorating queries or deprecating unused tables.
Data cloud cost optimization is also in the best interest of the data warehouse and lakehouse vendors. Yes, of course they want consumption to increase, but waste creates churn. They would rather encourage increased consumption from advanced use cases like data applications that create customer value and therefore increased retention. They aren’t in this for the short-term.
That’s why you are seeing cost of ownership become a bigger part of the discussion, as it was in my conversation at a recent conference session with Databricks CEO Ali Ghodsi. You are also seeing all of the other major players–BigQuery, RedShift, Snowflake–highlight best practices and features around optimization.
This increase in time spent will likely come both from additional headcount, which will be more directly tied to ROI and more easily justified as hires come under increased scrutiny (a survey from the FinOps foundation forecasts an average growth of 5 to 7 FinOps dedicated employees). Time allocation will also likely shift within current members of the data team as they adopt more processes and technologies to become efficient in other areas like data reliability.
Prediction #3: Data Workloads Segment By Use (Tomasz)
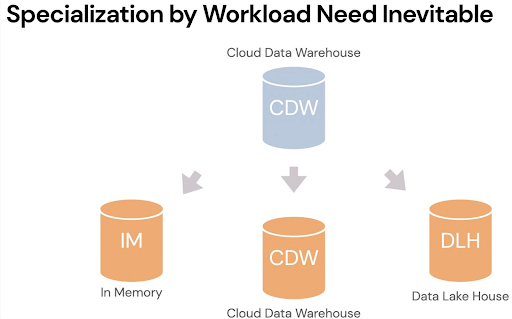
Tomasz’ second prediction focused on data teams emphasizing using the right tool for the right job, or perhaps the specialized tool for the specialized job.
The RBMS market has grown from about 36 billion to about 80 billion from 2017 to 2021, and most of those workloads have been centralized in cloud data warehouses. But now we’re starting to see segmentation.
Different workloads are going to need different kinds of databases. The way Tomasz sees it, today everything is running in a cloud data warehouse, but in the next few years there will be a group of workloads that are pushed into in-memory databases, particularly for smaller data sets. Keep in mind, the vast majority of cloud data workloads are probably less than a hundred gigabytes in size and something you could do on a particular machine in memory for higher performance.
Tomasz also predicts particularly large enterprises who have different needs for their data workloads may start to take jobs that don’t require low latency or the manipulation of significant volumes of data and actually move them to cloud data lakehouses.
Prediction #4: More Specialization Across the Data Team (Barr)
I agree with Tomasz’s prediction on the specialization of data workloads, but I don’t think it’s only the data warehouse that’s going to segment by use. I think we are going to start seeing more specialized roles across data teams as well.
Currently, data team roles are segmented primarily by data processing stage:
- Data engineers pipe the data in,
- Analytical engineers clean it up, and
- Data analysts/scientists visualize and glean insights from it.
These roles aren’t going anywhere, but I think there will be additional segmentation by business value or objective:
- Data reliability engineers will ensure data quality
- Data product managers will boost adoption and monetization
- DataOps engineers will focus on governance and efficiency
- Data architects will focus on removing silos and longer-term investments
This would mirror our sister field of software engineering where the title of software engineer started to split into subfields like DevOps engineer or site reliability engineer. It’s a natural evolution as professions start to mature and become more complex.
Prediction #5: Metrics Layers Unify Data Architectures (Tomasz)
Tomasz’s next prediction dealt with the ascendance of the metrics layer, also known as the semantics layer. This made a big splash at dbt’s Coalesce the last two years and it’s going to start transforming the way data pipelines and data operations look.
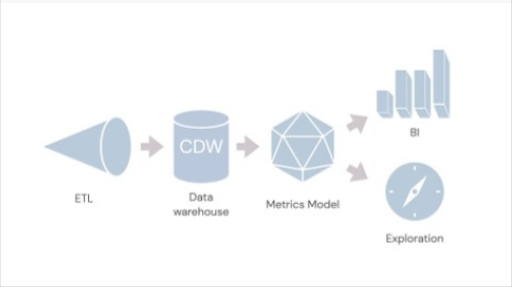
Today, the classic data pipeline has an ETL layer that’s taking data from different systems, and putting it into a cloud data warehouse. You’ve got a metrics layer in the middle that defines metrics like revenue once and then it’s used downstream in BI for consistent reporting and the entire company can use it. That’s the main value proposition of that metrics model. This technology and idea has existed for decades, but it’s really come to the fore quite recently.
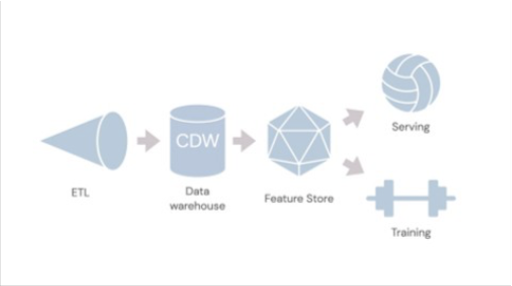
As Tomasz suggests, now companies require a machine learning stack, which looks very similar to the classic BI stack, but it’s actually built a lot of its own infrastructure separately. You still have the ETL that gets put into a cloud data warehouse, but now you’ve got a feature store, which is a database of the metrics that data scientists use in order to train machine learning models and ultimately serve them.
Still, if you look at those two architectures, they’re actually quite similar. And it’s not hard to see how the metrics layer and the feature store could come together and align these two data pipelines because both of them are defining metrics that are used downstream.
Ultimately, Tomasz argues, the logical conclusion is that a lot of the machine learning work today should move into the cloud data warehouse, or the database of choice, because those platforms are accustomed to serving very large query volumes with very high availability.
Prediction #6: Data Gets Meshier, But Central Data Platforms Remain (Barr)
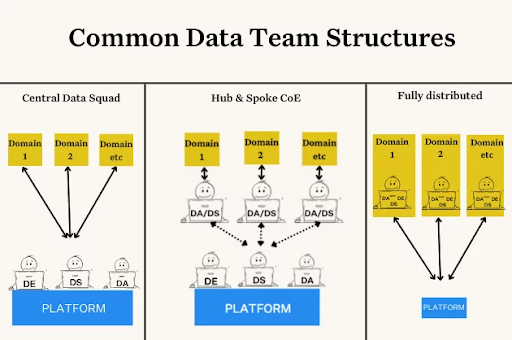
I agree with Tomasz. The metrics layer is promising indeed– data teams need a shared understanding and single source of truth especially as they move toward more decentralized, distributed structures, which is the heart of my next prediction.
Predicting data teams will continue to transition toward a data mesh as originally outlined by Zhamak Dehgani is not necessarily bold. Data mesh has been one of the hottest concepts among data teams for several years now.
However, I’ve seen more data teams making a pitstop on their journey that combines domain embedded teams and a center of excellence or platform team. For many teams this organizing principle gives them the best of both worlds: the agility and alignment of decentralized teams and the consistent standards of centralized teams.
I think some teams will continue on their data mesh journey and some will make this pitstop a permanent destination. They will adopt data mesh principles such as domain-first architectures, self-service, and treating data like a product–but they will retain a powerful central platform and data engineering SWAT team.
Prediction #7: Notebooks Win 20% of Excel Users With Data Apps (Tomasz)
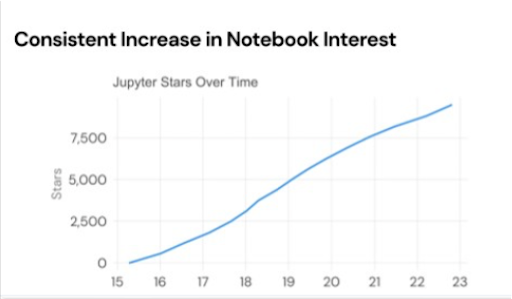
Tomasz’s next prediction derived from his conversation with a handful of data leaders from FORTUNE 500 companies a few years ago.
He asked them, “There are a billion users of Excel in the world, some of which are inside your company. What fraction of those Excel users write Python today and what will that percentage be in five years?”
The answer was 5% of people who use Excel today write Python, but in five years, it’ll be 50%. That’s a pretty fundamental change and it implies they’re going to be 250 million people looking for a next generation data analysis tool that does something like Excel, but in a superior way.
That tool could be the Jupyter notebook. It’s got all the advantages of code: it’s reproducible, you can check it in GitHub, and it’s really easy to share. It could become the dominant mechanism for replacing Excel for those more sophisticated users and use cases such as data apps.
A data engineer can take a notebook, write a bunch of code even across different languages, pull in different data sources, merge them together, build an application, and then publish this application to their end users.
That’s a really impressive and important trend. Instead of passing around an Excel spreadsheet, Tomasz suggests, people can build an application that looks and feels like a real SaaS application, but customized to their users.
Prediction #8: Most machine learning models (>51%) will successfully make it to production (Barr)
In the spirit of Tomasz’s notebook prediction, I believe we will see the average organization successfully deploy more machine learning models into production.
If you attended any tech conferences in 2022, you might think we are all living in ML nirvana; after all, the successful projects are often impactful and fun to highlight. But that obscures the fact that most ML projects fail before they ever see the light of day.
In October 2020, Gartner reported that only 53% of ML projects make it from prototype to production—and that’s at organizations with some level of AI experience. For companies still working to develop a data-driven culture, that number is likely far higher, with some failure-rate estimates soaring to 80% or more.
There are a lot of challenges including
- Misalignment between business needs and machine learning objectives,
- Machine learning training that doesn’t generalize,
- Testing and validation issues, and
- Deployment and serving hurdles.
The reason why I think the tide starts to turn for ML engineering teams is the combination of increased focus on data quality and the economic pressure to make ML more usable (of which more approachable interfaces like notebooks or data apps like Steamlit play a big part).
Prediction #9: “Cloud-Prem” Becomes The Norm (Tomasz)
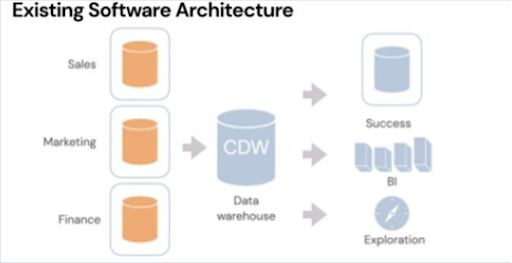
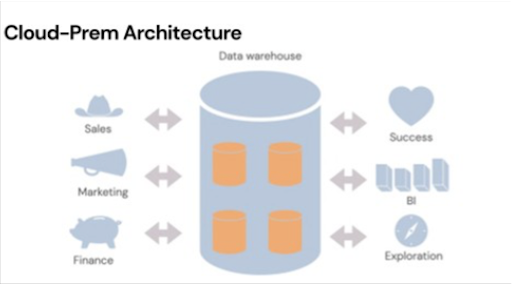
Tomasz’s next prediction addressed the closing chasm between different data infrastructures and consumers similar to his metrics layer prediction.
The old architecture for data movement was an organization that might have, in the case of the image above, three different pieces of software. The CRM for sales, a CDP for marketing, and then the finance database. The data within these databases likely overlap.
What you would see in the old architecture (still very prevalent today) is you take all that data, you pump it into the data warehouse, and then you pump it back out to enrich other products like a customer success product.
The next generation of architecture is going to be a read and write cloud data warehouse where the sales database, the marketing database, the finance database, and the customer success information, they’re all stored on a cloud data warehouse with a bi-directional sync (leveraging Reverse ETL) across them.
There are a couple of different advantages to this architecture. The first is it’s actually a go to market advantage. If a big cloud data warehouse contains data from a big bank, they’ve gone through the information security process in order to get the approval to manipulate that information, the SaaS applications built on top of that cloud data warehouse only need to get permissions to that data–you no longer need to go through the information security process, which makes your sales cycles significantly faster.
The other main benefit as a software provider, Tomasz suggests, is that you’re going to be able to use and join information across those data sets. This is likely an inexorable trend that’s probably going to continue for at least the next 10 to 15 years.
Prediction #10: Data contracts move to early stage adoption (Barr)
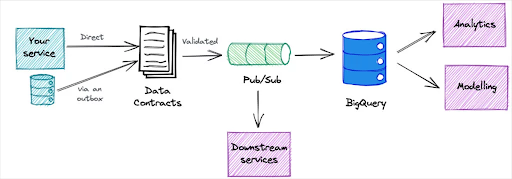
Anyone who follows data discussions on LinkedIn knows that data contracts have been among the most discussed topics of the year. There’s a reason why: they address one of the largest data quality issues data teams face.
Unexpected schema changes account for a large portion of data quality issues. More often than not, they are the result of an unwitting software engineer who has pushed an update to a service not knowing they are creating havoc in the data systems downstream.
However it’s important to note that given all the online chatter, data contracts are still very much in their infancy. The pioneers of this process–people like Chad Sanderson and Andrew Jones–have shown how it can move from concept to practice, but they are also very straight forward that it’s still a work in progress at their respective organizations.
I predict the energy and importance of this topic will accelerate its implementation from pioneers to early stage adopters in 2023. This will set the stage for what will be an inflection point in 2024 where it starts to cross the chasm into a mainstream best practice or begins to fade away.
+++
Let us know what you think of our predictions. Anything we missed?
Tomasz frequently shares his observations on his blog and on LinkedIn – be sure to follow him to stay informed!
And if you’re curious about how these trends (data contracts, centralized data platforms, data team structure, oh my!) will play out, be sure to bookmark the Data Downtime Blog. More to come.
Talk to us about data observability! Schedule a time using the form below.
Our promise: we will show you the product.
Read more posts.