Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Curation Explained: How To Make Data More Valuable


Michael Segner
Michael writes about data engineering, data quality, and data teams.
What is data curation?
Data curation is the process of transforming and enriching larger amounts of raw data into smaller, more widely accessible subsets of data that provide additional value to the organization or the intended use case. This process includes managing the data quality, metadata, retention, semantics (meaning/purpose), access, operability, schema, and more.
Typically, there are different stages of data curation each of which has a specific technical architecture designed for a specific type of user based on their role and technical acumen (more on that later).
To use an analogy, if your company was charged with making ice cream sundaes you might:
- Provide all pastry chefs access to the refrigerator and let them select which raw ingredients to use to make the ice cream;
- Provide sundae experts self-service access to scoop their own ice cream at the counter and apply the toppings they prefer, this may require good documentation of the ingredients used;
- Provide less frequent sundae consumers the fully made sundae designed to their specifications at their table.
As you can see, the product typically becomes more refined and accessible as you progress through each stage in the curation process.
In This Article:
The benefits of data curation (and the cost)
Data curation is all about efficiency, both the perspective of the data engineer as well as the perspective of the data consumer.
Think about it–building highly customized pipelines and data products for every single ad-hoc request would involve a considerable amount of redundant re-work. The same raw data would go through the same enrichment and transformation steps consuming excess compute and time.
It would also make the data engineering team a bottleneck. For most organizations, there needs to be some level of data self-service.
On the other hand, providing wide access to raw data would be a disaster. All but the most technical and data savvy users would quickly become overwhelmed and unable to find what they need. Without a strong knowledge of the source systems or consistent layer of business logic, its likely mistakes would be made or the same metric would be calculated six different ways.
Multiple data curation stages allows for the “goldilocks zone” where just the right amount of transformation, organization, and enrichment has taken place, so the organization can take advantage of a “build once use many times” approach for the majority of its use cases.
The other benefit of data curation is to allow for the data team to experiment. There is a reason most restaurants don’t have the kitchen on display, the cooking, or in our case the development process, can get messy. It’s a good idea to hide this complexity from most stakeholders and isolate it in a staging area to ensure there are no negative impacts to production systems.
Of course, there is no such thing as a free lunch. Every additional layer of data curation adds exponential cost. One of the most critical data curation exercises for data leaders is to prioritize high-touch efforts on the most valuable opportunities and ensure data is only as curated as it needs to be for each use case.
Data curation example architectures
There is no right data curation architecture, only what is right for your organization. Here are some example architectures.
Staging and production
Almost all data teams have separate virtual data warehouses or environments to differentiate between staging and production. For smaller organizations, this may be the only level of data curation. Raw data lands in staging and is only promoted to production once it has met certain standards and requirements.
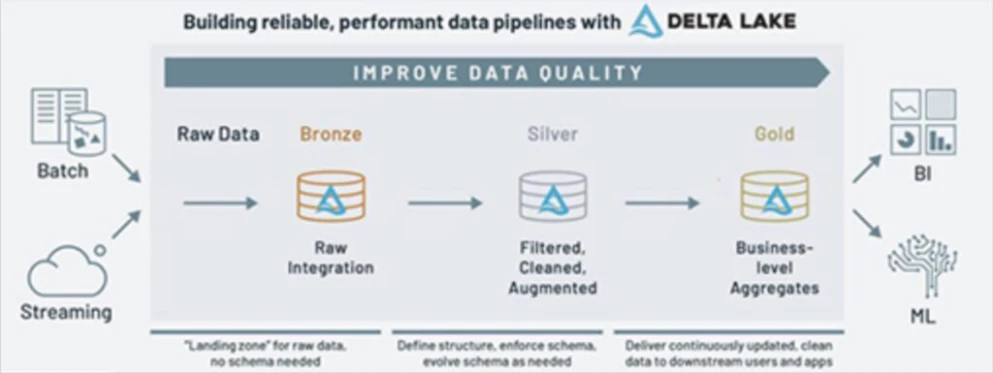
Medallion architecture
This type of data design architecture was popularized by Databricks for the lakehouse and features three distinct layers. Bronze is the landing zone where data is in its rawest state. This layer is ideal for understanding the historical archive of source data, which can be important for audits, and to reprocess as needed. Silver is the filtered, cleaned, and augmented layer and is designed for self-service analytics. Gold is the data that is ready to be consumed by the intended use case. For example, data that is ready to feed a machine learning application or that has been aggregated into the metrics required for an executive dashboard.
Data certification
Similar to Medallion architecture, some data teams will leverage a data certification strategy that involves categorizing datasets by their reliability and other key SLAs. For example, tier one datasets will have less data downtime than tier two datasets. This allows the data team to prioritize while still addressing ad-hoc requests as needed. It also helps set expectations and build trust with data consumers. Read how Red Ventures uses data SLAs in a similar manner.
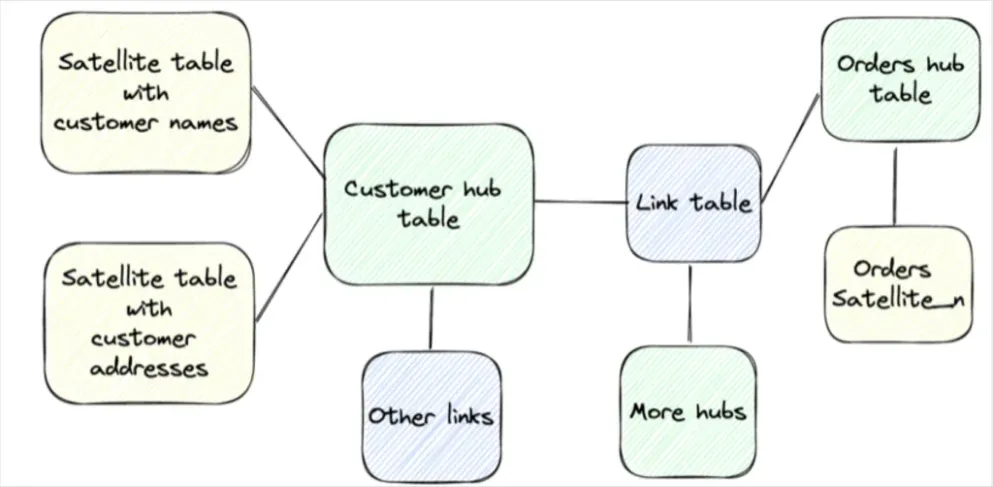
Data modeling
While medallion architecture and data certification can help data consumers quickly understand if a data asset meets their requirements, it doesn’t necessarily make that data warehouse or lakehouse easy to navigate or understand. Some data teams will further curate their data so that it models the business, or in other words it is organized in a way that tells the story of the business through data. Popular data models include Kimball, Immon, and Data Vault. While this does create a source of truth and improves usability, it does come at a cost. Some have advocated for a One Big Table architecture as a means of addressing these concerns.
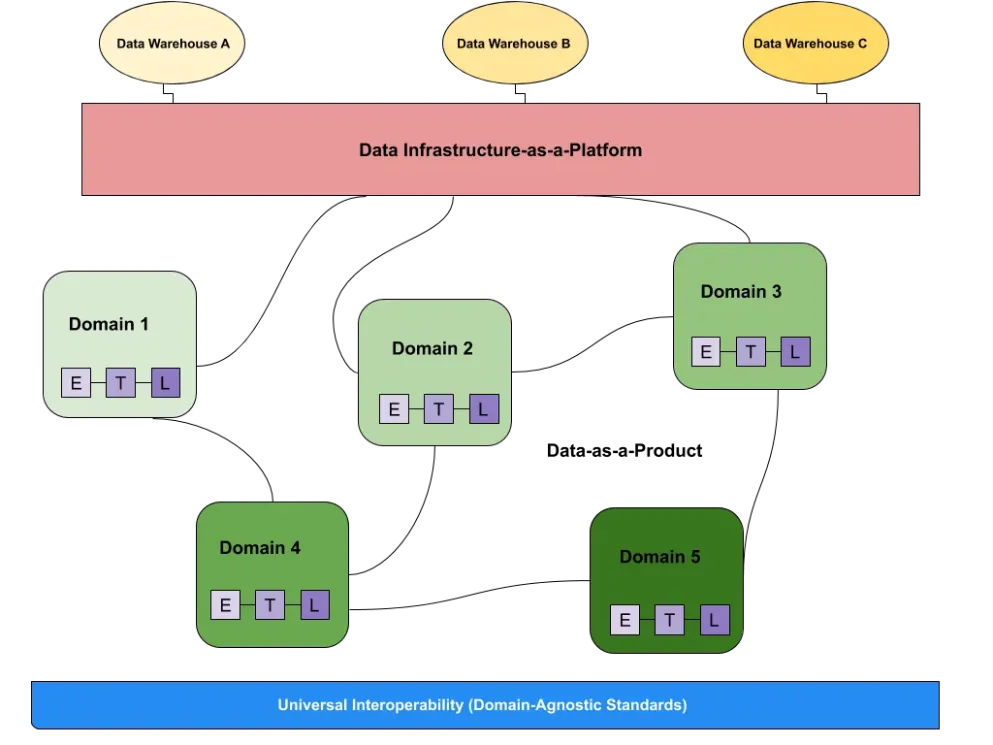
Data mesh
While some purists may yell at me and say that data mesh is a socio-technical approach to data design rather than a data curation architecture, I say that’s a bit like arguing over how to pronounce tomato.
At its core, data mesh applies a decentralized, data-driven approach to building data products as the main data curated asset. In other words, rather than model a source of truth, each data team corresponding to a specific purpose or business unit will develop their own data products that can be leveraged by others.
While each data product may have different governance standards as appropriate, each must be: discoverable, understandable, addressable, secure, interoperable, trustworth, natively accessible, and valuable on its own.
Data curation best practices
Create feedback loops
Asynchronous communication and feedback loops are essential for self-service analytics and improving the data curation process. This was one of the keys to how director of data and analytics, Priya Gupta, created data culture at hypergrowth startup Cribl. She said:
“Our data team errs on the side of overcommunication, and we try to communicate across as many channels as possible. Just like we as data engineers look askance at a data source that isn’t well documented, business users are going to be inherently skeptical towards quiet data teams.
Chat applications like Slack or Teams are very helpful in this regard. We create a centralized channel for all requests, which serves two purposes. It gives the entire analytics team visibility into requests, and it allows for other stakeholders to see what their peers are interested in.
The most satisfying thing you’ll ever see is when someone makes a request in your public Slack channel and then another stakeholder answers the question that was meant for you.”
Have clear lines of ownership
When there are multiple stages in the data curation process ownership can become blurry. Be sure each member of the data team understands which domains/teams and which aspects of the data curation process they are accountable for.
Track data adoption
If your data or data products aren’t widely used, poor data curation could be to blame. Talk to your different types of data consumers to better understand their use cases and how they would like to leverage data at each stage.
Focus on strong documentation
No one likes to document data assets, but data discovery suffers when there is a lack of documentation. People can’t use data they can’t find. One solution is to track how many of your key assets are documented in a way that fits your data consumer’s requirements.
Understand product/market fit
Each data curation stage should have a specific kind of data consumer in mind and be built with a consideration for how they like to consume data. An analytics engineer probably prefers to have access to your data warehouse or lakehouse directly and will likely be using dbt or some other low-code transformation tool as their primary interface while a business user will likely prefer dashboards.
Least privileged access
When curating data, it’s important to understand where your sensitive information and PII lives and ensure access is only given to those who need it. Otherwise you risk costly regulatory fines.
Defensible disposal
Data teams tend to be better at creating data assets than disposing of them. Part of the reason is the communication chasm between data producers and consumers. This inclination to data hoard is costly. Data loses its value quickly. Older assets should be retired and moved to cold storage or deleted if they are not required to be retained by law.
Automation
The overwhelming volume, velocity, and variety of data in the big data era requires significant automation, toil, and ruthless prioritization to make it a valuable resource for an organization. Automate where possible. For example, data catalogs can help automate data discovery, data access management platforms can automate privilege management, data observability can automate data quality and provide data lineage.
Avoid the tragedy of the commons
Create guardrails and enforce policies in your shared data environments. Without them, your beautifully curated data warehouse can slowly turn into a data swamp.
Data curation roles
While every organization organizes their data team slightly differently (and in smaller organizations it might all be done by one person), most teams feature common roles that emphasize different parts in the data curation process.
The most common would be:
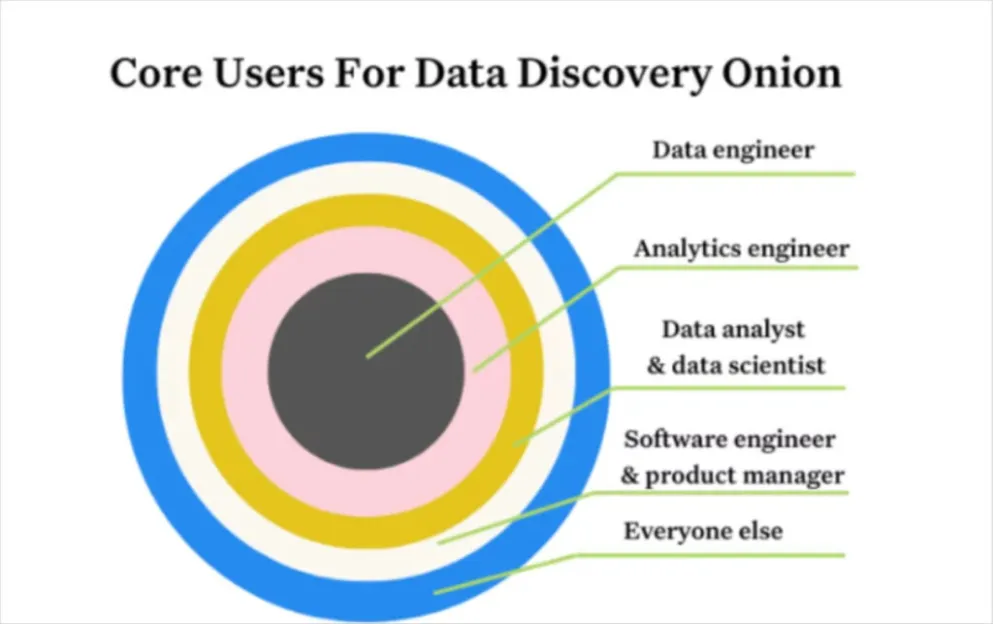
- Data engineers: Focus on building pipelines that bring raw data (perhaps with some light cleaning and normalization) from the source into the target system.
- Analytic engineers: Focus on transforming and aggregating this raw data into meaningful metrics and features.
- Data analysts and data scientists: Take these refined metrics and features to build their analytical dashboards and machine learning or AI models that are then often consumed by internal business users or even external customers.
Oftentimes there are further specialized roles within the data team that work to further enrich the data:
- Data reliability engineers or data quality analysts: Focus on ensuring data quality meets the needs of consumers. (This also frequently falls to the engineering team).
- Data stewards or data governance specialists: Focus on ensuring data is documented, cataloged, and discoverable.
- Records managers: Focus on ensuring proper data retention.
- Security and privacy officers: Focus on access management and data compliance.
- Data product managers: Focus on adding business value and usability.
Think of data as a product and act accordingly
The most important data curation best practice is to consider data-as-a-product. By designing for and incorporating feedback from your data consumers, you will efficiently deliver valuable data that is eagerly adopted.
Wondering how to improve data quality as part of your data curation process? Talk to us!
Our promise: we will show you the product.
Read more posts.